

这一部分是CUDA的核心部分,涉及到了硬件和程序的执行模型。
SM
流式多处理器(Stream Multi-processor,SM)是构建整个GPU的核心模块。GPU的硬件并行,是通过复制了多个SM来实现的。一个Block只能在一个SM上被调度。
下图包含了SM的关键组件
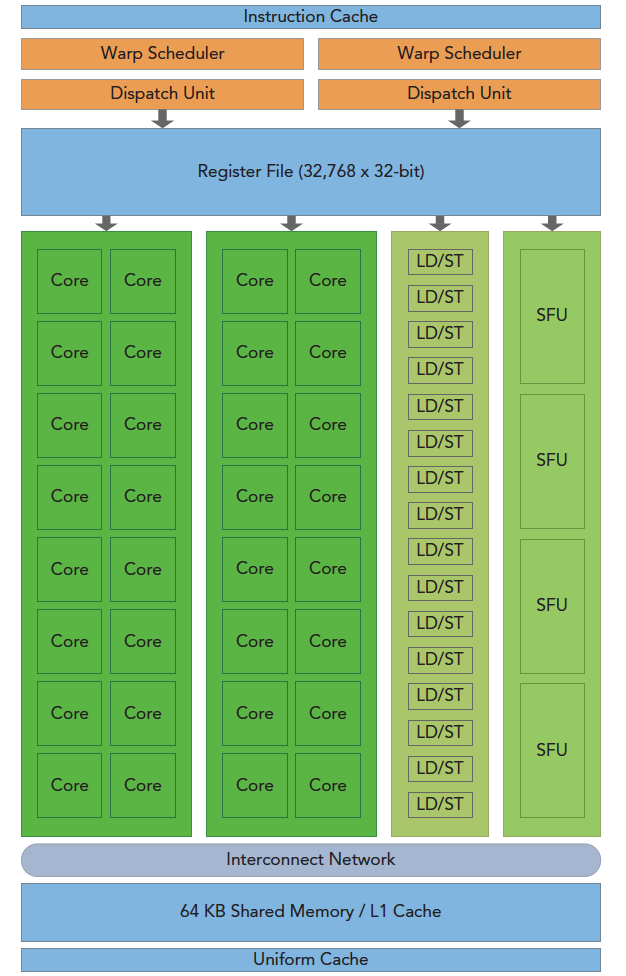
- CUDA核心 (Core)
- 共享内存/一级缓存 (Shared Memory/L1 Cache)
- 寄存器文件 (Register File)
- 加载/存储单元 (LD/SF)
- 特殊功能单元 (SFU)
- 线程束调度器 (Warp Schedule)
CUDA采用单指令多线程(SIMT)架构来管理和执行线程,每32个线程为1组,被称作一个线程束(warp)。一个Warp中所有线程都执行相同的指令。也就是说,一个SM上有多个Block,一个Block中又包含多个Thread,但是在某个时刻,SM只会执行一个Warp。
Warp
一个Warp由32个连续的Thread组成,在一个Warp中,所有Thread都按照SIMT的方式执行。虽然Block可以是一维、二维、三维的,但是在硬件的角度看,所有Thread都是一维的,在一个二维Block中,每个Thread的唯一索引都可以计算:
threadIdx.y * blockDim.x + threadIdx.x
注意之前计算的Grid中每个Thread的唯一索引有所不同:
blockIdx.x * blockDim.x + threadIdx.x
blockIdx.y * blockDim.y + threadIdx.y
因此我们重新计算一个Thread分别在Grid和Block中的唯一索引,在二维Grid和二维Block的情况下:
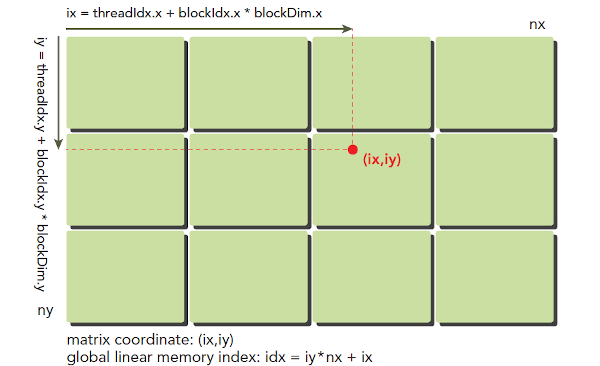
- 每个
Thread在Block中的位置为:threadIdx.x行、threadIdx.y列。 - 每个
Block在Grid中的位置为:blockIdx.x行和blockIdx.y列。 - 任一个
Thread在Block中的唯一索引为:threadIdx.y * blockDim.x + threadIdx.x^{[1]} - 任一个
Block在Grid中的唯一索引为:blockIdx.y * gridDim.x + blockIdx.x^{[2]} - 任一个
Thread在Grid中的位置为:blockIdx.x * blockDim.x + threadIdx.x行,blockIdx.y * blockDim.y * blockIdx.y - 随后计算
Thread在Grid中的唯一索引:[blockDim.x * blockDim.y] * [blockIdx.x + gridDim.x * blockIdx.y ] + blockDim.x *threadIdx.y + threadIdx.x
上式可以理解为,当某Block位于Grid中的某个位置时,其前面有[blockDim.x * blockDim.y] * bIdx个Thread,这个bIdx就是上面提到的Block在Grid中的唯一索引^{[2]},随后再加上Thread在Block中的唯一索引,也就是公式 ^{[1]} 中的索引。
线程束分化
Warp分化的含义就是:在同一个Warp中的Thread执行不同的指令,分化会导致性能明显下降。当不得不进行算法中加入其他分支的时候,确定一个合理的分支粒度可以有效避免Warp分化。
比如下面两个函数:
__global__ void mathKernel1(float *c){
int tid = blockIdx.x* blockDim.x + threadIdx.x;
float a = 0.0;
float b = 0.0;
if (tid % 2 == 0){
a = 100.0f;
}
else{
b = 200.0f;
}
c[tid] = a + b;
}
__global__ void mathKernel2(float *c){
int tid = blockIdx.x* blockDim.x + threadIdx.x;
float a = 0.0;
float b = 0.0;
if ((tid/warpSize) % 2 == 0){
a = 100.0f;
}
else{
b = 200.0f;
}
c[tid] = a + b;
}
在 mathKernel1中,Warp的奇数线程(threadIdx.x为奇数)会执行 else,偶数线程执行 if,Warp存在严重的分化。
然而在 mathKernel2中,分支粒度是Warp大小的倍数。当有两个Warp时,第一个Warp内的线程编号 tid为从0到31,因此 tid/warpSize都等于0,执行 if。第二个Warp内的线程编号 tid是从32到63,tid/warpSize都不等于0,执行 else。当一个线程束中所有的线程都执行 if或者,都执行 else时,不会导致性能下降。
有一个指标,分支效率,定义为未分化的分支和全部分支之比:
当分支效率低于100%,并不一定会导致程序效率降低,也就是必要条件,而非充分条件。CUDA编译器是有优化功能的,很短的分支并不会对程序效率产生明显影响,但是很长的代码路径必定会导致Warp分化和明显的效率降低。
资源分配
Warp的本地执行上下文包含以下资源:
- 程序计数器
- 寄存器 (Register File)
- 共享内存 (Shared Memory)
执行上下文(Context)指设备与特定进程相关连的所有状态,所管理CUDA程序中所有对象生命周期的容器。
SM处理的每个Warp的执行上下文(程序计数器、寄存器等)在 Warp 的整个生命周期内都在芯片上。因此,从一个执行上下文切换到另一个执行上下文是没有成本的,并且在每个指令发出时,Warp 调度器都会选择一个线程准备好执行其下一条指令(Warp 的活动线程)并将指令发布给这些线程。
每个SM都有一个32Bit的寄存器组,可以在Thread中进行分配。
同时有固定数量的共享内存,可以在Block中进行分配。
因此对一个Kernel,同时存在于一个SM中的Block和Warp数量取决于SM中可用且所需的寄存器和共享内存数量。
每个Thread需要的寄存器越多,那么SM中的Warp就越少。即减少Thread所需寄存器数量,即可增加SM中的Warp数。
每个Block需要的共享内存越多,那么SM中可以被同时处理的Block就会变少。即减少每个Block所需的共享内存,即可同时处理更多Block。SM内的资源没办法处理一个完整Block,那么Kernel将无法启动。
上面提到的计算资源会限制SM中常驻Block的数量。当资源被分配给Block时,这个Block就变成活跃的,其中的Warp也是活跃的。
根据执行情况,活跃的Warp分为三类:
- 选定的线程束:活跃执行的Warp
- 阻塞的线程束:没有做好执行准备
- 符合条件的线程束:准备执行,但未执行
当32个CUDA核心可用且当前指令中所有参数已就绪时,Warp满足执行条件。
延迟
CPU核心是为了最小化少数几个线程而设计,GPU则是为了处理大量并发且轻量级的线程以最大化吞吐量。指令延迟被定义为:指令发出到指令完成的时钟周期。
指令延迟可以分为两种:
- 算数指令延迟:一个算数操作开始 到 产生输出 之间的之间
- 内存指令延迟:发送出加载或存储操作 和 数据到达目的地 之间的时间
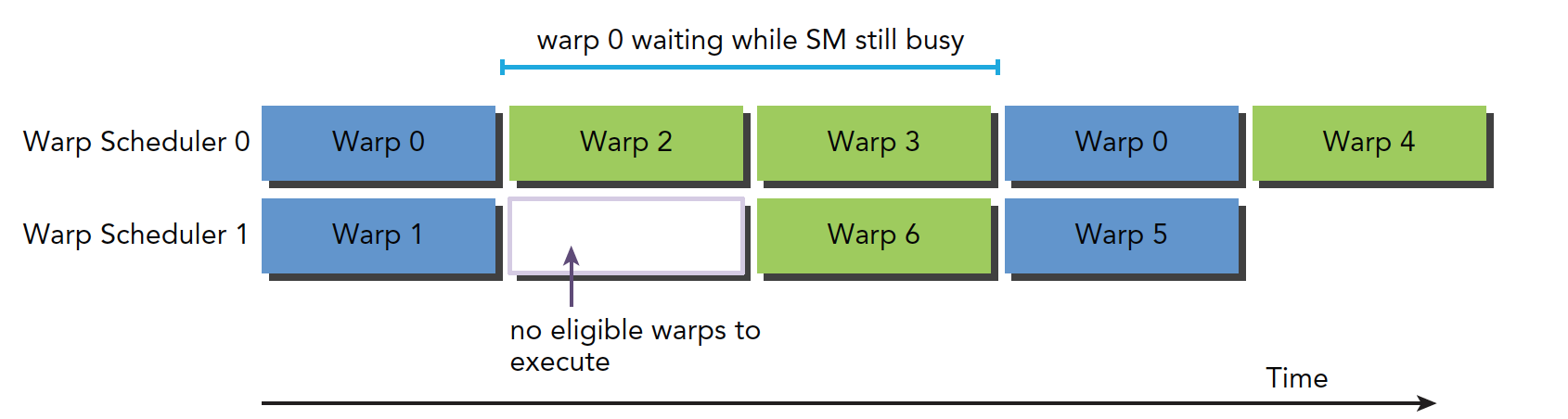
上图描述了Warp0阻塞执行流水线的情况,Warp调度器选取其他Warp执行,当Warp0符合条件时再执行:
当每个时钟周期中的所有线程调度器,都有一个符合条件的Warp,可以达到计算资源的完全利用,通过在其他常驻Warp中发布其他指令,可以隐藏指令的延迟。如果想估算隐藏延迟所需的活跃Warp数量,Little's Law可以估算一个近似值,即延迟和吞吐量的乘积:
吞吐量是已经达到的值,描述单位时间内任何形式的信息和操作的执行速度;带宽指理论峰值,描述单位之间内最大可能达到的数据传输量。
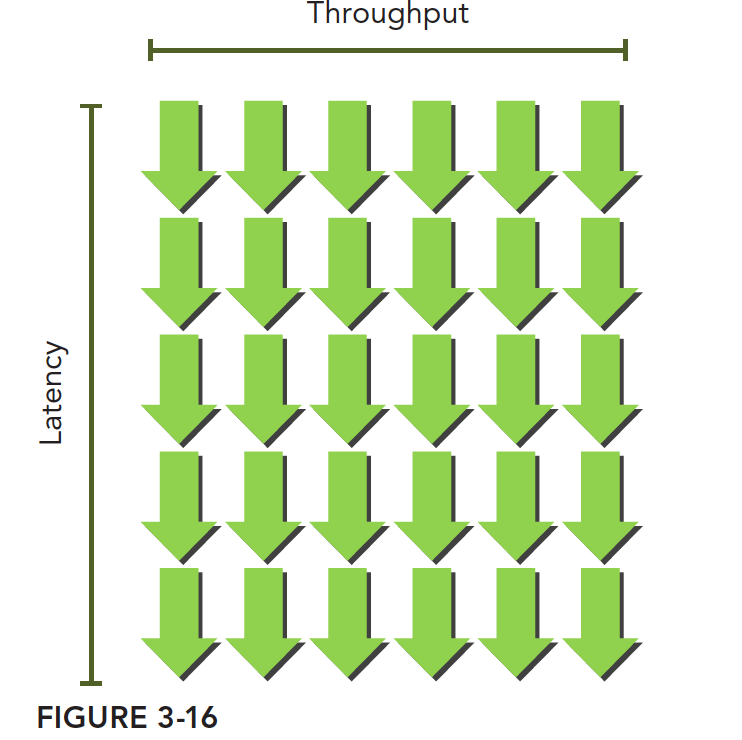
图中绿色的箭头是Warp,可以理解为,只要Warp足够多,那么吞吐量就不会下降。
占用率
占用率指每个SM中活跃的Warp占最大Warp数量的比值:
使用 cudaGetDeviceProperties()函数可以获取设备中每个SM的最大Warp数。
通过 \cfrac {maxThreadPerMultiProcessor}{32} 获得最大Warp数量。
#include <stdio.h>
#include <cuda_runtime.h>
int main(int argc, char** argv[]){
int iDev = 0;
cudaDeviceProp iProp;
cudaGetDeviceProperties(&iProp, iDev);
printf("----------------------------------------------------------\n");
printf("Number of multiprocessors: %d\n", iProp.multiProcessorCount);
printf("Total amount of constant memory: %4.2f KB\n",
iProp.totalConstMem/1024.0);
printf("Total amount of shared memory per block: %4.2f KB\n",
iProp.sharedMemPerBlock/1024.0);
printf("Total number of registers available per block: %d\n",
iProp.regsPerBlock);
printf("Warp size %d\n", iProp.warpSize);
printf("Maximum number of threads per block: %d\n", iProp.maxThreadsPerBlock);
printf("Maximum number of threads per multiprocessor: %d\n",
iProp.maxThreadsPerMultiProcessor);
printf("Maximum number of warps per multiprocessor: %d\n",
iProp.maxThreadsPerMultiProcessor/32);
return EXIT_SUCCESS;
}
返回结果为:
----------------------------------------------------------
Number of multiprocessors: 8
Total amount of constant memory: 64.00 KB
Total amount of shared memory per block: 48.00 KB
Total number of registers available per block: 65536
Warp size 32
Maximum number of threads per block: 1024
Maximum number of threads per multiprocessor: 1536
Maximum number of warps per multiprocessor: 48
记住一些准则:
- 每个Block中的Thread数量是32的整数倍
- 每个Block要有128或256个Thread,即不要太小
- 根据Kernel资源调整Block Size
- Block的数量要远远多于SM数量,保证足够并行,减少指令延迟
CUDA Toolkit中包含了一个电子表格,名为《CUDA GPU Occupancy Calculator》,但是这个东西已经不能用了,目前推荐使用Nsight。VS Code有Nsight插件,后面会花些时间专门研究这个调试工具怎么用。(GDB你还不会啊喂!)
栅栏同步
共享内存可以被Block中的多个Thread访问,CUDA 假设设备是一个弱序(Weakly-ordered)的内存模型,即一个 CUDA 线程将数据写入共享内存的顺序,与另一个CUDA或主机线程观察到的该数据被写入内存的顺序不一定相同。那么,两个线程在没有同步的情况下对同一个内存位置进行读写将出现未定义的行为。
CUDA提供障碍(Barrier)和内存栅栏(Memory Fences)来实现块内同步。在障碍中,所有调用的线程等待其余调用的线程到达障碍点。在内存栅栏中, 所有调用的线程必须等到全部内存修改对其余调用线程可见时才能继续执行。
如果让多个线程互相合作完成一项任务,这要求线程间可以进行协调。栅栏相当于程序中的一个集合点,当结果需要在中间进行整合的时候经常需要使用,当一个线程需要等待其他线程时候,可以让线程运行到栅栏处,一旦所有线程到达这个栅栏,栅栏就撤销。
同步在两个级别进行:
- System级:等待Host和Device完成所有工作。对Host来说,许多CUDA API调用和所有Kernel启动不是同步的,需要使用
cudaDeviceSynchronize()函数来阻塞Host程序,直到所有CUDA操作完成。 - Block级:等待一个Block中的所有Thread达到同一个点。由于一个Block中的Warp会以未定义的顺序执行,使用CUDA的Block局部栅栏可以同步,
__device__ void __syncthreads(void)可以在Kernel中标记同步点。该函数被调用时,同一个Block中的Thread必须等待,直至Block中所有Thread都达到这个同步点。不过由于它强制Thread空闲,可能导致性能下降。
需要注意的是,不同Block间,无线程同步。因此唯一的办法是在每个Kernel执行结束时使用全局同步点。
参考文章
[1] GPU编程9:共享内存3→共享内存线程同步
[2]【CUDA 基础】3.2 理解线程束执行的本质(Part II)
[3] 极智开发 | CUDA线程模型与全局索引计算方式
评论