

多传感器融合的方案可以分成前融合(Early Fusion)方案和后融合(Late Fusion)方案。
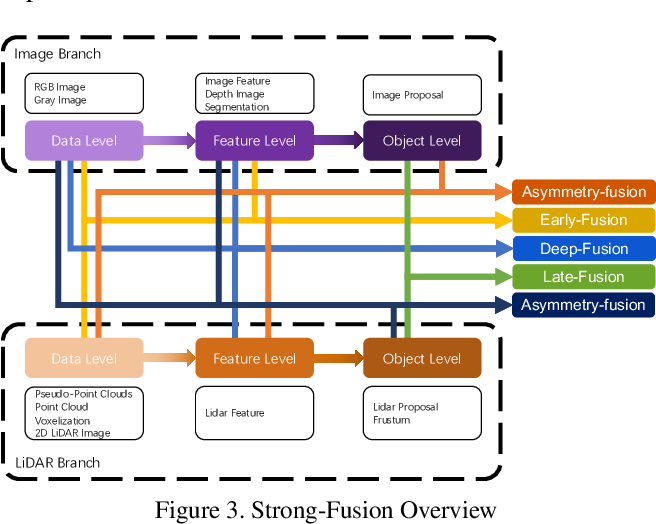
前融合也叫特征级融合,不同传感器的数据会在特征级别进行合并,也就是说,不同模态的数据经过处理和合并后会得到一个特征集合。一般来说,每个模态数据的特征会被分别提取,然后被提取到的特征会被合并为一个新的特征向量,这个特征向量可以表示多个模态数据合并后的信息,然后合并后的特征会被用于模型训练。前融合能够保证特征在融合的过程中不丢失,并且部署非常简单。但是,多模态的融合会导致很高特征维度过高,进而导致模型泛化性能下降。此外,特征融合后,多个模态之间不能解耦,也就是不能将这个系统做成可插拔的,整个框架的灵活性会下降。
后融合也叫决策层融合,不同输入类型的数据,被喂到不同的模型里。一般来说,后融合分别训练针对不同模态数据的模型,然后分别使用这些模型对相应输入进行推理,整合得到的推理结果得到最终结果。后融合是模块化的,因此更换某个模型也不会影响整个融合,无非就是对齐一下输出。系统设计也比较简单,用KF之类的跟踪算法进行匹配即可。

前融合
网上前融合的开源项目不少,但是在Github仓库中往往不会出现“Early Fusion”的关键词。
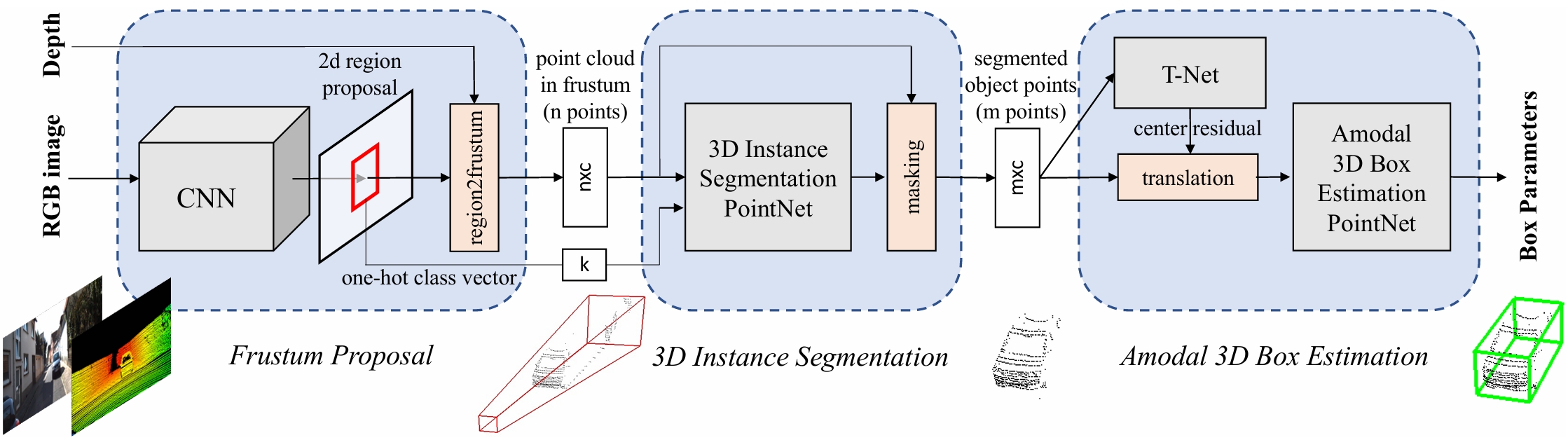
Frustum PointNets
使用2D Object Det 在图像中得到BBox并得到类别,借助相机内参将2D BBox提升为3D frustum (视锥)
基于上述视锥,用改进的PointNet进行 3D obj instance seg
基于分割后的目标点云,使用另一个PointNet进行 amodal 3D BBox reg
论文中有一个概念“Amodal ”。modal perception 指的是分析直接可见的区域,amodal perception 指的是非模态感知,是从心理学中引申出来的概念,比如被栅栏挡住的狗,虽然我们看到的是“一条断断续续的狗”,但是我们仍然会认为它是“一条连续的狗”。
Amodal Detection of 3D Objects: Inferring 3D Bounding Boxes from 2D Ones in RGB-Depth Images, not only find object localizations in the 3D world, but also estimate their physical sizes and poses, even if only parts of them are visible in the RGB-D image[4]
意思就是,在感知算法中,amodal perception 指从相机的2D图像中获取3D BBox,包括目标的物理尺寸和位姿,即使目标在2D图像中部分可见(被遮挡)。
PointPainting
一个图像实例分割网络,得到像素级的分割结果(Score)
LiDAR 点云被投影到分割后的MASK中,使用分割得到的Score标注
使用LiDAR的检测网络进行推理,得到3D BBox

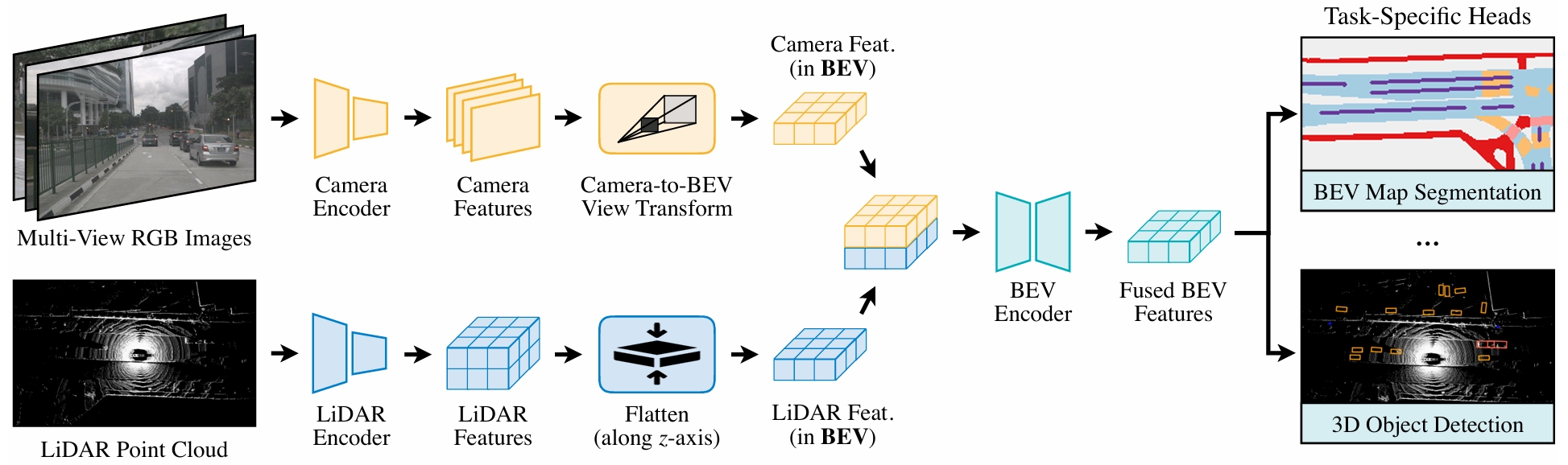
BevFusion
使用BEVFromer或者LSS,从多个视角(6个)RGB相机中提取并生成BEV特征,在这里作者提出了很多高效的方法
使用3D卷积,从LiDAR点云数据中提取BEV特征,与相机特征concat
将concat后的BEV特征送到BEV Encoder中,得到融合BEV特征地图
最后使用不同的Heads完成不同3D任务
和其他算法的区别是,BEVFusion将相机和LiDAR的特征整合到同一个BEV空间,而不是把一个传感器的特征投影到另一个传感器特征上。
前融合的难点
时间同步:多模态数据的时间戳可能出现不对齐的情况
空间同步:多模态数据的内外参标定可能不准确,和时间同步的问题类似,可能导致PC和RGB数据时空不对其,影响融合效果
数据增强:多模态数据增强比单模态数据的增强困难很多
模块耦合:如果更换了传感器或者模型,整个模型架构都需要重新设计
后融合
后融合先获取Camera和LiDAR的检测结果,然后进行匹配(匈牙利或KM算法)和状态更新(KF类算法),因此后融合是目标级的融合。后融合中,根据不同的具体方法,Camera和LiDAR的输出结果可能是2D和3D。后融合的目的一般是获取更为鲁棒的BBox框边界估计和位置估计。
搜索“Late fusion”能够获取到的信息很少,这是因为前&后融合是学术或工业界人为作出的分类,更多出现在Survey或Review中,而大部分作者在设计模型的时候并不会强调自己是前&后融合。
此外,后融合更广泛的用于工业界中,学术界更喜欢在前融合上做创新。比较知名的使用了后融合的开源框架是Apollo和Autoware,随着版本迭代,这两个框架中也加入了很多前融合的模型。
在后融合中,KF用于融合观测方程,将Camera和LiDAR的输出结果在观测层面融合,然后迭代状态方程[11]。
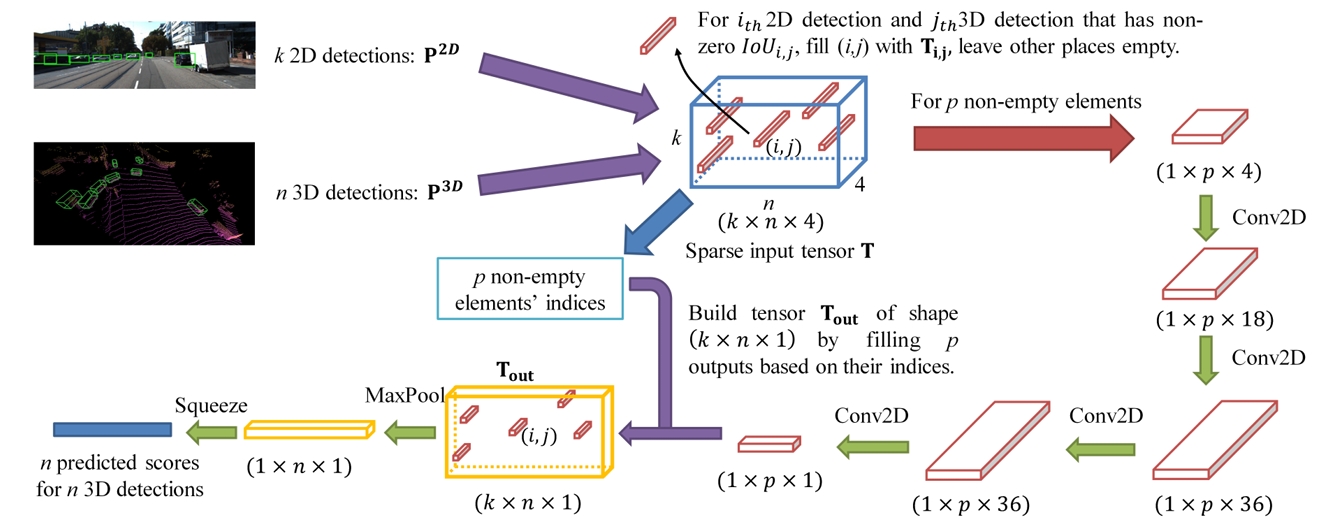
CLOCs
来自论文《CLOCs: Camera-LiDAR Object Candidates Fusion for 3D Object Detection》。方法是将相机的2D BBox和LiDAR的3D BBox转换为联合检测候选,表现为稀疏的Tensor,即下图的蓝色框,这一步的目的是把2D&3D检测候选变成一组一致的联合检测候选。然后使用一系列的2D卷积来处理输入稀疏Tensort中的非空元素,最终,被处理完的Tensort通过maxpool映射到被学习的图像。
通过构建一个 的Tensor,维度4代表 这4个通道分别代表2D和3D BBox的IoU,2D检测的Score,3D检测结果的Score,LiDAR检测的BBox和LiDAR平面的归一化距离。当IoU为0时,整个Tensor会被清除。
CLOCs确实是在Object-Level或Decision-Level进行融合,但是并没有使用KF一类的跟踪方法进行后融合,仍然是依赖CNN输出融合结果。
Matlab中的后融合
Matlab也提供了一个 Object-Level 后融合案例,使用LiDAR的3D BBox(PointPillars)和Camera的2D BBox(Yolov4)检测结果,最后使用 joint integrated probabilistic data association (JIPDA) tracker 实现融合。

代码分析
比较特别是的,Matlab通过读取标注信息作为Camera和LiDAR的检测结果。
[ptCld,lidarBboxes] = helperExtractLidarData(dataLog);
[img,cameraBBoxes] = helperExtractCameraData(dataLog,dataFolder,camIdx);接下来初始化Filter的参数,其中initLidarCameraFusionFilter 参数会让函数返回一个EKF tracker。不过这几天Matlab官网崩了,没办法通过源码看到@helperInitLidarCameraFusionFilter 这个函数内部的细节。
% Setup the tracker
tracker = trackerJPDA( ...
TrackLogic="Integrated",...
FilterInitializationFcn=@helperInitLidarCameraFusionFilter,...
AssignmentThreshold=[20 200],...
MaxNumTracks=500,...
DetectionProbability=0.95,...
MaxNumEvents=50,...
ClutterDensity=1e-7,...
NewTargetDensity=1e-7,...
ConfirmationThreshold=0.99,...
DeletionThreshold=0.2,...
DeathRate=0.5);循环处理80帧数据,每帧都加载一次传感器数据,同时更新自车位置、朝向和速度。
然后从LiDAR和Camera数据中提取BBox,外参和时间戳,这两个传感器的数据会被转换到车体坐标系。
在第1帧仅使用LiDAR数据初始化跟踪器,后面的帧使用LiDAR和Camera的融合数据,然后将融合数据喂到tracker中。
% Set the number of frames to process from the dataset
numFrames = 80;
for frame = 1:numFrames
% Load the data
fileName = fullfile(dataPath,strcat(num2str(frame,"%03d"),".mat"));
load(fileName,'dataLog');
% Find current time
time = dataLog.LidarData.Timestamp - tOffset;
% Update ego pose using GPS data to track in global coordinate frame
[pos, orient, vel] = egoTrajectory.lookupPose(time);
egoPose.Position = pos;
egoPose.Orientation = eulerd(orient,"ZYX","frame");
egoPose.Velocity = vel;
% Assemble lidar detections into objectDetection format
[~, lidarBoxes, lidarPose] = helperExtractLidarData(dataLog);
lidarDetections = helperAssembleLidarDetections(lidarBoxes,lidarPose,time,1,egoPose);
% Assemble camera detections into objectDetection format
cameraDetections = cell(0,1);
for k = 1:1:numel(dataLog.CameraData)
[img, camBBox,cameraPose] = helperExtractCameraData(dataLog, dataFolder,k);
cameraBoxes{k} = camBBox; %#ok<SAGROW>
thisCameraDetections = helperAssembleCameraDetections(cameraBoxes{k},cameraPose,time,k+1,egoPose);
cameraDetections = [cameraDetections;thisCameraDetections]; %#ok<AGROW>
end
% Concatenate detections
if frame == 1
detections = lidarDetections;
else
detections = [lidarDetections;cameraDetections];
end
% Run the tracker
tracks = tracker(detections, time);
% Visualize the results
display(dataFolder,dataLog, egoPose, lidarDetections, cameraDetections, tracks);
endApollo中的后融合
以Apollo 6.0为例。
感知模块位于:
Path
----
C:\Users\FunnyWii\Downloads\apollo-6.0.0\apollo-6.0.0\modules\perception感知模块输入包括:
128线LiDAR输入
16线LiDAR输入
RADAR数据
图像数据
RADAR外参
相机内参&外参
自车速度和角速度
输出包括:
3D目标tracks,包含朝向,速度,类别
交通灯检测结果
接下来看一下文件夹结构:
perception
├── base // 感知模块公共的基础类定义
├── camera // 相机检测(子模块)
├── common // 感知模块公共基础操作定义,比如图像和点云的一些预处理
├── data // 相机内外参
├── fusion // 多模态数据的融合
├── inference // 深度学习推理
├── lib // 基础库,包括线程、时间等
├── lidar // 激光雷达检测(子模块)
├── map // 高精地图
├── onboard // 子模块入口
├── production // 感知模块入口,模型权重
├── proto // protobuf的消息结构
├── radar // 毫米波雷达处理(子模块)
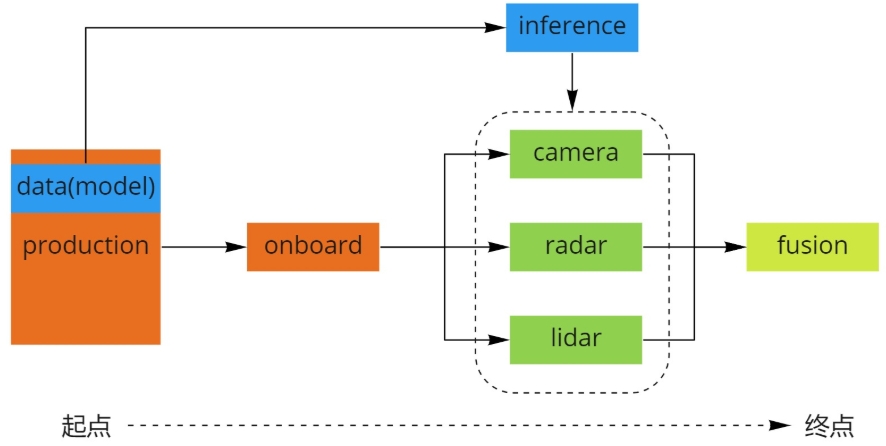
└── tool // 离线测试工具感知模块入口在production文件夹中,代码从这里开始看。通过production中的launch文件加载对应dag,启动感知模块。launch文件用来启动,dag文件描述了整个系统的拓扑关系,也定义了每个Component需要订阅的话题。
在onboard 中是各个子模块的入口,不同模态的数据在这里进行处理。
inference 深度学习模型部署后的推理模块,权重文件存放在production/data 中。
camera/lidar/radar 三种传感器的识别和跟踪等功能。
fusion 多模态数据融合,感知模块终点。
apollo-6.0.0\modules\perception\production\launch 中保存的launch文件中划分了很多module,一个launch文件中有几个module,就会启动几个进程,进程间的内存空间是独立的。
apollo-6.0.0\modules\perception\production\dag 中保存的配置文件中则划分了很多component,
Autoware中的后融合
待更
匹配算法
多目标跟踪中的目标匹配算法 - FunnyWii's Zone
KF及其扩展
学习Kalman Filter(自用版) - FunnyWii's Zone (还没更新完)
后融合的优势
前面提到了后融合是目标级的融合,相比前融合,时间和空间对齐的误差是在目标级进行修正。
后融合模块只需要从多模态数据的推理结果,如果更换了模型,只要对应模型的输出结果是相同的,那么对后融合模块不会造成影响,也就是后融合的上游可以做成可插拔的,更换十分方便。
参考文章
[1] Early Fusion vs. Late Fusion in Multimodal Data Processing | GeeksforGeeks
[2] Late vs early sensor fusion for autonomous driving | Segments.ai
[3][1711.08488] Frustum PointNets for 3D Object Detection from RGB-D Data
[4] 3D检测中常见的amodal perception术语 - 知乎
[5] Amodal perception - Wikipedia
[6] [1911.10150] PointPainting: Sequential Fusion for 3D Object Detection
[7] [2205.13542] BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation
[8] Apollo开放平台文档 - Apollo感知融合能力介绍
[10] 多传感器前融合和后融合总结 - 知乎
[12] Object-Level Fusion of Lidar and Camera Data for Vehicle Tracking - MATLAB & Simulink
[13] trackerJPDA - Joint probabilistic data association tracker - MATLAB
[14] Apollo 7.0——percception:lidar源码剖析(万字长文) - 知乎
[15]万字讲解Apollo,全网Apollo资料整理和学习-CSDN博客
[16] [2009.00784] CLOCs: Camera-LiDAR Object Candidates Fusion for 3D Object Detection
评论