

前言
单目相机的目标距离估计本身就已经充满了挑战,那么目标的(相对)速度估计也必然是十分困难...
目前单目相机的相对速度估计算法可以分成两类:传统方法和深度学习方法。没错,什么任务都可以深度学习。
传统方法中,最经典的是Mobileye在2003年的一篇论文中提出的算法。这个算法包含目标距离和速度的估计方法。
传统方法
Mobileye方法
ME方法主要依据2D目标检测的BBox的变化。BBox可以通过SSD,R-CNN,YOLO等深度学习模型得到。
其次需要目标跟踪,在道路多目标场景下,想要对目标A进行速度估计,需要在连续的画面中跟踪目标A。
在 单目相机的测距 - The Distance Estimation of Monocular Camera - FunnyWii's Zone 文章中,介绍了速度的计算方法。
在使用ME的算法获取了目标的XY坐标(X右Y前)之后,可以将相对速度表示为两次测量时间点的距离除以时间差。以Y轴方向上的速度为例:
这里的\Delta Y是两个时间点在Y方向上的距离变化量,\Delta t是时间差,这个时间差通常在程序中,根据几帧之间的运行时间自动计算。
由距离估计的公式可知,两个时间点t_1和t_2的距离都存在误差,因此\Delta Y肯定也是不准的。因此引入了目标尺寸变化量计算相对速度。W为车辆实际物理宽度,w和w'是两个时间点在图像上的车辆宽度,再根据小孔成像原理:
然后根据Y = \cfrac {fH}{y}可以得到:
令\cfrac{w-w'}{w'} = s,可以得到:
在论文[PDF] Vision-based ACC with a single camera: bounds on range and range rate accuracy | Semantic Scholar 中,假设距离Y为完全准确的前提下,得到相对速度的误差:
其中s_{err}描述的是BBox的像素误差。0.1的像素误差的影响取决于目标BBox在图像中的大小(很明显100像素宽度和1像素宽度,0.1的像素误差影响不同)。作者先定义了一个尺度误差s_{acc},用像素误差s_{err}除以像素宽度w,可以理解为误差比例:
为方便理解,本文将论文中的Z,也就是前向距离,全部替换为东北天坐标系前向的Y,单目相机的测距 - The Distance Estimation of Monocular Camera - FunnyWii's Zone 没有修改,仍然使用Z(懒
根据 公式 1.6 的速度误差,可以发现:
相对速度误差v_{err}与速度v本身无关
相对速度误差v_{err}随着距离Y二次方增长
时间间隔\Delta t越长,相对速度误差v_{err}越小
相机FOV越小,也就是焦距f越长,相对速度误差v_{err}越小
参考线方法
和ME算法一样,基于道路平坦和目标位于地面的假设。这种方法是找到像素坐标转换为世界坐标的比例因子。
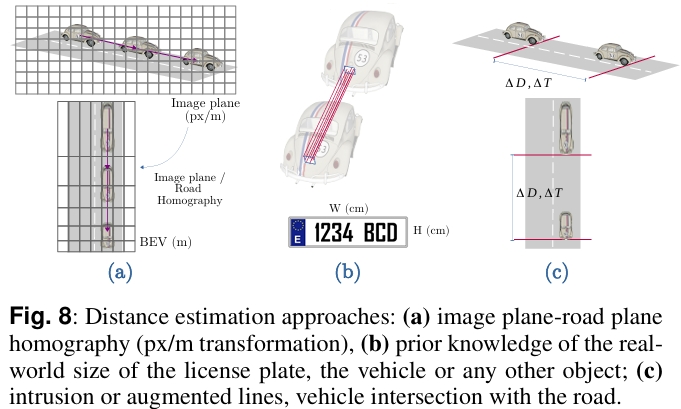
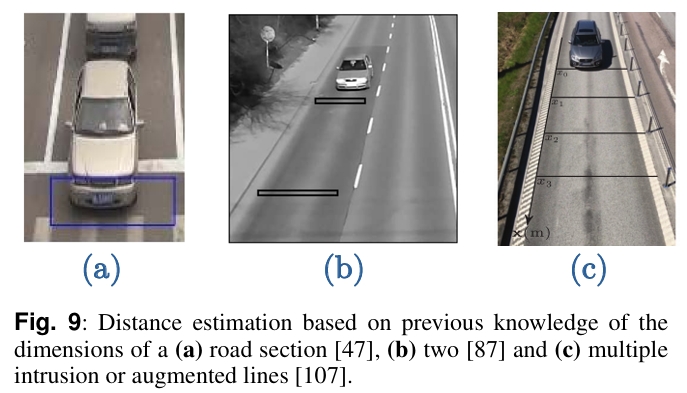
方法一:这种方法不需要对摄像头进行标定,只需要测量道路上两条或者多条参考线之间的实际距离(m)。所有车辆目标穿越参考线时,相对相机的距离都是相同的。
方法二:基于单向计算的方法,即将道路从3D空间投影到2D空间,也就是我们常说的BEV,BEV中的像素位移(pixel)可以转换为真实3D世界中的距离变化(m)。
方法三:对于路端相机,可以根据车牌尺寸的变化,来计算车辆的位置。相比使用车辆宽度作为先验的方法计算位置,车牌尺寸更加统一,所以计算得到的目标位置会更加准确。
最后可以根据时间间隔计算目标的速度。
深度学习方法
单目相机可以通过深度图获取目标的相对深度,相对深度和与目标的相对距离是两回事,参见 单目相机的深度图,以及绝对深度和相对深度 - FunnyWii's Zone 。同样也可以通过深度学习方法获取与目标的相对速度...
基于ME的速度估计,算法原理简单,但存在缺陷:
路面不平,会导致目标位置计算出现偏移,导致速度计算也出现偏移。
BBox像素抖动,会导致速度突变。
在国内,无论是论文期刊,还是技术博客,使用的最多的就是传统方法,尤其是技术博客上,有一个算一个还都是卖课的...所以目前来看,国内在使用深度学习方法进行目标速度估计的探索上,还是一片蓝海。
以论文 [1802.07094] Camera-based vehicle velocity estimation from monocular video 为例。
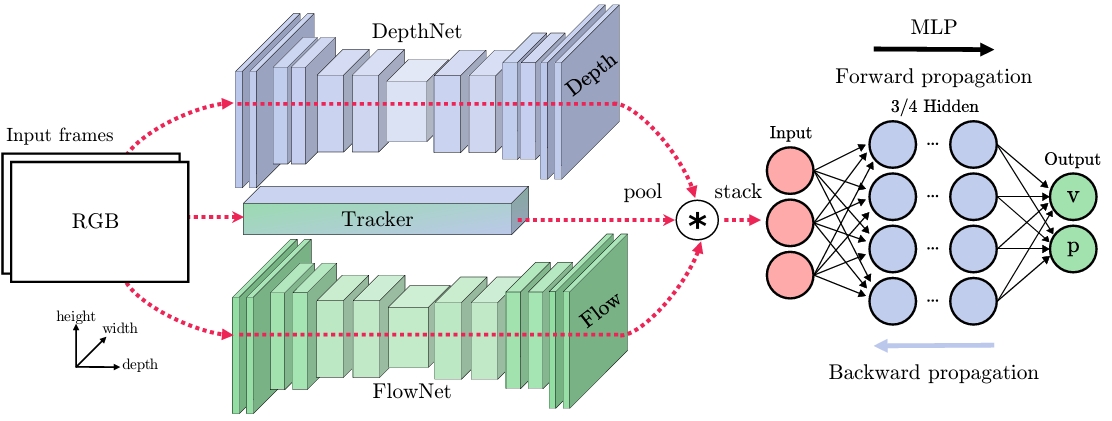
论文提出了一个二阶段模型,第一阶段主要是提取相关特征,第二阶段使用多层感知机MLP来回归车辆目标的位置和速度。
特征提取阶段
将RGB图像转换为三种特征:车辆轨迹、深度和运动。车辆轨迹是2D对象BBox随时间变化的轨迹。深度是单目相机的视差估计。运动信息使用连续帧的光流估计。
对于车辆轨迹跟踪,使用了Median Flow和MIL两种跟踪器,这两种tracker在OpenCV中都有API。Median Flow的优势是能在轨迹上调整BBox并提供一个稳定的BBox,对于速度估计,这点非常重要。当遮挡导致tracker不稳定进而导致Median Flow失效时,MIL就会介入,替换掉失败的跟踪。
对于深度估计,使用的是 [1609.03677] Unsupervised Monocular Depth Estimation with Left-Right Consistency 论文中提到的方法。目前,使用单目相机场景的数据获取真实的绝对深度数据是不可行的。这种方法将训练过程中的深度估计看作一个图像重建问题。使用一个标定过的双目相机,通过学习一种从一个相机重建另一个图像的功能,就能了解场景的3D形状。具体来说,训练时,左目图像I_l和右目图像I_r不用来直接预测深度,而是尝试找到一个稠密的关联场d_r,关联场应用于一侧图像时,可以重建另一侧图像。这种方法仅限近距离。
对于运动信息,采用FlowNet2提取稠密光流图来获取运动信息。FlowNet2将光流估计视为一个视觉学习问题,它的CNN是在两个堆叠的输入帧上训练的。
此外,国内的一些主机厂,针对量产车型,也有使用BEV模型的方法,将6个相机的图像作为输入,通过加入多任务,模型会输出3D检测结果和车道线检测结果。3D检测结果中也包含了目标的位置和速度。不过这种方法使用的数据集非常贵,小公司和个人开发者就没有尝试的必要了。
Ground Truth的获取
汽车速度计
雷达
GPS
光栅
路面传感器
参考文章
[1] Deep Convolutional Networks for Monocular Velocity Estimation | by Sam Black | Towards Data Science
[2] [2101.06159] Vision-based Vehicle Speed Estimation: A Survey。
评论