


【论文阅读】Stereo Anything
Stereo Match 立体匹配是 3D 视觉的基石,目的是通过图像间的像素级对应关系来恢复深度信息。 在零样本和少样本的情况下,深度神经网络在部署阶段会出现明显的性能下降,因为我们不可能 Annotate Anything。 Stereo Anything:基于大规模混合数据的统一零样本立体匹配


Orin AGX使用NVME的SSD刷机
重新安装系统 本文档使用命令行方式刷机。 官方教程地址: Quick Start — NVIDIA Jetson Linux Developer Guide 刷机工具下载地址,L4T 版本为 36.4.4,需下载 Driver Package (BSP)和 Sample Root Filesyste

【重读经典】YOLO的进化之路(下)
YOLOv9 和 YOLOv4/v7 一脉相承的作品,但是 Anchor-Free。 PGI 可编程梯度信息 全称 Programmable Gradient Information,这是一个辅助监督框架,目的是解决深度网络逐层传播的信息损失问题。 PGI 包含 3 个主要组件:主分支,辅助可逆分支

【重读经典】YOLO的进化之路(中)
没想到 YOLOv1 到 YOLOv4 就已经写了快 20000 字…… 编辑页面卡的不行,我不得不分几篇写完。YOLOv1 到 YOLO 26一共 12 篇,正好分上中下三篇。 YOLOv5 重量级来了,Ultralytics 闪亮登场了。第一个没有论文的 YOLO 正式版本,但它成为了工业界的事

【重读经典】YOLO的进化之路(上)
自 2016 年 YOLOv1 发布至今的十年里,YOLO 的核心版本已一路演进到了 v26——不过这其中包含了一次版本大跳跃:官方为了统一命名规范,直接跳过了 v13 到 v25。 回想起我使用 YOLO 的历程:从只会用官方的 COCO 数据集训练,到使用 MMLab 的各种训练框架,再到自己修

【重读经典】极坐标BEV方法
极坐标BEV的表示方法:在BEV空间按照角度和半径两个维度进行划分,而非笛卡尔坐标系下的均匀矩形网格。自车近处高分辨率,远处低分辨率,契合相机近大远小的成像特点。 核心优势 非均匀网格划分&分辨率优化 极坐标BEV以ego为中心,角度方向采用固定步长划分,径向长尾分布不均匀划分。 角度划分:θ ∈

3D稀疏卷积 3D Sparse Convolution
点云数据体素化后,有90%+的Voxel是空的,如果像VoxelNet那样直接使用3D Conv,计算量太大。 左图是稀疏的2D Tensor,深灰色像素都是0,浅灰色是non-zero点。 右图是稀疏的3D Tensor,只有红色的体素才是non-zero。 因此提出了3D稀疏卷积——3D Spa
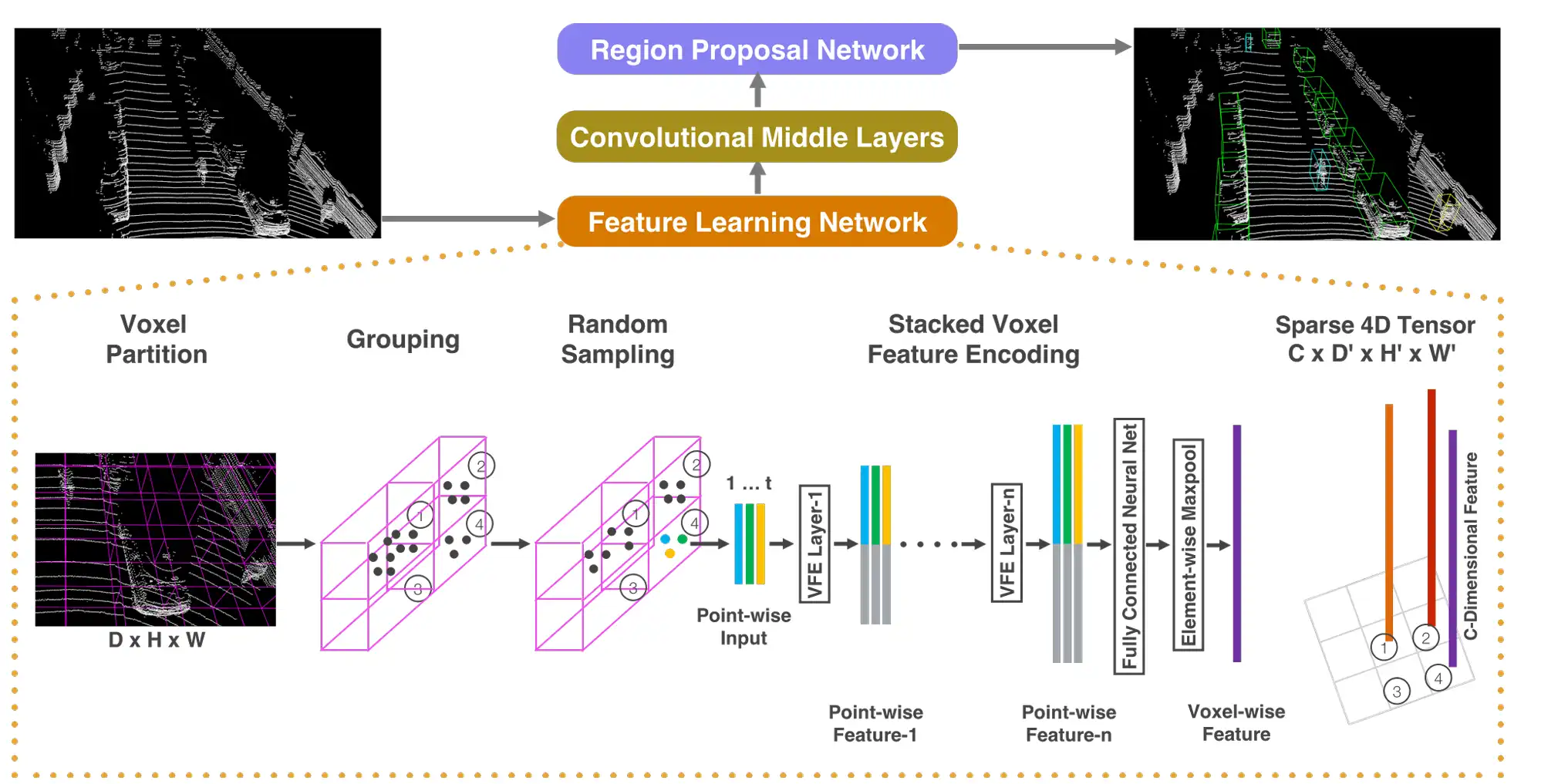
【重读经典】点云深度学习网络的范式变迁:PointNet, VoxelNet和PointPillars
PointNet 直接以 N×3N \times 3的Raw PointCloud作为输入,每个点使用 (x,
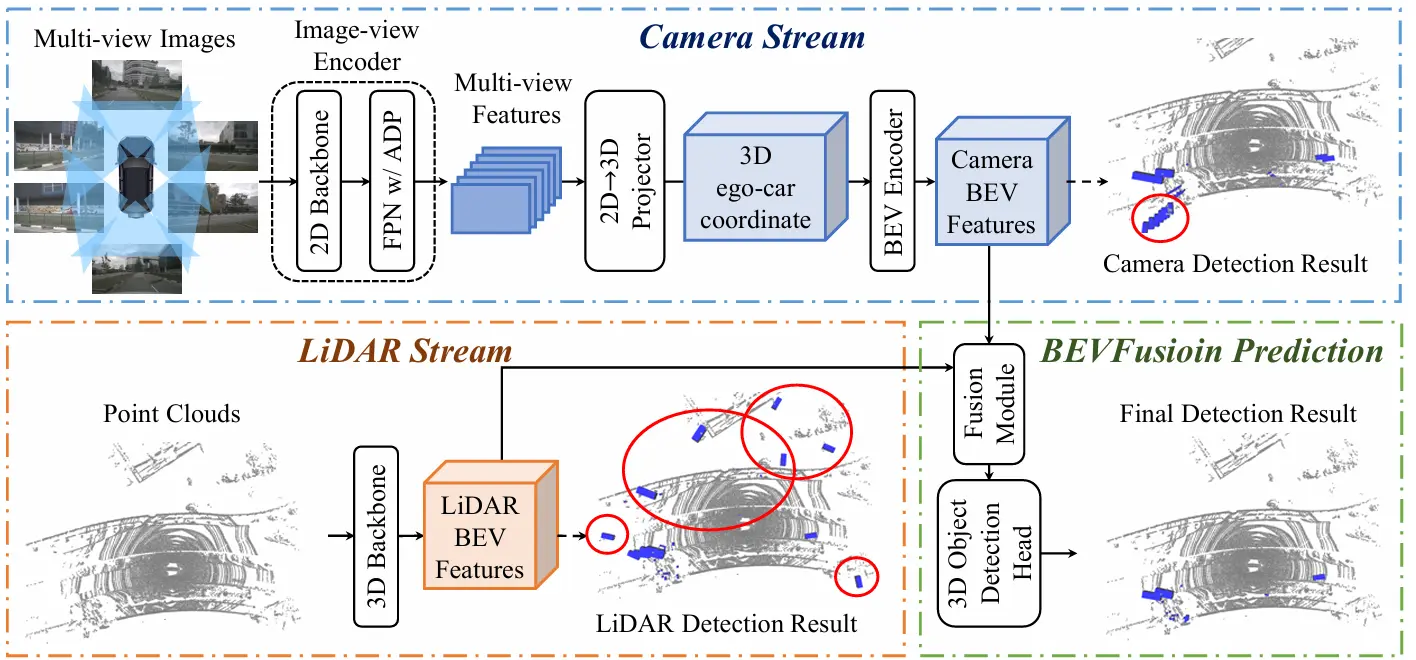
【重读经典】BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework
BEVFusion有两篇论文: 一篇名为《BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework》,发表于2022年。 另一篇名为《BEVFusion: Multi-Task Multi-Sensor Fusion with Unif
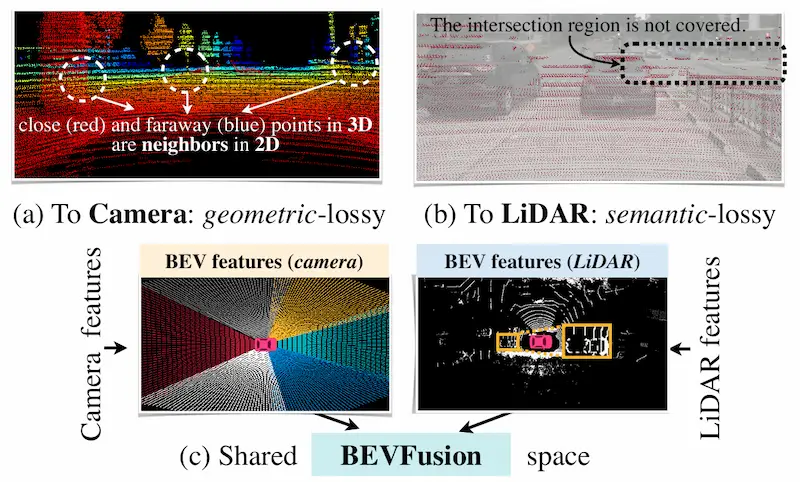
【重读经典】BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation
自动驾驶常见传感器包括 Camera,LiDAR,Radar 等传感器。 相机能提供丰富语义,LiDAR 提供准确的空间信息,雷达能进行速度估计。 对于多传感器方案,当时的传感器投影存在信息损失的问题: LiDAR->Cam:存在几何损失,像素坐标系中相邻的像素点,在 3D 空间中可能距离很远。设想
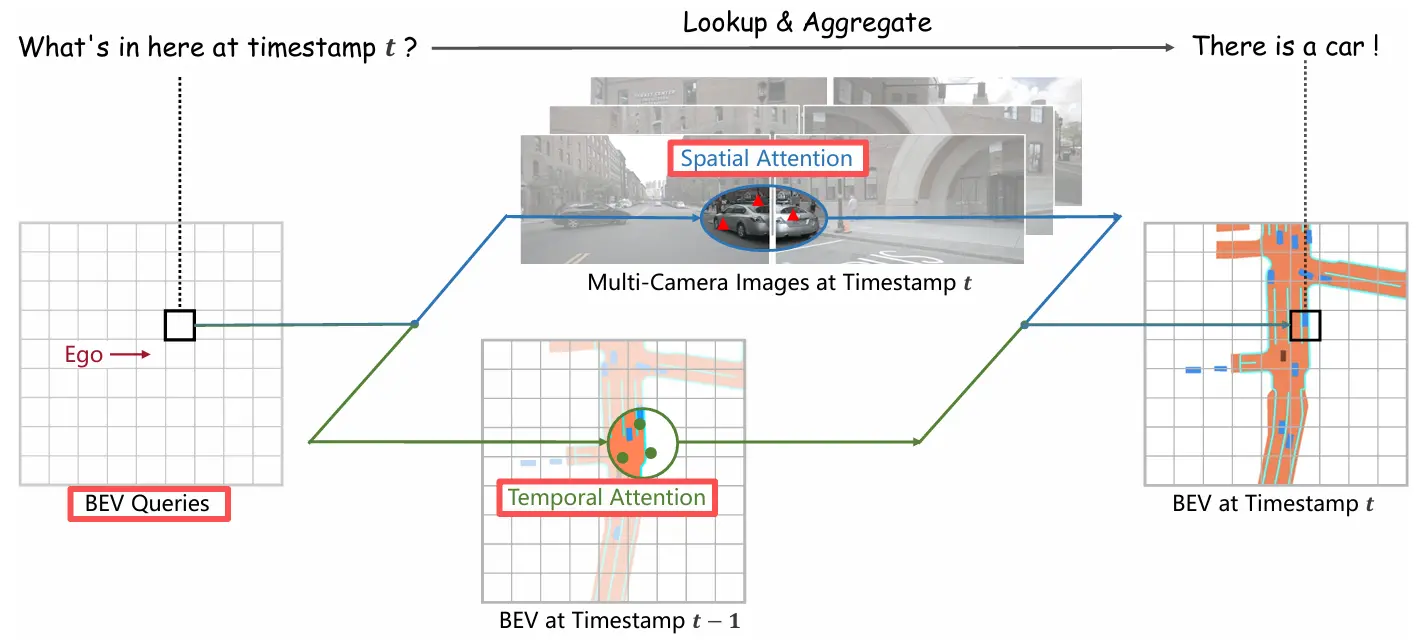
【重读经典】BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
先看论文题目 Multi-Camera:多相机纯视觉方案,Camera-based的mAP天然比LiDAR-based和Fusion-based的要低 Spatiotemporal:时间空间 Transformer:用到了Transformer架构以及Attention机制 创新点 论文摆脱了之前L

nuscenes-devkit的使用
nuScenes数据集说明 - FunnyWii's Zone 一文了解nuScenes数据集的结构。 我们使用nuscenes-devkit进一步学习数据集的使用。 安装非常简单,建议python版本3.12和3.9。 pip install nuscenes-devkit devkit使用 仍以