
视觉 [39]

【重读经典】YOLO的进化之路(下)
YOLOv9 和 YOLOv4/v7 一脉相承的作品,但是 Anchor-Free。 PGI 可编程梯度信息 全称 Programmable Gradient Information,这是一个辅助监督框架,目的是解决深度网络逐层传播的信息损失问题。 PGI 包含 3 个主要组件:主分支,辅助可逆分支


【重读经典】YOLO的进化之路(中)
没想到 YOLOv1 到 YOLOv4 就已经写了快 20000 字…… 编辑页面卡的不行,我不得不分几篇写完。YOLOv1 到 YOLO 26一共 12 篇,正好分上中下三篇。 YOLOv5 重量级来了,Ultralytics 闪亮登场了。第一个没有论文的 YOLO 正式版本,但它成为了工业界的事

【重读经典】YOLO的进化之路(上)
自 2016 年 YOLOv1 发布至今的十年里,YOLO 的核心版本已一路演进到了 v26——不过这其中包含了一次版本大跳跃:官方为了统一命名规范,直接跳过了 v13 到 v25。 回想起我使用 YOLO 的历程:从只会用官方的 COCO 数据集训练,到使用 MMLab 的各种训练框架,再到自己修

【重读经典】极坐标BEV方法
极坐标BEV的表示方法:在BEV空间按照角度和半径两个维度进行划分,而非笛卡尔坐标系下的均匀矩形网格。自车近处高分辨率,远处低分辨率,契合相机近大远小的成像特点。 核心优势 非均匀网格划分&分辨率优化 极坐标BEV以ego为中心,角度方向采用固定步长划分,径向长尾分布不均匀划分。 角度划分:θ ∈

3D稀疏卷积 3D Sparse Convolution
点云数据体素化后,有90%+的Voxel是空的,如果像VoxelNet那样直接使用3D Conv,计算量太大。 左图是稀疏的2D Tensor,深灰色像素都是0,浅灰色是non-zero点。 右图是稀疏的3D Tensor,只有红色的体素才是non-zero。 因此提出了3D稀疏卷积——3D Spa
【重读经典】BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework
BEVFusion有两篇论文: 一篇名为《BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework》,发表于2022年。 另一篇名为《BEVFusion: Multi-Task Multi-Sensor Fusion with Unif
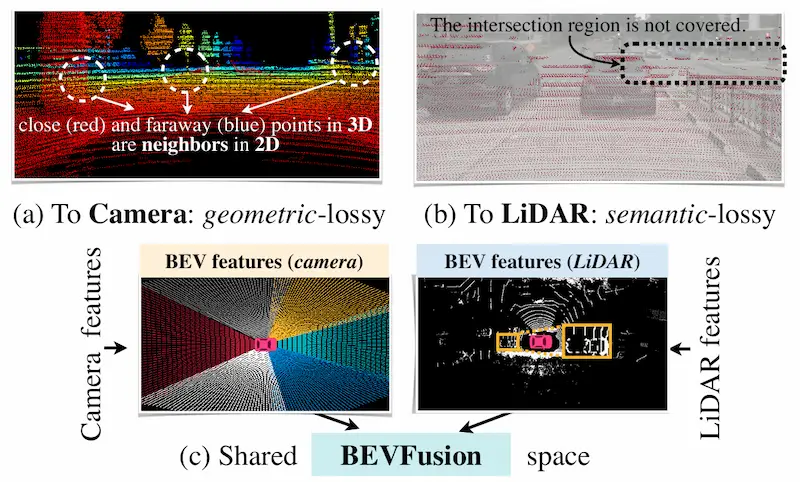
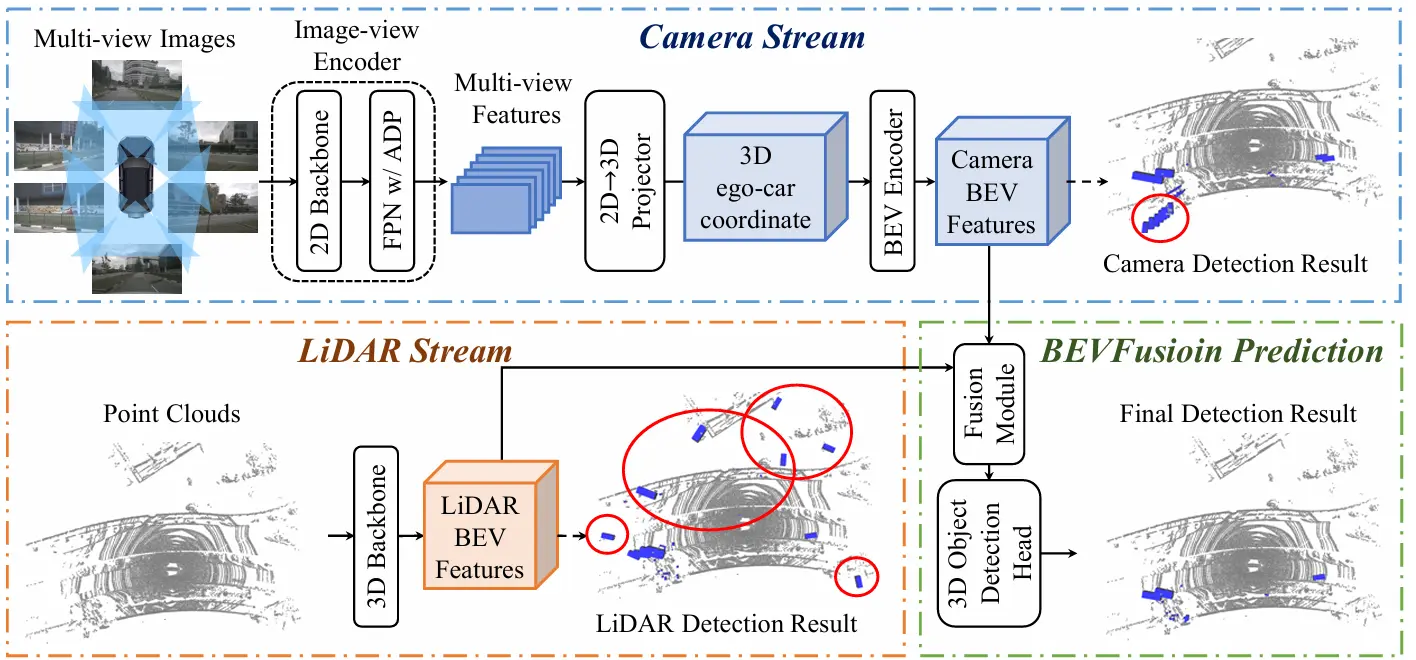
【重读经典】BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation
自动驾驶常见传感器包括相机,LiDAR,雷达等传感器。 相机能提供丰富语义,LiDAR提供准确的空间信息,雷达能进行速度估计。 对于多传感器方案,当时的传感器投影存在信息损失的问题: LiDAR->Cam:存在几何损失,像素坐标系中相邻的像素点,在3D空间中可能距离很远。设想一个人站在墙前面,在像素
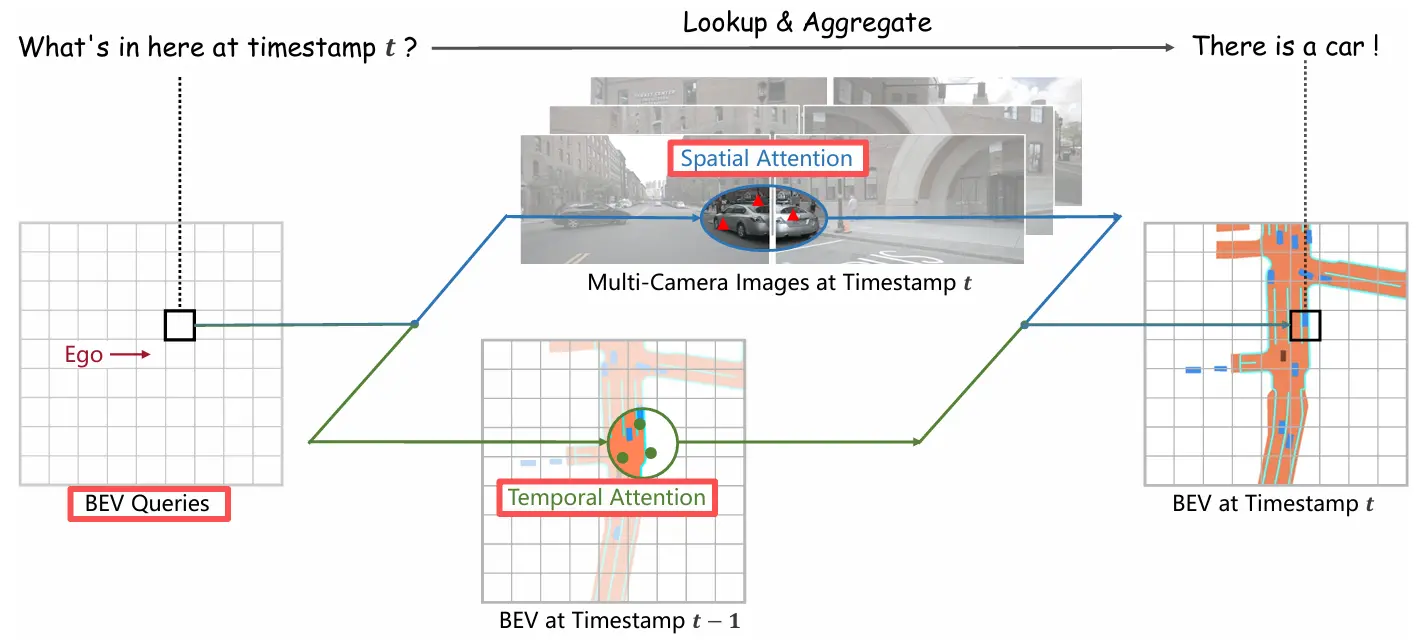
【重读经典】BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
先看论文题目 Multi-Camera:多相机纯视觉方案,Camera-based的mAP天然比LiDAR-based和Fusion-based的要低 Spatiotemporal:时间空间 Transformer:用到了Transformer架构以及Attention机制 创新点 论文摆脱了之前L
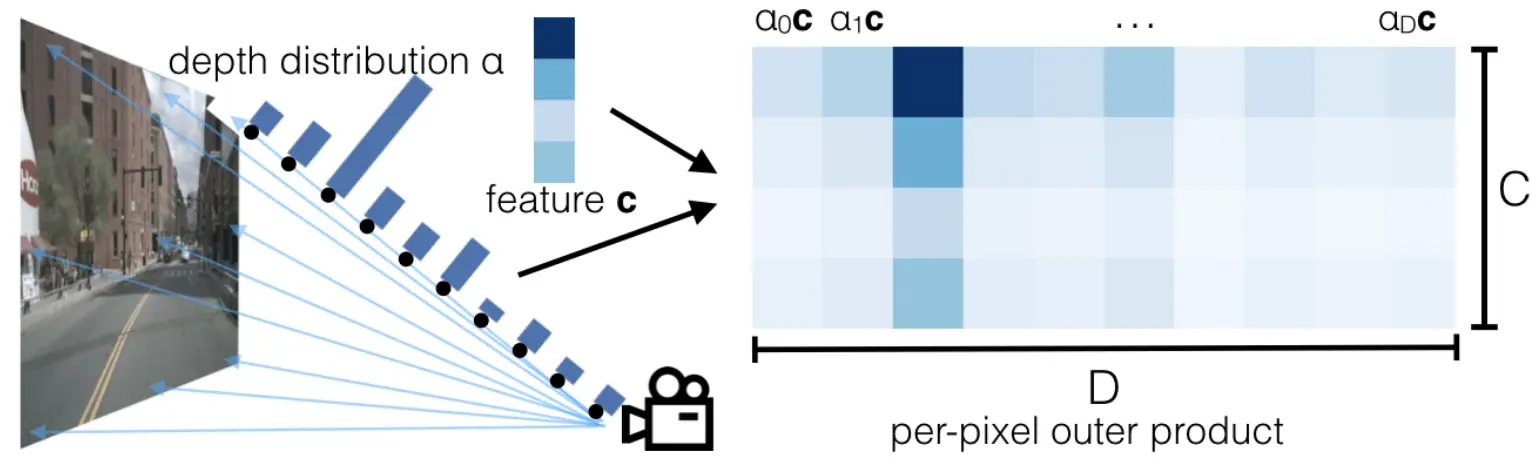
【重读经典】Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
LSS是NVIDIA在ECCV2020上发表的文章。 理解一下论文标题中的Lift, Splat, Shoot三个单词。 这三个单词对应模型中三个核心步骤。 Lift:提升。2D图像特征提升到3D视锥空间特征。 Splat:泼溅。所有相机生成的3D视锥特征,泼洒到统一的BEV平面网格。 Shoot:

【重读经典】3D Bounding Box Estimation Using Deep Learning and Geometry
Deep3DBox是一篇比较早的使用单目相机进行3D目标检测和姿态估计的方法。 Deep3DBox先用CNN回归目标的方向和尺寸,因为这两类属性稳定性比较高。然后结合2D BBOX的几何约束求解平移量,以生成完整的3D BBOX。 有些传统的方法基于PnP,通过2D-3D关键点对应关系求解姿态,需要
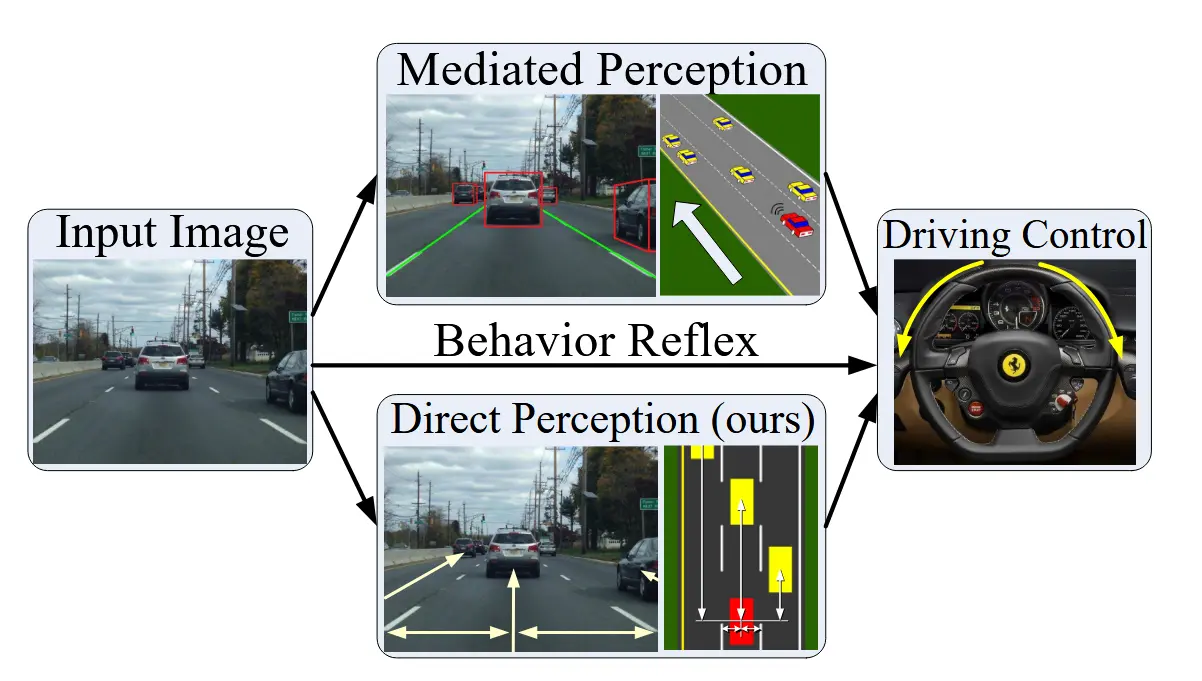
【重读经典】DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving
标题中的Affordance一词,本意是”预设用途,功能特性“,最初在知觉心理学和设计学领域出现。 后来在人机交互领域,Affordance的含义变成了:一个产品让用户自然领悟到用法的能力。 在机器人领域(自动驾驶和机器人的感知不分家),被引申为可以执行的潜在动作,即在特定情况下哪些动作是可执行的。

多传感器融合——后融合
多传感器融合的方案可以分成前融合(Early Fusion)方案和后融合(Late Fusion)方案。 前融合也叫特征级融合,不同传感器的数据会在特征级别进行合并,也就是说,不同模态的数据经过处理和合并后会得到一个特征集合。一般来说,每个模态数据的特征会被分别提取,然后被提取到的特征会被合并为一个

GStreamer学习
GStreamer在我看来更像是视频编解码领域的内容。 JPEG和MPEG 先区分一下这两个格式[1]。 JPEG全称Joint Photographic Experts Group,文件拓展名一般为.jpg或者.jpeg,是一种静态图像压缩标准,压缩比能达到10:1。 MPEG全称Moving P

计算机视觉中的Affine和Perspective Transformation
Affine Transformation 仿射变换是在二维空间上对图像进行平移(Translation)、缩放(Scale)、旋转(Rotate)、错切(Shear)操作的组合。 四种变换的矩阵形式分别为: 平移:T_t = \begin{bmatrix} 1 & 0 & p_x \\ 0 & 1

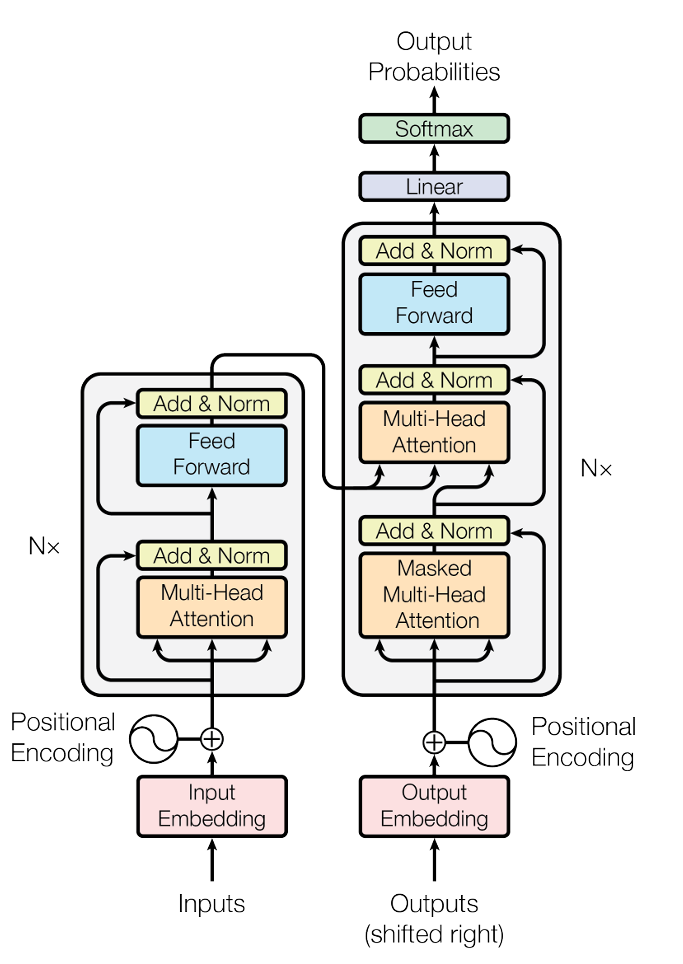
学习Transformer
Transformer在谷歌2017年的论文 [1706.03762] Attention Is All You Need 中首次被提出,主要用于NLP(Natuarl Language Processing,自然语言处理)的各项任务。 后来在CV领域,研究者们基于Transformer架构开展了一
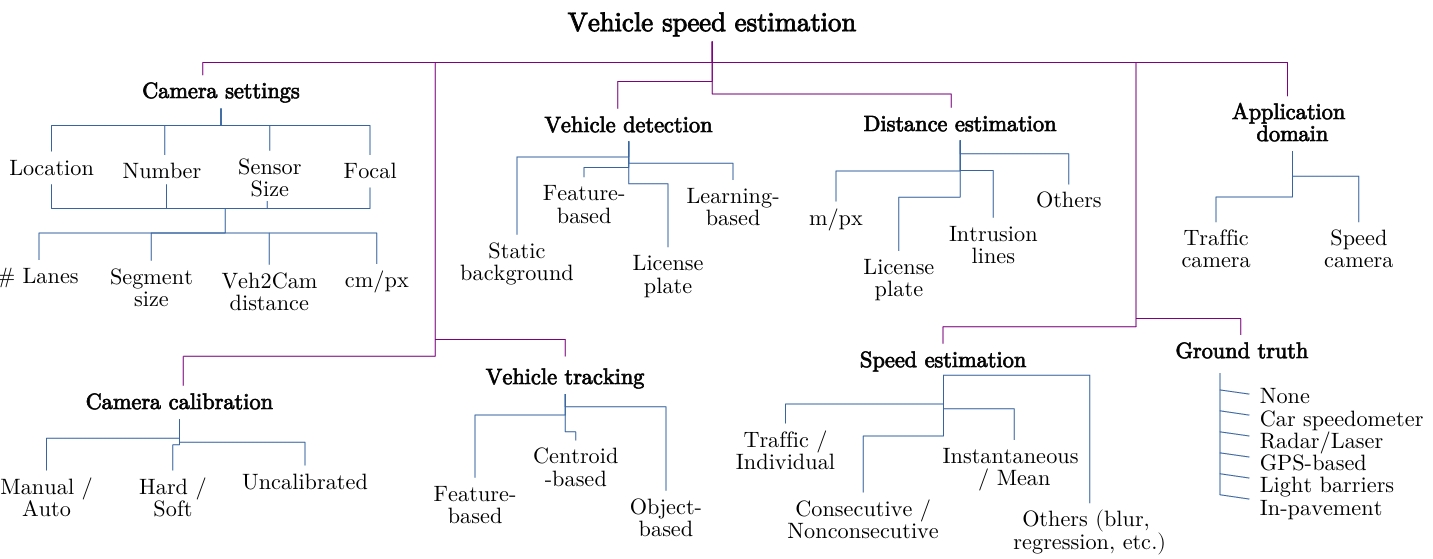
单目相机的相对速度估计
前言 单目相机的目标距离估计本身就已经充满了挑战,那么目标的(相对)速度估计也必然是十分困难... 目前单目相机的相对速度估计算法可以分成两类:传统方法和深度学习方法。没错,什么任务都可以深度学习。 传统方法中,最经典的是Mobileye在2003年的一篇论文中提出的算法。这个算法包含目标距离和速度
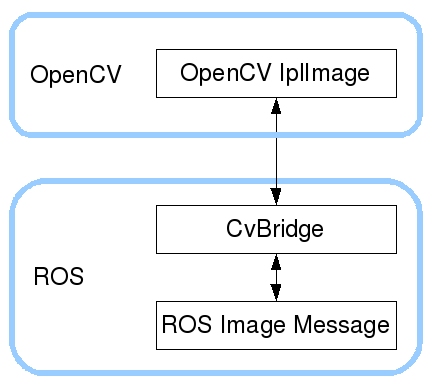
ROS不使用自带OpenCV以及替换cv_bridge
系统:Ubuntu20.04 平台:Jetson Orin NX ROS:ROS2 Foxy OpenCV:4.5.4 with CUDA 问题源自编译时警告: /usr/bin/ld: warning: libopencv_imgcodecs.so.4.2, needed by /opt/ros/
ROS2的消息发布和订阅&图像发布和订阅
ROS2的编译 colcon 是 ROS2 编译的工具。ROS2 的工作空间与 ROS1 保持一样的目录结构: <workspace>
├── build # 编译时自动生成,包含编译的中间文件
├── install # 编译时自动生成,包含编译的结果:可执行文件,库文件,

道路目标流量统计算法
实现流量统计算法有两个前提: 能够实现目标检测,最基本的前提,必须能够识别到视频帧中的车辆和行人。 能够进行目标跟踪,在检测的基础上,为目标分配一个唯一的ID。流量计数依赖于目标的唯一ID。 目标检测算法以YOLO系列为例。 跟踪算法以ByteTrack跟踪结果为例。将检测结果objects作为By