

写在前面
单目相机测距是怎么回事呢?单目相机相信大家都很熟悉,但是测距是怎么回事呢?下面就让小编带大家一起了解吧。
单目相机测距,其实就是测距了。那么单目相机为什么会测距,相信大家都很好奇是怎么回事。大家可能会感到很惊讶,单目相机怎么会测距呢?但事实就是这样,小编也感到非常惊讶。那么这就是关于单目相机测距的事情了,大家有没有觉得很神奇呢?
看了今天的内容,大家有什么想法呢?欢迎在评论区告诉小编一起讨论哦。
对不起。
废话有点多。
因为刚刚领导告诉我:不想给我配显卡。
没显卡你玩什么深度学习啊?
正文
在ADAS中,测距这项需求一般源于自适应巡航控制(ACC),ACC是纵向距离控制,需要能够发现目标,测量相对速度和相对距离,预测目标的运动轨迹。
对于测距而言,最直接的方法是采用毫米波雷达、激光雷达和双目相机。那为什么要用单目呢?都是因为想他妈的省钱。但是单目相机存在两个问题:
- 深度丢失。单目相机获取到的图像从3D世界坐标系转换到2D像素坐标系后,面临着深度丢失的问题。双目相机就不存在这个问题,因此只有一个眼睛的人不能开车,因为获取目标距离的能力下降。
- 精度问题。目前用单目相机测距的方案,要么依赖透视法则(小孔成像原理);要么完全依赖深度学习,也就是嗯学,不仅靠深度学习检测目标,还让深度学习告诉你距离。
单目相机测距的思路
- 利用目标与道路平面的接地点,局限是相机俯仰角会造成误差。
- 利用目标的平均高度、宽度,局限是不同目标的尺寸差异大,会造成误差。
- 利用尺度变化估计TTC (Time To Collision),局限是不算严格的测距。
- 利用运动立体(Motion Stereo),属于立体视觉,局限是目标或相机应该是静止的,而且精度低。
MoibleEye
ME测距
MoibleEye 算法利用图像中车与路面的接触点进行测距,基于以下两种假设:
- 道路是平的
- 相机光轴与路面平行
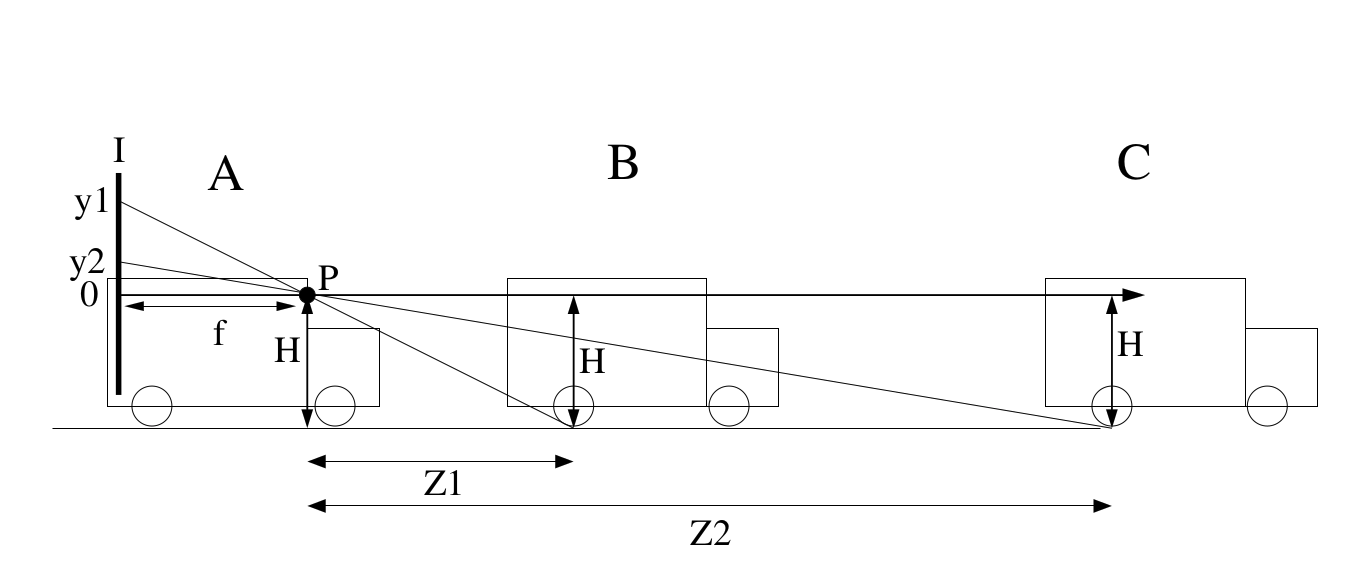
图中P为相机所在位置。 f 为焦距, H 为相机高度,投影到图像上的高度 y
A 为安装相机的车辆, B C 为路面上目标车辆。
检测到前车与路面的接触点,这个接触点一般可以认为是深度学习(比如YOLO)检测出来的bbox的底部框线,然后就可以计算距离了:
测距误差
假设地面接触点的像素误差为 n 个piexl,那么距离误差为:
一般来说,fH >>nZ,因此:
可见测距误差是随着距离而二次方地增长,而误差比例则随着距离线性增长。
相对速度
相对速度可以表示为两次测量时间点的距离除时间差:
既然两个时间点测量的距离 Z 都存在噪声,那么距离差也一定不会是准确的。因此可以使用目标尺寸变化计算相对速度。 W 为车辆实际宽度,w 和 w' 为两个时间点的在图像上的车辆宽度,由小孔成像原理可得:
因此:
定义其中的
可以得到
即根据两个时间点 t_1,t_2 像素的检测宽度和 t_1 时刻的距离 Z 即可的到相对速度。
CNN测距
单目相机是没有办法恢复出来绝对尺度,只能依靠先验知识。
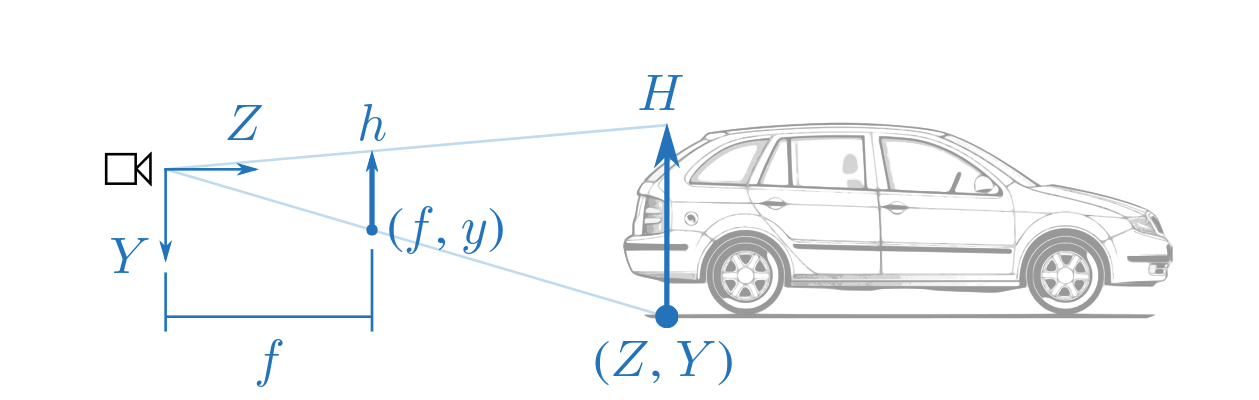
- \cfrac{h}{H} = \cfrac{f}{Z} ,即 Z =\cfrac{Hf}{h} 。需要知道实际世界中的车宽(或车高),然后通过物体在图像中的像素高度即可换算出来实际物体的距离。直观地讲,物体是近大远小的。
- \cfrac{y}{Y} = \cfrac{f}{Z} ,即 Z =\cfrac{Yf}{y} 。需要知道的是相机距离地面的安装高度以及在图像中车轮与地面接触点的纵坐标。直观地讲,在一条平直的路上,越近的物体它的纵坐标应该越靠图像下方,越远的物体越靠图像上方。
Tom van Dijk 和 Guido de Croon 在论文《 How Do Neural Networks See Depth in Single Images? 》探讨了基于深度学习的单目深度估计算法的局限性。
位置和缩放
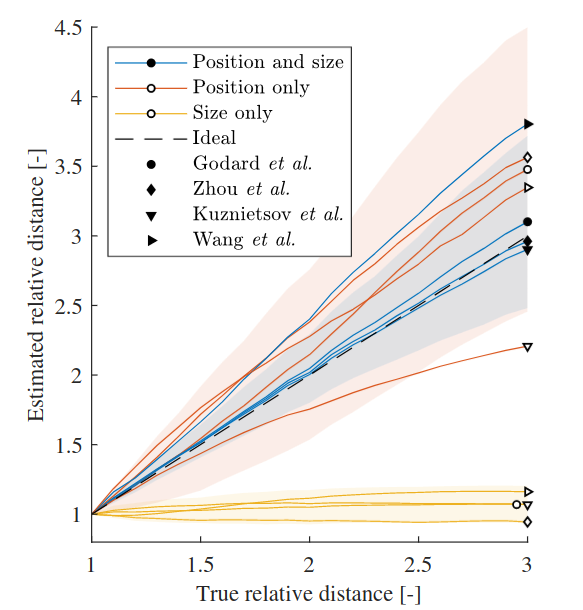
下图在一张真实道路图片中加入了一个假的车辆(贴图)变换位置和大小。第一行同时变换位置和大小;第二行仅变换位置,而物体大小没有进行缩放;第三行仅改变大小,没有改变物体位置。

下图显示了CNN的输出,可以看出仅改变size的情况下,CNN完全没有测距的能力,但是剩下两种方法仍然能够进行测距。因此可以得到结论:CNN其实是通过物体在图像中的纵坐标而不是物体的长宽来对物体测距的。
原文:These results suggest that the neural networks rely primarily on the vertical position of objects rather than their apparent size, although some change in behavior is observed when the size information is removed.
相机位姿
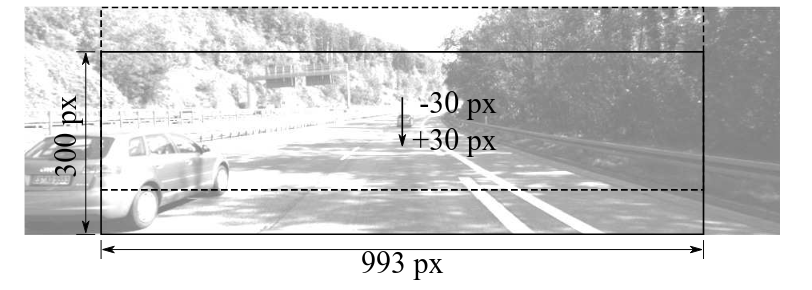
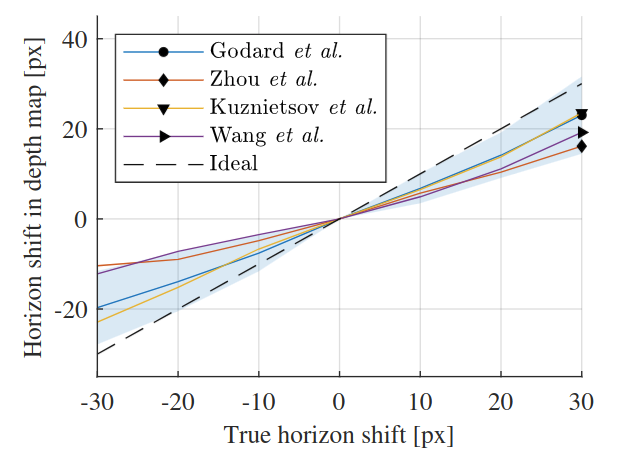
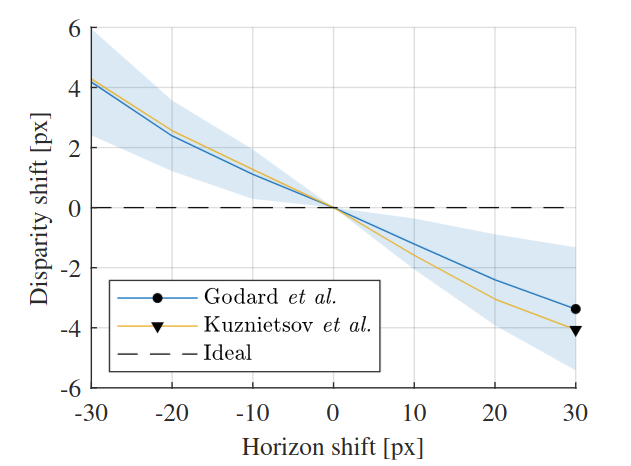
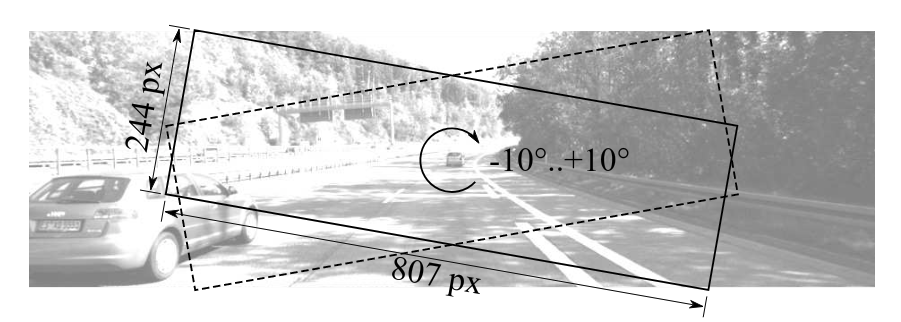
关于相机位姿(camera pose)对测距的影响,一个Robust的算法对相机位姿的变化应具有不变性。作者对pitch和roll角度的绕动进行分析。先是通过裁剪(crop)图片来模拟相机pitch的变化:
 |
 |
|---|
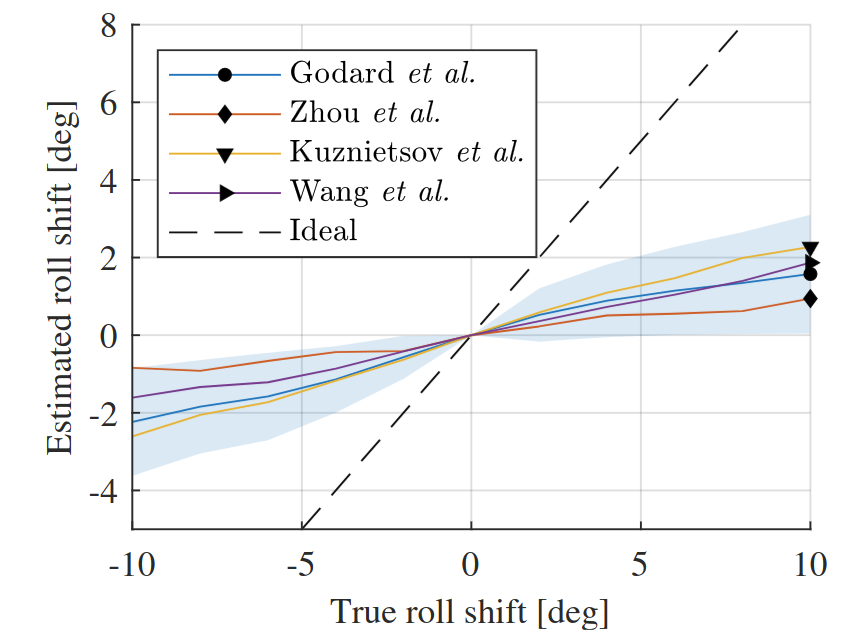
下图模拟了对roll角度的分析,可以看出CNN预测的深度图和roll角也有较强的相关性。
 |
 |
|---|
颜色和材质
第三部分,作者验证了CNN对颜色和材质的不变性。下图可以看出,正确颜色,灰度图,错误颜色都能在深度预测中取得比较准确的结果;但是如果使用平均颜色或者RGB分割颜色的话,预测结果会变得非常不准确。

原文:Error values for images that keep the value channel intact (grayscale and false colors) are close to the unmodified values. Images where the value information is removed and the objects are replaced with flat colors (semantic rgb, class-average colors) perform significantly worse.
形状和边缘
随后作者又研究了形状和边缘对检测的影响。从下图可以看出,去除汽车的中心部分对检测没有明显影响。汽车的底部和侧面的边缘似乎对检测影响最大。
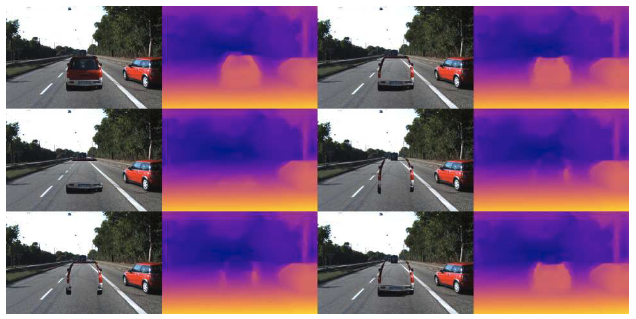
此外,从下图可以看出,阴影对CNN测距的影响较大。原本不能检测到的冰箱和狗(粘贴目标)也可以被检测到了。
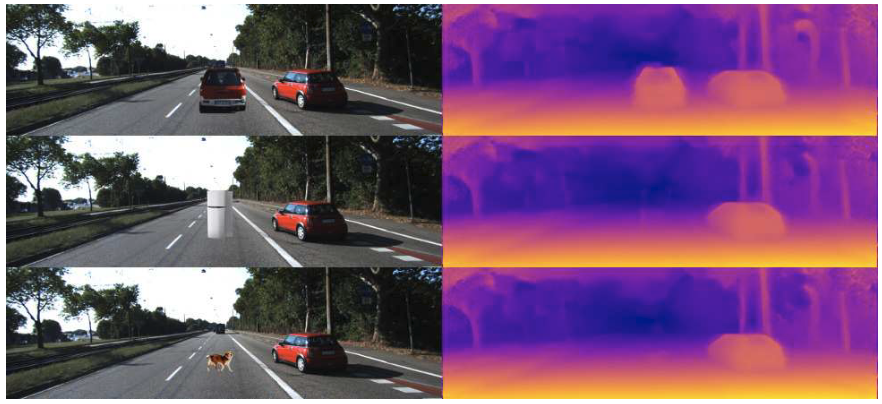
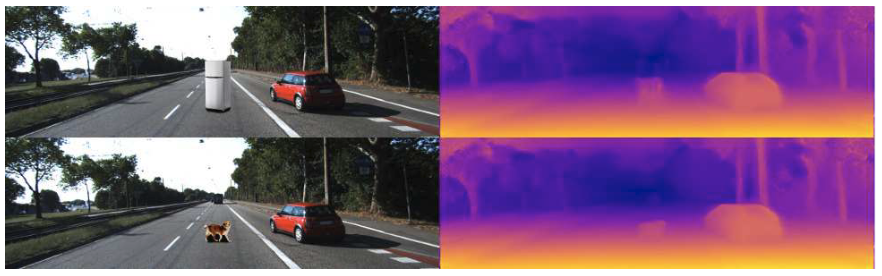
总结:基于CNN进行深度估计本质上是通过overfit场景中的某种信息进行深度估计,这些方法并没有考虑到Geometry限制,所以泛化能力较差。通过Geometry方法来完成不同位置的深度估计;或通过先验信息来预测绝对尺度,再融合两者的到一个Robust的深度估计。另一方面,也可以通过采集不变物理量,e.g. 车型尺寸和车道线等信息,结合Geometry信息得到深度
待验证:
- 既然CNN对于crop和rotation很敏感,那如果我们训练的时候使用了random crop和random rotation这样的data augmentation,那么CNN依赖的深度线索是否会有变化?
参考文章
[1] https://zhuanlan.zhihu.com/p/419816311 单目测距那些事儿(上) | 从MobileEye谈起
[2] https://zhuanlan.zhihu.com/p/419816311 单目测距那些事儿(下) | 突破相机平视假设
[3] https://towardsdatascience.com/monocular-3d-object-detection-in-autonomous-driving-2476a3c7f57e Monocular 3D Object Detection in Autonomous Driving — A Review
[4] G. P. Stein, O. Mano and A. Shashua, "Vision-based ACC with a single camera: bounds on range and range rate accuracy," IEEE IV2003 Intelligent Vehicles Symposium. Proceedings (Cat. No.03TH8683), Columbus, OH, USA, 2003, pp. 120-125, doi: 10.1109/IVS.2003.1212895.
[5] https://zhuanlan.zhihu.com/p/95758284 CNN是靠什么线索学习到深度信息的?——一个经验性探索
[6] Dijk, Tom van, and Guido de Croon. "How do neural networks see depth in single images?." In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 2183-2191. 2019.
[7] https://zhuanlan.zhihu.com/p/141799551 从对极几何恢复相机运动
评论