
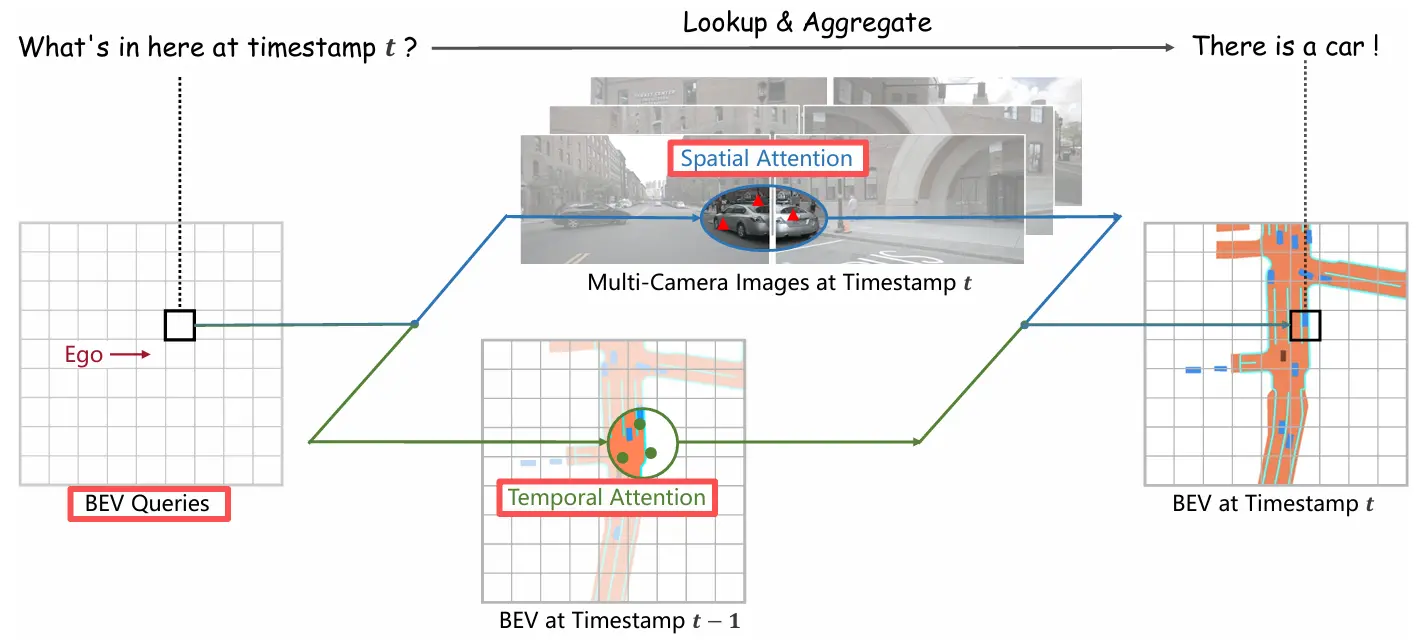
【重读经典】BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
先看论文题目 Multi-Camera:多相机纯视觉方案,Camera-based的mAP天然比LiDAR-based和Fusion-based的要低 Spatiotemporal:时间空间 Transformer:用到了Transformer架构以及Attention机制 创新点 论文摆脱了之前L

nuscenes-devkit的使用
nuScenes数据集说明 - FunnyWii's Zone 一文了解nuScenes数据集的结构。 我们使用nuscenes-devkit进一步学习数据集的使用。 安装非常简单,建议python版本3.12和3.9。 pip install nuscenes-devkit devkit使用 仍以

nuScenes数据集说明
nuScenes数据集包含6个Camera,1个LiDAR,5个Radar,1个GPS以及IMU。 数据量比KITTI大得多,所以目前Occ Networks更多使用nuScenes数据集。 数据集分成两大块:Full和Mini。 Full Dataset包含140万Camera图像,39万LiDA

Ubuntu22部署FlashOcc踩坑实录
环境配置 conda create --name FlashOcc python=3.8.5
conda activate FlashOcc
pip install torch==1.10.0+cu111 torchvision==0.11.0+cu111 torchaudio==0.10.0 -f
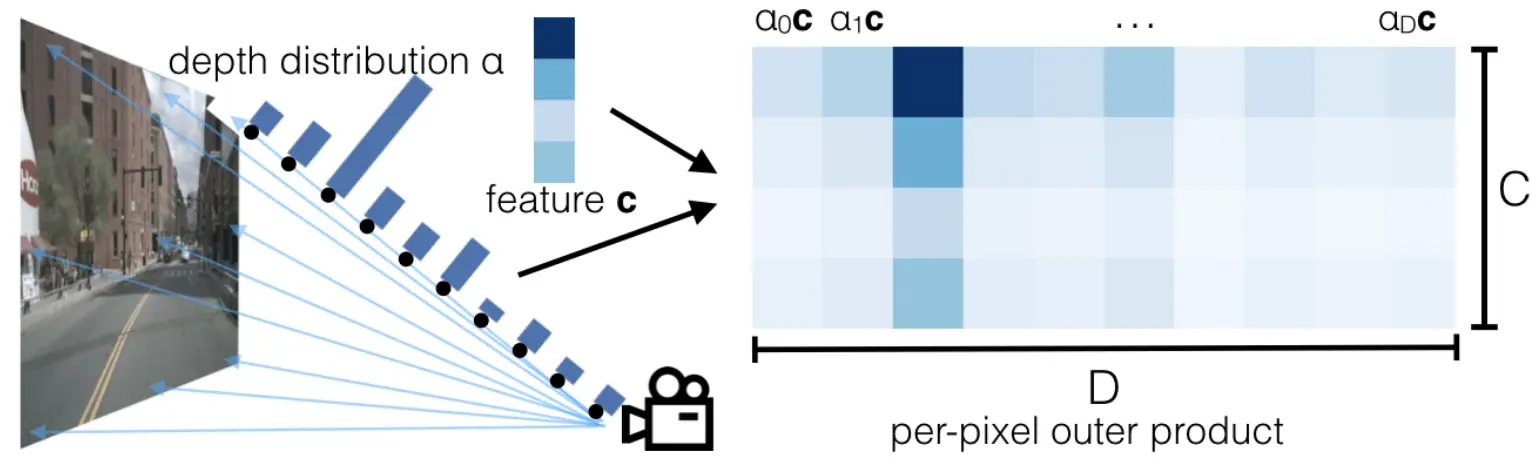
【重读经典】Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
LSS 是 NVIDIA 在 ECCV2020 上发表的文章。 关于论文标题中 Lift, Splat, Shoot 三个单词的理解,这三个单词对应模型中三个核心步骤。 Lift:提升。2D 图像特征提升到 3D 视锥空间特征。 Splat:泼溅。所有相机生成的 3D 视锥特征,泼洒到统一的 BEV

【重读经典】3D Bounding Box Estimation Using Deep Learning and Geometry
Deep3DBox 是一篇比较早的使用单目相机进行3D目标检测和姿态估计的方法。 Deep3DBox 先用 CNN 回归目标的方向和尺寸,因为这两类属性稳定性比较高。然后结合 2D BBOX 的几何约束求解平移量,以生成完整的 3D BBOX。 有些方法基于 PnP,通过 2D-3D 关键点对应关系

Ubuntu22.04部署Wan2.2
系统环境 系统:Ubuntu 22.04 显卡:RTX5880 48G 内存:64G PyTorch:2.4.0+ 模型说明 阿里巴巴旗下Wan团队开源的。 包括以下核心模型:
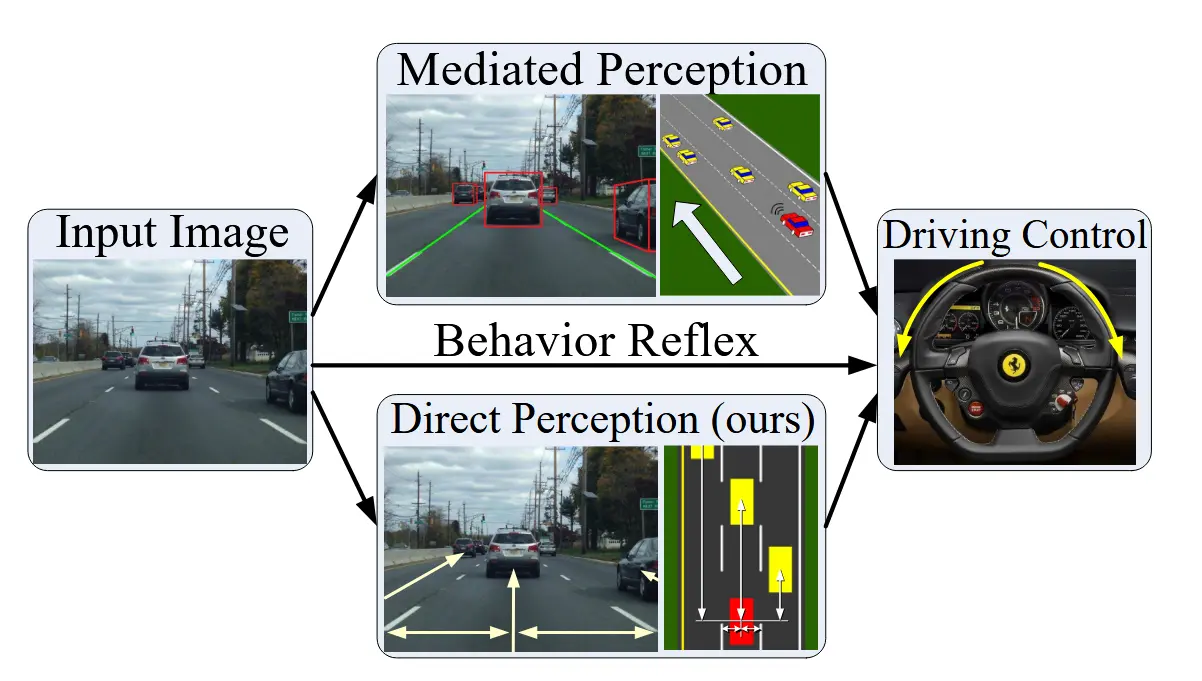
【重读经典】DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving
标题中的 Affordance 一词,本意是”预设用途,功能特性“,最初在知觉心理学和设计学领域出现。 后来在人机交互领域,Affordance 的含义变成了:一个产品让用户自然领悟到用法的能力。 在机器人领域(自动驾驶和机器人的感知不分家),被引申为可以执行的潜在动作,即在特定情况下哪些动作是可执

深度学习 - 网络的优化 Optimisation for Training Deep Networks
深度学习问题需要一个损失函数,我们的目标就是通过优化算法来最小化损失,即最小化目标(损失)函数。 需要注意的是,优化和深度学习的本质目标有差异:优化关注的是最小(最大)化目标函数,深度学习更关注模型的泛化能力。比如说,训练阶段的目标是最小化训练误差,但深度学习真正关心的是减小泛化误差,也就是推理阶段
