

摘要: 近年来,随着深度学习技术的发展和硬件算力的不断增强,自动驾驶技术越来越多的应用在各种场景。包括视觉感知、激光雷达感知和多传感器融合感知技术在这些年都得到了迅速发展。本文首先回顾了近年来自动驾驶感知技术的相关工作,然后介绍了相关工作所用到的方法和技术。随后整理并介绍了自动驾驶感知所需的数据集和评价指标。最后总结了目前传感器技术面临的诸多挑战和未来的发展趋势。
关键词:自动驾驶 端到端 感知技术 深度学习
概述
传统的自动驾驶系统是模块化的,其中包括感知、定位、规划与决策、控制等子系统。由于子系统中的每个模块只为一个独立的功能服务,这样的设计拥有较强的可解释性和可验证性,且易于调试。但是由于各模块的优化目标不同,子系统以及整个自动驾驶系统没有一个统一的优化目标。而且每个模块间的误差会累积,导致整个自动驾驶系统的误差变得更大。端到端是深度学习中的概念,英文为End-to-End,意为只要输入原始数据,就能通过深度学习模型,输出最终结果。在自动驾驶领域,在获取到相机和激光雷达的感知数据后,仅需要一个端到端模型,即可输出车辆油门踏板的深度、制动器的力度和方向盘的转向角度等具体控制输出。也就是把传统自动驾驶系统的多个子系统整合为一个感知决策控制一体化的单模型结构[1]。
不过端到端的单一模型也存在一些挑战[2]:
多传感器和输入模态的困境:单一的输入模态不能处理复杂的场景,但多个传感器的视角、数据分布和价格存在巨大差异,在设计传感器布局和进行传感器融合时存在一定困难。为了增强系统鲁棒性,需要大量的数据集参与训练,但是多传感器和输入模态导致数据集的扩充变得十分困难。
对视觉抽象的依赖:在单一端到端模型中,输入状态更加多元和高维,这可能导致表征和决策所需关注的区域不一致。
世界建模的复杂性:对高度动态的环境建模是一个非常有挑战性的任务,很多小细节比如信号灯很容易在推理阶段被忽视掉,仍然需要进一步的研究以确定哪些内容需要建模。
多任务学习:自动驾驶的任务往往十分复杂,端到端模型作为单一模型,涉及到多任务的组合,比如检测、跟踪、预测、决策和控制等。如何在多个学习任务间实现知识共享,同时避免任务间的干扰仍然是一个重要问题。而且任务间的权重分配和优化还需要仔细设计,避免某个任务过度主导模型学习。随着任务种类和数量的增加,多任务学习框架的复杂性和训练时间也会相应增加。
策略蒸馏的选择:策略蒸馏在端到端模型中非常常见,可以将一个或多个教师的策略蒸馏到一个学生模型中,能够有效的压缩模型参数规模。但是合适的蒸馏策略以及更有效的蒸馏损失函数仍然需要进一步研究。
可解释性差:传统的自动驾驶框架的多个子系统,内部能够得到相对清晰的解释,但是一个完整的端到端自动驾驶系统,会损失一定的系统透明度。随着法规和标准对自动驾驶透明度要求的提高,研究如何解释模型变得十分重要。
因此,将自动驾驶系统中的各个模块的功能整合为一个仅面向子系统的端到端模型,是一个折中的解决方案。自动驾驶的感知系统旨在采集并理解场景,系统中的单个模块负责某一项任务,比如车辆和行人检测、信号灯检测、物体跟踪和车道线检测等。端到端的感知系统会将这些单个模块中的感知任务整合为单一的端到端感知模型,只要输入原始的感知数据,就能够完成上述所有感知任务并输出感知结果。
在本调查中,调查了90篇近年来自动驾驶感知技术的相关文献,总结了相关工作和方法,并针对目前的感知技术进行了总结和展望。
相关工作
视觉感知
视觉感知主要依靠的传感器是相机,相机算法利用光学成像原理来感知车辆周围环境,同时由于其输出的图像包含丰富的颜色信息,能够为深度学习模型提供丰富的特征数据,从而能够承担高精度的目标检测任务。
2D视觉感知
传统视觉感知方法包括尺度不变特征变换 (SIFT)[3],Viola–Jones 矩形[4],梯度直方图 (HOG)[5]等,这些方法大多源于统计学,不过传统方法过于依赖人工的特征提取,而且这些方法无法在不重新训练模型的情况下接受新的数据,实用性也受到了一定影响。因此目前主流的2D视觉感知方案是基于深度学习的感知。
基于深度学习的2D视觉感知拥有更高层次的抽象,更高的精度和更快的执行速度,这些感知系统大多基于卷积神经网络(CNN)。在基于CNN的模型中,区域卷积神经网络(R-CNN)的方法及其变体[6]是应用最为广泛的两阶段检测模型,其后的Fast R-CNN[7]和Faster R-CNN[8]在R-CNN的基础上拥有更高运行效率。R-FCN[9]通过引入全卷积,在不损失性能的情况下进一步提高了运行速度。此外SSD[10]和YOLO[11]凭借其速度快和精度高得到了广泛应用,其中YOLO凭借其庞大的社区进行版本迭代,目前版本已经推出至YOLOv10[12],下图为YOLO检测效果。

除了目标检测外,还有UNet[13],SegNet[14]和ERNet[15]可以用于语义分割,下图为SegNet分割效果。

LaneNet[16],UFLD[17],LaneATT[18]和GANet[19]可以进行车道线检测,下图为LaneNet检测效果。

2D视觉感知大多是轻量级的物体检测,旨在低功耗边缘计算设备上运行检测推理,但是相机和人眼间的速度差距仍然很大。尽管近些年2D视觉感知技术取得了很大进展,但是自动驾驶领域仍然依赖于获取目标在3D世界中的位置和姿态。
3D视觉感知
在自动驾驶中,获取目标检测结果的下一步是获取物体在世界中的位置。自动驾驶领域中使用最为广泛的单目相机,由于其小孔成像的特性,在成像时丢失了深度信息,因此2D视觉感知只能获取检测到目标的2D包围框,往往不能得到准确的物体空间信息。因此,越来越多研究者开始使用双目相机或者深度学习方法获取物体的3D包围框,在此基础上就可以获取物体的空间位置信息。
Shift R-CNN[20],Monofenet[21],Ida-3d[22],Disp R-CNN[23],和Zoomnet[24]等方法使用区域建议网络(RPN)的方式,这类方法的特点是在检测器的最后使用一个共享卷积层生成2D建议,而不是外部算法,这样可以节约计算成本,下图为Shift R-CNN检测效果。

还有一些研究引入了空间信息[25-32],这类方法的特点是让网络从图像中隐式地学习深度线索,也就是为单目图像提供额外的深度估计器。和区域建议网络方式类似,这类方法也采用了基于区域的框架。下图为ROI-10D检测效果。

还有一些研究使用单次物体检测器,CenterNet[33]使用了一种无锚点的单次检测器,并将其扩展到基于图像的单次检测。后续很多研究也沿用了这种方法[34-40]。这类方法的特点是同时拥有较好的实时性和准确性,下图为CenterNet检测效果。
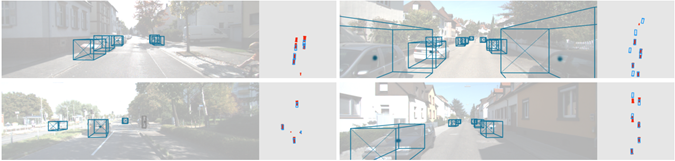
3D视觉感知技术能够获取物体在3D世界中的位置和姿态,不过从2D图像中感知3D世界仍然是一个不适定问题,而且标注3D数据是十分昂贵的,并且现有的数据集规模仍然有限。
激光雷达感知
相比相机获取的RGB信息会丢失一部分深度信息,激光雷达采集到的点云数据中包含准确的3D位置信息。根据准确的3D位置信息,则可以预测出目标的速度和加速度等运动信息,这些信息的准确性对控制系统来说意义重大。
自动驾驶中的激光雷达感知算法大致分为3类,其中一种是BirdNet[41]和BirdNet+[42],它们是将点云数据转换为2D空间投影的方法。

VoxelNet[43]和VoxelNext[44]是一类将点云数据转换为体素的方法。下图为VoxelNet检测效果。
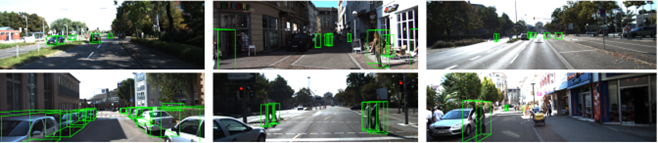
PointNet[45],PointNet++[46]和PointRCNN[47]等方法则是直接使用原始点云作为模型输入。下图为PointRCNN检测效果。

比起单目相机,激光雷达的测距是最准确的,因此使用激光雷对目标距离进行检测有较高的可靠性。但是激光雷达的点云信息缺乏有效的语义信息,这是因为激光雷达本质上是一个距离传感器,而不是一个上下文传感器。所以,今后的研究方向会是激光雷达点云和相机RGB图像相融合,以获取更全面的道路场景信息,结合端到端的感知技术,实现场景信息的分析。
多传感器融合
多传感器融合利用不同传感器的数据输入进行检测,基于多传感器融合的方法显著优于仅使用激光雷达或仅使用单目相机的方法,激光雷达和相机的融合一般被分为三类:前融合,深度融合和后融合[48]。
MVX-Net[49],Complexer-YOLO[50],PI-RCNN[51],PointPainting[52]和PFF3D[53]等研究使用的是前融合的方法。下图为Complexer-YOLO检测效果。

MAFF-Net[54],MVAF-Net[55],EPNet[56]和RoIFusion[57]等研究使用的是深度融合方法。下图为RoIFusion检测效果。

CLOCs[58],Fast-CLOCs[59]和Snow-CLOCs[60]等方法使用的是后融合方法。下图为CLOCs检测效果。

目前还没有产生一种最好的融合方式,需要进一步的研究以建立更轻量化和鲁棒的模型。
方法
视觉感知方法
2D视觉感知方法
在传统视觉感知方法中,SIFT[3]方法通过获取特定关键点附近的梯度信息检测目标。HOG[5]算法是通过计算空间分布区域的梯度强度及其方向信息来检测目标。下图为HOG方法的流程。

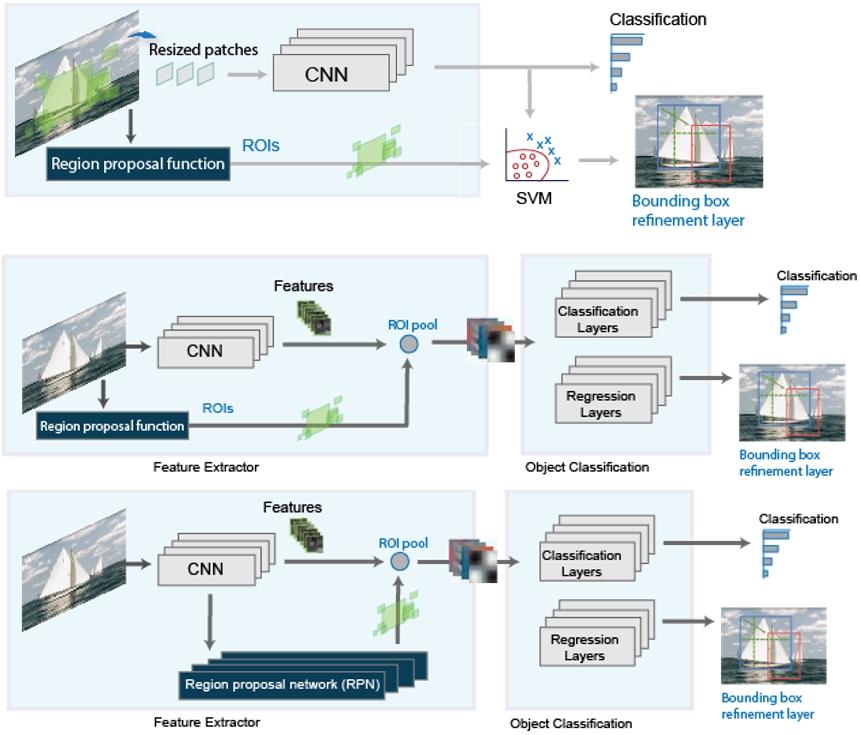
基于深度学习的CNN方法,比如R-CNN[6]方法使用区域提议网络,网络会从图像中提取出目标的候选区域,CNN再对该区域进行分类,最后使用CNN特征训练的支持向量机完善2D包围框。Fast R-CNN[7]的检测器则是对整个图像进行处理,而且整合了每个区域的对应的CNN特征,会比R-CNN更加高效。Faster R-CNN[8]增加了一个区域提议网络,直接在网络中生成区域建议,而不再使用包围框等外部算法,它的区域提议网络使用锚点框对物体进行检测。这三种方法使用了两个单独的输出,一个是概率的分类,一个是包围框坐标的回归。下图为R-CNN等方法的框架:
YOLO系列代表的是单次目标检测器,只基于回归来预测目标检测结果。YOLOv1[11]使用一种新的单次目标检测器,通过同时检测所有的边界框,统一了物体检测步骤。YOLOv2[62] 挑选好的锚有助于网络学习预测更准确的包围框。作者对训练中的包围框进行k-means聚类,以找到好的先验。由于YOLOv2不使用全连接层,输入可以是不同的尺寸。YOLOv3[63] 提出了一个由53个卷积层组成,带有Res残差网络的DarkNet-53骨干,然后在骨干中加入了一个改进的空间金字塔池SPP模块,连接了多个最大集合输出,而没有子采样,允许更大的感受野。YOLOv4[64]在DarkNet-53的基础上,采用跨阶段部分连接,以Mish激活函数作为骨干,该模型被称为CSPDarknet53。YOLOv5[65]采用Pytorch框架,在网络训练阶段,YOLOv5使用Mosaic数据增强操作提升模型的训练速度和网络的精度;并提出了一种自适应锚框计算与自适应图片缩放方法。YOLOv4的Neck结构中,采用的都是普通的卷积操作。而YOLOv5的Neck网络中,采用借鉴CSPNet设计的CSP2结构,从而加强网络特征融合能力。YOLOV6[66]采用采Anchor-free无锚范式,同时辅以 SimOTA标签分配策略以及SIoU包围框回归损失来进一步提高检测精度。基于RepVGG[67]设计了可重参数化、更高效的骨干网络 EfficientRep Backbone和Rep-PAN Neck。YOLOv7[68]提出了一个新的骨干网络ELAN-Net,在原始ELAN 的基础上,改变计算块的同时保持原ELAN 的过渡层构,在不破坏原有梯度路径的情况下增强网络学习的能力。YOLOv8[69]将YOLOv5[65]的C3结构换成了梯度流更丰富的C2f结构,并对不同尺度模型调整了不同的通道数,大幅提升了模型性能,对于检测头,使用了解耦头结构,将分类和检测分离,并且也使用了Anchor-free的无锚范式。使用BCE计算分类损失;使用CIoU和DF计算回归损失,主要思想是解决训练数据中类别不平衡的问题。YOLOv8的设计更偏向于工程实践。YOLOv9[70]拥有两项关键创新:可编程梯度信息(PGI)框架和广义高效层聚合网络(GELAN)。PGI框架旨在解决深度神经网络的信息瓶颈问题,并使深度监督机制与轻量级架构兼容。GELAN 架构的设计初衷是通过高效率和轻量级足迹来提高物体检测任务的性能。YOLOv10[12] 在后处理过程中完全消除了对非最大抑制NMS的依赖。同时使用双标签分配的方法,实现了准确率和速度的同时提升,可以广泛应用于边缘计算设备。
3D视觉感知方法
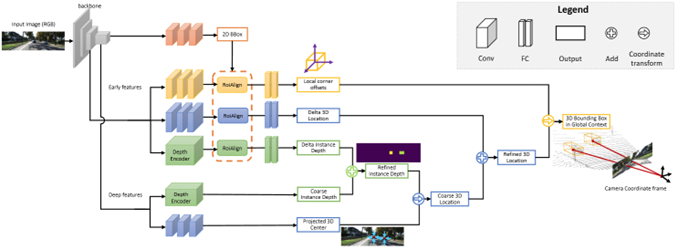
MonoGRNet[72] 提出了一种新颖的实例级深度估计方法,不管物体遮挡和截断,即可在没有密集深度数据的情况下直接预包围框的中心深度。从单目 RGB 图像中通过几何推断,在已观察到的二维投影平面和在未观察到的深度维度中定位物体非模态三维边界框。这种方法使用一个统一网络,同时完成2D目标检测,深度估计,3D定位和局部角度回归进而实现3D定位。下图为MonoGRNet方法框架。
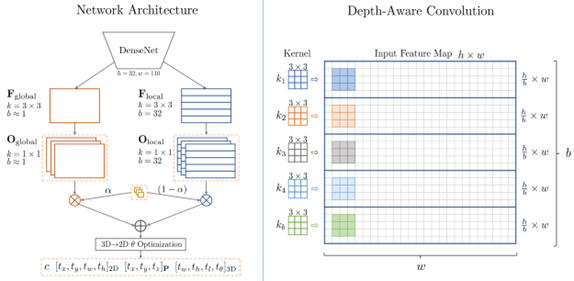
M3D-RPN[73]作者认为2D和3D检测任务各自的目标是最终对一个对象的所有实例进行分类,而它们在定位目标的维数上是不同的。我们期望能够在一个统一的框架内利用2D检测来指导和改进3D检测的性能。因此,作者重新定义了3D检测问题,使2D和3D空间都利用共享的锚点和分类目标,利用2D视角和3D视角的几何关系,结合深度感知卷积层实现了3D位置估计。下图为M3D-RPN方法框架。
SMOKE[36]作者认为认为其中的2D检测对于单目3D检测任务来说是冗余的,且会引入噪声影响3D检测性能,因此摒弃了模型中的2D检测部分,通过带有3D回归信息的单一关键点估计,为每个检测到的目标预测3D包围框。下图为SMOKE方法框架。

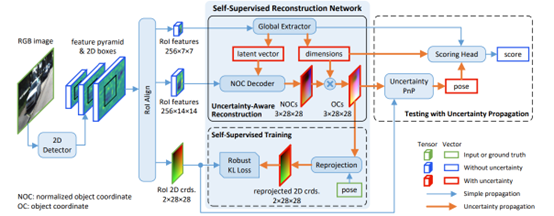
6DoF 姿态估计的最新进展表明,预测图像和对象 3D 模型之间的密集 2D-3D 对应图,然后通过Perspective-nPoint(PnP)算法估计对象姿态可以实现显着的定位精度。然而,这些方法依赖于目标的几何真值的训练,这在真实户外场景中很难获得。为了解决这个问题,MonoRUn[74]这种新颖的检测框架,它以自监督的方式学习密集对应关系和几何图形, 通过简单的3D包围框标注,用自监督的方式训练模型,采用具有不确定意识的区域重建网络来预测物体3D包围框。下图为MonoRUn方法。
M3DSSD[75]提出了一种具有特征对齐和非对称非局部注意力机制的模型。第一步,进行形状对齐,使特征图的感受野聚焦到高置信度的预定义锚点上。第二步,使用中心对齐方法,让2D/3D中心特征对齐。此外,学习全局信息并捕捉长程关系往往是很困难的,但其对于物体的深度探测却至关重要。因此,作者提出了一种新颖的具有多尺度采样的非对称非局部注意力块来提取深度特征。下图为M3DSSD方法框架。

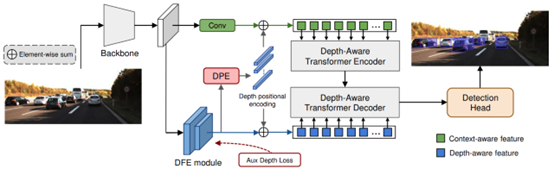
MonoDTR[76]使用由深度感知特征增强模块和深度感知变换器模块组成的网络,该网络可以轻松插入现有的3D目标网络,并且由不错的性能。下图为MonoDTR方法的框架。
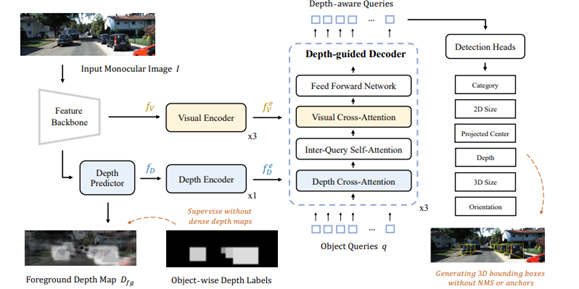
MonoDETR[77]引入前景深度图进行预测,并加入了以深度为引导的Transformer结构,通过具有复杂几何先验的基于中心的方法实现了非常有竞争力的性能。下图为MonoDETR方法的框架。
MonoCD[78]使用一种新的深度预测分支,利用整个图像的全局深度线索降低预测的相关性,在不引入额外数据的情况下实现了最先进的性能。下图为MonoCD方法的框架。

激光雷达感知方法
根据处理点云数据的方法,可以将算法分为三类:
转换为2D空间投影:比如BirdNet[41] 基于Fast R-CNN,首先将激光雷达点云信息投影到2D空间,也就是BEV鸟瞰图。一个模块会对BEV投影进行编码,然后通过一个R-CNN来估计物体在图像上的位置与方向。最后在后处理阶段计算3D包围框。BirdNet+[42]是前者的改进,则是一个完全端到端的3D物体检测框架,使用一个3D物体检测框架和回归分支取代了前者的后处理部分。下图为BirdNet+方法框架。
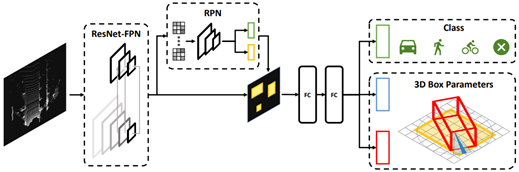
转换为体素:VoxelNet[43] 提出了一种端到端的点云检测框架,直接在稀疏点云上运行,避免了手动特征工程的信息瓶颈。它使用VFE体素特征编码网络,可以有效的提取体素特征,并引入RPN区域提议网络,用于高效的目标检测。VoxelNext[44]摒弃了传统的dense特征图和复杂的后处理步骤,直接在点云的稀疏特征上进行预测。通过额外的下采样和高效的BEV转换,该模型优化了计算效率,尤其适合长距离目标检测。还引入了基于体素的查询关联进行对象跟踪,提高了跟踪性能。下图为VoxelNext方法的框架

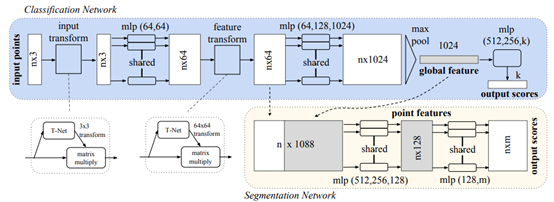
使用原始点云:PointNet[45]使用一个统一架构使用原始点云数据,进行有效的特征学习,但是其无法提取局部特征,也没有考虑点之间的关系。PointNet++[46]相比前者,利用空间距离对局部区域进行特征提取,并提出了一种自适应密度的特征提取方法,能够更高效的学习点云特征。PointRCNN[47]将整个场景中的原始点云划分为前景点和背景点,用自下而上的方式直接从点云生成高质量的3D预测。
多传感器融合方法
多传感器融合方法可分为前融合,深度融合和后融合。
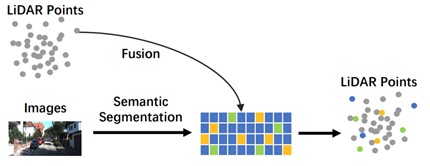
前融合:也叫数据级融合,直接融合传感器的原始数据。将传感器采集到的原始数据输入模型,再根据数据融合的结果进行推理。相较于后融合而言可以规避融合前大量的传感器数据表征的分析工作,直接从传感器原始数据入手进行融合,在原始数据间建立关联性。最后使用多目标跟踪与后处理提高检测精度。显然,前融合通过直接信息融合可以获得每个像素级别的深度信息,最终获得的信息量更大。MVX-Net[49] 提出了两种简单有效的多模态融合方法,PointFusion和VoxelFusion,用于将2D图像特征与3D点云特征结合,以提高3D目标检测的性能。PointFusion通过将3D点投影到图像平面上,提取对应的2D图像特征,并将其拼接到每个3D点的特征中。这种早期融合方式可以让网络从两种模态中同时学习有用的信息。VoxelFusion则是在Voxel特征编码层进行融合,即将图像特征汇聚到对应的voxel中,与voxel的点云特征拼接。这种较晚的融合方式可以扩展到没有点的voxel。Complexer-YOLO[50]优化了Enet模型,先将点云数据体素化;同时利用ENet对RGB图像进行语义分割,再将语义信息的点投影到体素化点云上,从而生成带语义信息的体素化点云,最终使用Complex YOLO模型对目标进行预测和跟踪。PI-RCNN[51]提出了一种二维语义分割效果在3D点上结合的方法。PointPainting[52] 将每个激光雷达点投影到图像语义分割网络的输出中,并将通道方向的激活与每个激光雷达点的强度测量连接起来。然后,级联的点云可用于任何激光雷达检测方法,无论是鸟瞰图还是正视图。PointPainting解决了一些前融合的缺点:不对3D检测架构增加任何限制,不会遭受特征或深度模糊的困扰,不需要计算伪点云,也没有限制最大召回率。
深度融合,也叫特征级融合。MAFF-Net[54] 提出了 PointAttentionFusion 和 DenseAttentionFusion:两种端到端可训练的单级多模态特征融合方法,用于自适应地结合 RGB 和点云模态。MVAF-Net[55]提出了一种单级多视角融合框架,将激光雷达鸟瞰图、激光雷达测距视图和相机视图图像作为三维物体检测的输入。还设计了一个注意力点式融合(APF)模块来估计数据来源的重要性,并使用注意力点式加权(APW)模块帮助网络学习结构信息和点的特征权重。EPNet[56]提出了一种新颖的融合模块,以点对点的方式增强点云特征与语义图像特征,而无需任何图像标注。此外,还提出了一致性加强损失模块,以鼓励定位和分类置信度的一致性。最终使用EPNet整合这两个模块。RoIFusion[57]提出了一种融合算法,通过将点云中的一组3D感兴趣区域(RoI)投影到相应RGB图像的2D RoI。

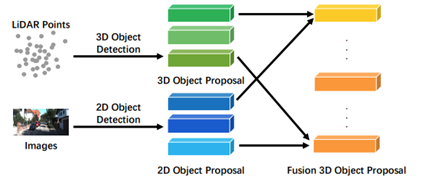
也叫目标级融合。CLOCs[58] 提供了一个低复杂度的多模态融合框架,显著提高了单一模态检测器的性能。在任一2D和任一3D检测器的非极大值抑制之前操作组合输出的候选对象,并训练利用它们的几何和语义一致性来产生更准确的最终3D和2D检测结果。Fast-CLOCs[59]在任一3D检测器的非极大值抑制之前的输出候选上操作,并添加了一个轻量级的由3D检测器引导的2D图像检测器,以从图像域提取视觉特征,从而显著提高3D检测。3D检测候选作为提案与提出的图像检测器共享,以大幅降低网络复杂度。Snow-CLOCs[60]是一种专门针对雪天条件的多模态对象检测算法。在图像检测中,整合InceptionNeXt[80]网络来改进YOLOv5算法,增强特征提取,并使用Wise-IoU[81]算法来减少对高质量数据的依赖。对于激光雷达点云检测,在SECOND[82]算法的基础上采用DROR滤波器去除噪声,提高检测精度。最终将摄像头和激光雷达的检测结果合并为一个统一的检测集,使用稀疏张量表示,并通过2D卷积神经网络提取特征,以实现对象检测和定位。
其他端到端方法
Mask R-CNN[83]在Fast R-CNN的基础上增加了一个预测物体掩码的分支,这种方法被命名为掩码R-CNN,能够在检测图像中目标2D边界框的同时为每个实例生成高质量的分割掩码,不过这个模型的运行速度只有5FPS。MultiNet[84]提出了一种统一架构同时进行分类、检测和语义分割这三个任务的方法,编码器由这三个任务共享。同时将推理速度提升到了23FPS,拥有不错的实时性。Occupancy Networks[85]是一种新的3D重建表征,占据网络将3D表面隐式的表示为深度神经网络分类器的连续决策边界,使用此方法可以重建各种输入类型的3D点云并生成高质量的网格。DLT-Net[86]提出的统一神经网络,可以同时检测可行驶区域、车道线和道路上的常见对象。DLT-Net没有在解码器中将这三种任务分开,而是在三个子任务的解码器间共享上下文张量。这种特殊的设计使得不同子任务间的训练可以共享信息。Dirty Pixels[87]使用一种可微分架构,这个架构会联合执行降噪、去毛刺和图像分类等操作,但是不存在任何图像质量的中间损耗,让模型在弱光条件下的感知能力大大提高。YOLOP[88]使用一个由用于特征提取的编码器和三个用于处理特定任务的解码器组成的网络,同时执行道路对象检测、车道线检测和可行驶区域分割,在 BDD100K 数据集上,YOLOP在这三项感知任务上首次达到了实时性上的先进水平。BEV-TP[89]提出了一种新型框架,该框架是一种基于视觉上下文引导的中心transformer网络,用于同时进行3D目标检测和目标轨迹预测。BEV-TP利用连续多视角图像中的视觉信息和高清语义地图中的上下文信息预测3D物体中心点,然后通过注意力机制将物体中心位置用于查询视觉特征和上下文特征。最终用多重回归头执行3D包围框推理和轨迹预测。这种方法实现了可微分和简单高效的端到端感知框架。
实验和评估
数据集
数据集对自动驾驶中感知系统的开发和优化至关重要,它们能够提供丰富的多模态感知数据来提高系统的可靠性和鲁棒性,确保系统能有效的感知和理解周围环境。下表列出了自动驾驶领域最常见的数据集,按照[90]中的方法提出的评价指标,按照影响指数排序:
评价指标
本节将着重介绍自动驾驶领域的感知模型常见的评价指标。
IoU交并比,定义为两个矩形框交集的面积与并集的面积之比, 用来描述两个框之间的重合度,如果是3D检测模型,3D-IoU则为两个长方体体积的交并比,计算方法:
Recall召回率(查全率),表示真值给出的所有正样本中被检测器检测到的百分比,用于评估检测器对所有待检测目标的检测覆盖率:
Precision精确度(查准率),表示检测器给出所有正样本中正确的百分比,用于评估检测器在检测成功基础上的正确率:
上述两个公式中的TP等内容解释如下:
TP (True Positive,真阳性):检测器给出正样本,事实上也是正样本,即正确检测到目标
TN (True Negative,真阴性):检测器给出负样本,事实上也是负样本,即正确检测到非目标
FP (False Positive,假阳性):检测器给出正样本,事实上却是负样本,即误检测
FN (False Negative,假阴性):检测器给出负样本,事实上却是正样本,即漏检测
PR曲线,Precision-Recall 曲线,即以 Precision 为纵坐标、Recall 为横坐标所作的曲线,用来评估模型性能。Precision 值和 Recall 值越大越好,所以 PR 曲线越往右上角凸越好。
AP(Average Precision)平均精度,即 PR 曲线下的面积,用来衡量算法在单个类别上的平均精度。AP 值越高,表示对这个类别的检测精度越高,一般使用近似或者插值方法计算AP:
这里N为数据总量,k为每个样本点的索引,\Delta r(k)= r(k) -r(k-1)
mAP平均精度均值,即多个类别的 AP 的平均值,用来衡量算法在所有类别上的整体精度表现。mAP 值是目标检测算法最重要的评估指标之一。
F1 Score是统计学中用来衡量二分类(或多任务二分类)模型精确度的一种指标。它同时兼顾了分类模型的准确率和召回率。F1分数可以看作是模型准确率和召回率的一种加权平均,它的最大值是1,最小值是0,值越大意味着模型越好。
发展和未来趋势
视觉感知
在恶劣天气下,视觉感知准确性下降的问题仍然存在。因此,探索新型传感器以替代传统摄像头是未来的趋势。此外,视觉传感器与其他传感器的融合也是发展趋势。探索新的传感器融合方案是提高视觉鲁棒性和准确性的研究方向。
对于深度估计,双目图像需要使用立体匹配来进行像素点对应和视差计算,因此计算复杂度较高。此外,单目深度图像处理严重依赖大规模标注数据集,对于未标注的目标识别效果不佳。因此,无监督学习仍然是未来的研究方向。此外,深度估计误差随着距离的增加而增加。由于难以区分远距离离散图像的像素,因此在道路车辆间相互遮挡情况下的目标识别和测距也会受到影响。因此,复杂场景中的长距离测距将继续是未来研究的热点。一种改进方法是通过提高图像的空间分辨率或增加基线长度来增加视差范围。对于背景误差的减少,当前的趋势是通过对语义分割计算元素值并与阈值进行比较,或结合几何先验进行估计,并将相机采集的当前状态和未来分布输入卷积网络进行推理。
对于自动驾驶来说,实时性非常重要。为了快速识别感兴趣区域,需要高速图像分割,因此,处理速度需要进一步提高。目前,距离测量的方法依赖于深度神经网络来实现高精度。这意味着模型具有大量的参数和缓慢的推理速度。对于效率问题,常用的方法是进行模型剪枝或蒸馏,使网络拥有更少的参数,从而解决性能问题。与在已经训练好的模型上处理相比,轻量化模型设计更为合理。因此,轻量化网络是未来的趋势。
激光雷达感知
对于激光雷达感知,目前主要存在的限制是运行的嵌入式平台算力不足,点云的上下文信息不够充足以及缺乏弱监督和无监督训练方式。
由于自动驾驶车辆嵌入式平台在内存和计算设施方面的限制,有效且高效的深度学习架构对于自动化自动驾驶系统的广泛应用至关重要。尽管在3D深度学习模型方面已有显著改进,一些有限的模型能够实现实时分割、检测和分类任务。在未来研究应专注于轻量级和紧凑架构的设计。
由于点云的稀疏性和扫描对象的完整性不足,对象的详细上下文信息并未得到充分利用。例如,交通标志中的语义上下文对于自动驾驶车辆的导航是至关重要的线索,但现有的深度模型无法从点云中完全提取此类信息。尽管多尺度特征融合方法在上下文信息提取方面已显示出显著的改进。此外,生成对抗网络(GAN)可用于提高3D点云的完整性。因此在未来,这些框架应该尝试以端到端可训练的方式解决上下文信息提取的稀疏性和不完整性问题。
现有的最先进的深度模型通常是在监督模式下构建的,使用带有3D对象边界框或逐点分割掩码的标注数据。然而,完全监督模型存在一些局限性。首先是高质量、大规模和大量通用对象数据集和基准的可用性有限。其次是完全监督模型的泛化能力,对未见或未经训练的对象不具鲁棒性。在未来应开发弱监督或无监督学习得训练方法以提高模型的泛化能力并解决数据缺失问题。
多传感器感知
对于多传感器融合感知,存在数据对齐和信息丢失的问题。此外,扁平化的融合操作也阻碍了感知性能的进一步提升。
相机和激光雷达的内在和外在属性彼此差异很大。两种模态的数据都需要在新坐标系下重新组织。传统的早期和深度融合方法利用外在校准矩阵将所有激光雷达点云直接投影到相应的像素。然而由于噪声得存在,这种点云对像素的对齐不够准确。此外,在输入和特征空间转换过程中还存在一些其他信息丢失。通常降维操作的投影必然会导致大量信息丢失,例如将3D激光雷达点云映射到2D BEV图像。因此,未来的工作可以通过将两种模态数据映射到专门为融合设计的高维表示,更有效地利用原始数据,减少信息丢失。
现有方法缺乏有效利用来自多个维度和表征的信息。它们大多关注前视图的多模态数据的单帧数据。因此,其他有意义的信息如语义、空间和场景上下文信息被过度忽视。因此,未来的研究可以通过各种下游任务(如检测车道、交通灯和标志)共同构建城市景观场景的完整语义理解框架,以协助感知任务的性能。此外,当前的感知任务主要依赖于单帧,忽略了时间信息。因此,未来的工作可能会更深入地利用时间、上下文和空间信息,通过创新的模型设计,对连续帧进行利用。
参考文献
[1] P. S. Chib and P. Singh, "Recent advancements in end-to-end autonomous driving using deep learning: A survey," IEEE Transactions on Intelligent Vehicles, 2023.
[2] L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger, and H. Li, "End-to-end autonomous driving: Challenges and frontiers," IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024.
[3] D. G. Lowe, "Object recognition from local scale-invariant features," in Proceedings of the seventh IEEE international conference on computer vision, 1999, vol. 2: Ieee, pp. 1150-1157.
[4] P. Viola and M. Jones, "Rapid object detection using a boosted cascade of simple features," in Proceedings of the 2001 IEEE computer society conference on computer vision and pattern recognition. CVPR 2001, 2001, vol. 1: Ieee, pp. I-I.
[5] N. Dalal and B. Triggs, "Histograms of oriented gradients for human detection," in 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR'05), 2005, vol. 1: Ieee, pp. 886-893.
[6] R. Girshick, J. Donahue, T. Darrell, and J. Malik, "Rich feature hierarchies for accurate object detection and semantic segmentation," in Proceedings of the IEEE conference on computer vision and pattern recognition, 2014, pp. 580-587.
[7] R. Girshick, "Fast r-cnn," in Proceedings of the IEEE international conference on computer vision, 2015, pp. 1440-1448.
[8] S. Ren, K. He, R. Girshick, and J. Sun, "Faster R-CNN: Towards real-time object detection with region proposal networks," IEEE transactions on pattern analysis and machine intelligence, vol. 39, no. 6, pp. 1137-1149, 2016.
[9] J. Dai, Y. Li, K. He, and J. Sun, "R-fcn: Object detection via region-based fully convolutional networks," Advances in neural information processing systems, vol. 29, 2016.
[10] W. Liu et al., "Ssd: Single shot multibox detector," in Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14, 2016: Springer, pp. 21-37.
[11] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, "You only look once: Unified, real-time object detection," in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 779-788.
[12] A. Wang et al., "Yolov10: Real-time end-to-end object detection," arXiv preprint arXiv:2405.14458, 2024.
[13] O. Ronneberger, P. Fischer, and T. Brox, "U-net: Convolutional networks for biomedical image segmentation," in Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18, 2015: Springer, pp. 234-241.
[14] V. Badrinarayanan, A. Kendall, and R. Cipolla, "Segnet: A deep convolutional encoder-decoder architecture for image segmentation," IEEE transactions on pattern analysis and machine intelligence, vol. 39, no. 12, pp. 2481-2495, 2017.
[15] B. Li, J. Zang, and J. Cao, "Efficient residual neural network for semantic segmentation," Pattern Recognition and Image Analysis, vol. 31, no. 2, pp. 212-220, 2021.
[16] Z. Wang, W. Ren, and Q. Qiu, "Lanenet: Real-time lane detection networks for autonomous driving," arXiv preprint arXiv:1807.01726, 2018.
[17] Z. Qin, H. Wang, and X. Li, "Ultra fast structure-aware deep lane detection," in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXIV 16, 2020: Springer, pp. 276-291.
[18] L. Tabelini, R. Berriel, T. M. Paixao, C. Badue, A. F. De Souza, and T. Oliveira-Santos, "Keep your eyes on the lane: Real-time attention-guided lane detection," in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 294-302.
[19] J. Wang et al., "A keypoint-based global association network for lane detection," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 1392-1401.
[20] A. Naiden, V. Paunescu, G. Kim, B. Jeon, and M. Leordeanu, Shift R-CNN: Deep Monocular 3D Object Detection With Closed-Form Geometric Constraints. 2019, pp. 61-65.
[21] W. Bao, B. Xu, and Z. Chen, "Monofenet: Monocular 3d object detection with feature enhancement networks," IEEE Transactions on Image Processing, vol. 29, pp. 2753-2765, 2019.
[22] W. Peng, H. Pan, H. Liu, and Y. Sun, "Ida-3d: Instance-depth-aware 3d object detection from stereo vision for autonomous driving," in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 13015-13024.
[23] J. Sun et al., "Disp r-cnn: Stereo 3d object detection via shape prior guided instance disparity estimation," in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 10548-10557.
[24] Z. Xu et al., "Zoomnet: Part-aware adaptive zooming neural network for 3d object detection," in Proceedings of the AAAI Conference on Artificial Intelligence, 2020, vol. 34, no. 07, pp. 12557-12564.
[25] N. Mayer et al., "A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation," in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 4040-4048.
[26] C. Godard, O. Mac Aodha, and G. J. Brostow, "Unsupervised monocular depth estimation with left-right consistency," in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 270-279.
[27] H. Fu, M. Gong, C. Wang, K. Batmanghelich, and D. Tao, "Deep ordinal regression network for monocular depth estimation," in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 2002-2011.
[28] F. Manhardt, W. Kehl, and A. Gaidon, "Roi-10d: Monocular lifting of 2d detection to 6d pose and metric shape," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 2069-2078.
[29] X. Ma, Z. Wang, H. Li, P. Zhang, W. Ouyang, and X. Fan, "Accurate monocular 3d object detection via color-embedded 3d reconstruction for autonomous driving," in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6851-6860.
[30] X. Weng and K. Kitani, "Monocular 3d object detection with pseudo-lidar point cloud," in Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 2019, pp. 0-0.
[31] M. Ding et al., "Learning depth-guided convolutions for monocular 3d object detection," in Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition workshops, 2020, pp. 1000-1001.
[32] L. Wang et al., "Depth-conditioned dynamic message propagation for monocular 3d object detection," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 454-463.
[33] X. Zhou, D. Wang, and P. Krähenbühl, "Objects as points," arXiv preprint arXiv:1904.07850, 2019.
[34] Y. Chen, L. Tai, K. Sun, and M. Li, "Monopair: Monocular 3d object detection using pairwise spatial relationships," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 12093-12102.
[35] X. Ma et al., "Delving into localization errors for monocular 3d object detection," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 4721-4730.
[36] Z. Liu, Z. Wu, and R. Tóth, "Smoke: Single-stage monocular 3d object detection via keypoint estimation," in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 2020, pp. 996-997.
[37] P. Li, H. Zhao, P. Liu, and F. Cao, "Rtm3d: Real-time monocular 3d detection from object keypoints for autonomous driving," in European Conference on Computer Vision, 2020: Springer, pp. 644-660.
[38] Y. Lu et al., "Geometry uncertainty projection network for monocular 3d object detection," in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 3111-3121.
[39] Y. Zhang, J. Lu, and J. Zhou, "Objects are different: Flexible monocular 3d object detection," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 3289-3298.
[40] Z. Liu, D. Zhou, F. Lu, J. Fang, and L. Zhang, "Autoshape: Real-time shape-aware monocular 3d object detection," in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15641-15650.
[41] J. Beltrán, C. Guindel, F. M. Moreno, D. Cruzado, F. Garcia, and A. De La Escalera, "Birdnet: a 3d object detection framework from lidar information," in 2018 21st International Conference on Intelligent Transportation Systems (ITSC), 2018: IEEE, pp. 3517-3523.
[42] A. Barrera, C. Guindel, J. Beltrán, and F. García, "Birdnet+: End-to-end 3d object detection in lidar bird’s eye view," in 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), 2020: IEEE, pp. 1-6.
[43] Y. Zhou and O. Tuzel, "Voxelnet: End-to-end learning for point cloud based 3d object detection," in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4490-4499.
[44] Y. Chen, J. Liu, X. Zhang, X. Qi, and J. Jia, "Voxelnext: Fully sparse voxelnet for 3d object detection and tracking," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 21674-21683.
[45] C. R. Qi, H. Su, K. Mo, and L. J. Guibas, "Pointnet: Deep learning on point sets for 3d classification and segmentation," in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 652-660.
[46] C. R. Qi, L. Yi, H. Su, and L. J. Guibas, "Pointnet++: Deep hierarchical feature learning on point sets in a metric space," Advances in neural information processing systems, vol. 30, 2017.
[47] S. Shi, X. Wang, and H. Li, "Pointrcnn: 3d object proposal generation and detection from point cloud," in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 770-779.
[48] C. Xiang et al., "Multi-sensor fusion and cooperative perception for autonomous driving: A review," IEEE Intelligent Transportation Systems Magazine, 2023.
[49] V. A. Sindagi, Y. Zhou, and O. Tuzel, "Mvx-net: Multimodal voxelnet for 3d object detection," in 2019 International Conference on Robotics and Automation (ICRA), 2019: IEEE, pp. 7276-7282.
[50] M. Simon et al., "Complexer-yolo: Real-time 3d object detection and tracking on semantic point clouds," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2019, pp. 0-0.
[51] L. Xie et al., "PI-RCNN: An efficient multi-sensor 3D object detector with point-based attentive cont-conv fusion module," in Proceedings of the AAAI conference on artificial intelligence, 2020, vol. 34, no. 07, pp. 12460-12467.
[52] S. Vora, A. H. Lang, B. Helou, and O. Beijbom, "Pointpainting: Sequential fusion for 3d object detection," in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 4604-4612.
[53] L.-H. Wen and K.-H. Jo, "Fast and accurate 3D object detection for lidar-camera-based autonomous vehicles using one shared voxel-based backbone," IEEE access, vol. 9, pp. 22080-22089, 2021.
[54] Z. Zhang et al., "Maff-net: Filter false positive for 3d vehicle detection with multi-modal adaptive feature fusion," in 2022 IEEE 25th International conference on intelligent transportation systems (ITSC), 2022: IEEE, pp. 369-376.
[55] G. Wang, B. Tian, Y. Zhang, L. Chen, D. Cao, and J. Wu, "Multi-view adaptive fusion network for 3D object detection," arXiv preprint arXiv:2011.00652, 2020.
[56] T. Huang, Z. Liu, X. Chen, and X. Bai, "Epnet: Enhancing point features with image semantics for 3d object detection," in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XV 16, 2020: Springer, pp. 35-52.
[57] C. Chen, L. Z. Fragonara, and A. Tsourdos, "RoIFusion: 3D object detection from LiDAR and vision," IEEE Access, vol. 9, pp. 51710-51721, 2021.
[58] S. Pang, D. Morris, and H. Radha, "CLOCs: Camera-LiDAR object candidates fusion for 3D object detection," in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020: IEEE, pp. 10386-10393.
[59] S. Pang, D. Morris, and H. Radha, "Fast-CLOCs: Fast camera-LiDAR object candidates fusion for 3D object detection," in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022, pp. 187-196.
[60] X. Fan, D. Xiao, Q. Li, and R. Gong, "Snow-CLOCs: Camera-LiDAR Object Candidate Fusion for 3D Object Detection in Snowy Conditions," Sensors, vol. 24, no. 13, p. 4158, 2024.
[61] Matlab. "Getting Started with R-CNN, Fast R-CNN, and Faster R-CNN." https://www.mathworks.com/help/vision/ug/getting-started-with-r-cnn-fast-r-cnn-and-faster-r-cnn.html (accessed Aug.30, 2024).
[62] J. Redmon and A. Farhadi, "YOLO9000: better, faster, stronger," in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 7263-7271.
[63] J. Redmon, "Yolov3: An incremental improvement," arXiv preprint arXiv:1804.02767, 2018.
[64] A. Bochkovskiy, C.-Y. Wang, and H.-Y. M. Liao, "Yolov4: Optimal speed and accuracy of object detection," arXiv preprint arXiv:2004.10934, 2020.
[65] G. J. and et al. "ultralytics/yolov5: v3.1." Zenodo. https://doi.org/10.5281/zenodo.4154370 (accessed Aug 31, 2024).
[66] C. Li et al., "YOLOv6: A single-stage object detection framework for industrial applications," arXiv preprint arXiv:2209.02976, 2022.
[67] X. Ding, X. Zhang, N. Ma, J. Han, G. Ding, and J. Sun, "Repvgg: Making vgg-style convnets great again," in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 13733-13742.
[68] C.-Y. Wang, A. Bochkovskiy, and H.-Y. M. Liao, "YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors," in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 7464-7475.
[69] G. Jocher, A. Chaurasia, and J. Qiu, Ultralytics YOLO.
[70] C.-Y. Wang, I.-H. Yeh, and H.-Y. M. Liao, "Yolov9: Learning what you want to learn using programmable gradient information," arXiv preprint arXiv:2402.13616, 2024.
[71] M. A. R. Alif and M. Hussain, "YOLOv1 to YOLOv10: A comprehensive review of YOLO variants and their application in the agricultural domain," arXiv preprint arXiv:2406.10139, 2024.
[72] Z. Qin, J. Wang, and Y. Lu, "Monogrnet: A geometric reasoning network for monocular 3d object localization," in Proceedings of the AAAI conference on artificial intelligence, 2019, vol. 33, no. 01, pp. 8851-8858.
[73] G. Brazil and X. Liu, "M3d-rpn: Monocular 3d region proposal network for object detection," in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9287-9296.
[74] H. Chen, Y. Huang, W. Tian, Z. Gao, and L. Xiong, "Monorun: Monocular 3d object detection by reconstruction and uncertainty propagation," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 10379-10388.
[75] S. Luo, H. Dai, L. Shao, and Y. Ding, "M3dssd: Monocular 3d single stage object detector," in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 6145-6154.
[76] K.-C. Huang, T.-H. Wu, H.-T. Su, and W. H. Hsu, "Monodtr: Monocular 3d object detection with depth-aware transformer," in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 4012-4021.
[77] R. Zhang et al., "MonoDETR: Depth-guided transformer for monocular 3D object detection," in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 9155-9166.
[78] L. Yan, P. Yan, S. Xiong, X. Xiang, and Y. Tan, "MonoCD: Monocular 3D Object Detection with Complementary Depths," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 10248-10257.
[79] K. Huang, B. Shi, X. Li, X. Li, S. Huang, and Y. Li, "Multi-modal sensor fusion for auto driving perception: A survey," arXiv preprint arXiv:2202.02703, 2022.
[80] W. Yu, P. Zhou, S. Yan, and X. Wang, "Inceptionnext: When inception meets convnext," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 5672-5683.
[81] Z. Tong, Y. Chen, Z. Xu, and R. Yu, "Wise-IoU: bounding box regression loss with dynamic focusing mechanism," arXiv preprint arXiv:2301.10051, 2023.
[82] Y. Yan, Y. Mao, and B. Li, "Second: Sparsely embedded convolutional detection," Sensors, vol. 18, no. 10, p. 3337, 2018.
[83] K. He, G. Gkioxari, P. Dollár, and R. Girshick, "Mask r-cnn," in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2961-2969.
[84] M. Teichmann, M. Weber, M. Zoellner, R. Cipolla, and R. Urtasun, "Multinet: Real-time joint semantic reasoning for autonomous driving," in 2018 IEEE intelligent vehicles symposium (IV), 2018: IEEE, pp. 1013-1020.
[85] L. Mescheder, M. Oechsle, M. Niemeyer, S. Nowozin, and A. Geiger, "Occupancy Networks: Learning 3D Reconstruction in Function Space," in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 15-20 June 2019 2019, pp. 4455-4465, doi: 10.1109/CVPR.2019.00459.
[86] Y. Qian, J. M. Dolan, and M. Yang, "DLT-Net: Joint Detection of Drivable Areas, Lane Lines, and Traffic Objects," IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 11, pp. 4670-4679, 2020, doi: 10.1109/TITS.2019.2943777.
[87] S. Diamond, V. Sitzmann, F. Julca-Aguilar, S. Boyd, G. Wetzstein, and F. Heide, "Dirty Pixels: Towards End-to-end Image Processing and Perception," ACM Trans. Graph., vol. 40, no. 3, p. Article 23, 2021, doi: 10.1145/3446918.
[88] D. Wu et al., "YOLOP: You Only Look Once for Panoptic Driving Perception," Machine Intelligence Research, vol. 19, no. 6, pp. 550-562, 2022, doi: 10.1007/s11633-022-1339-y.
[89] B. Lang, X. Li, and M. C. Chuah, "BEV-TP: End-to-End Visual Perception and Trajectory Prediction for Autonomous Driving," IEEE Transactions on Intelligent Transportation Systems, pp. 1-10, 2024, doi: 10.1109/TITS.2024.3433591.
[90] M. Liu et al., "A survey on autonomous driving datasets: Data statistic, annotation, and outlook," arXiv preprint arXiv:2401.01454, 2024.
评论