
算法 [62]
3D稀疏卷积 3D Sparse Convolution
点云数据体素化后,有90%+的Voxel是空的,如果像VoxelNet那样直接使用3D Conv,计算量太大。 左图是稀疏的2D Tensor,深灰色像素都是0,浅灰色是non-zero点。 右图是稀疏的3D Tensor,只有红色的体素才是non-zero。 因此提出了3D稀疏卷积——3D Spa

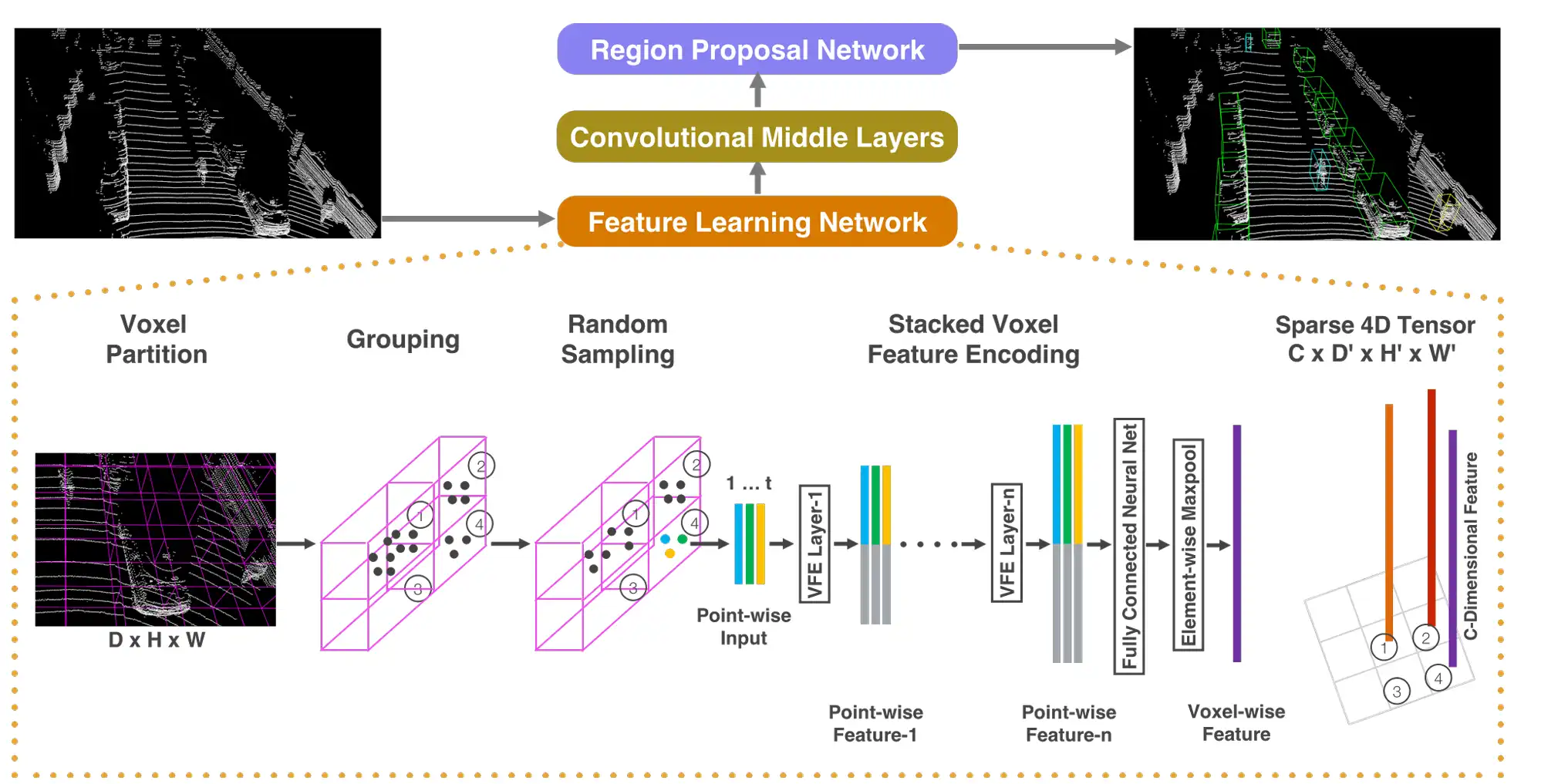
【重读经典】点云深度学习网络的范式变迁:PointNet, VoxelNet和PointPillars
PointNet 直接以 N×3N \times 3的Raw PointCloud作为输入,每个点使用 (x,
【重读经典】BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework
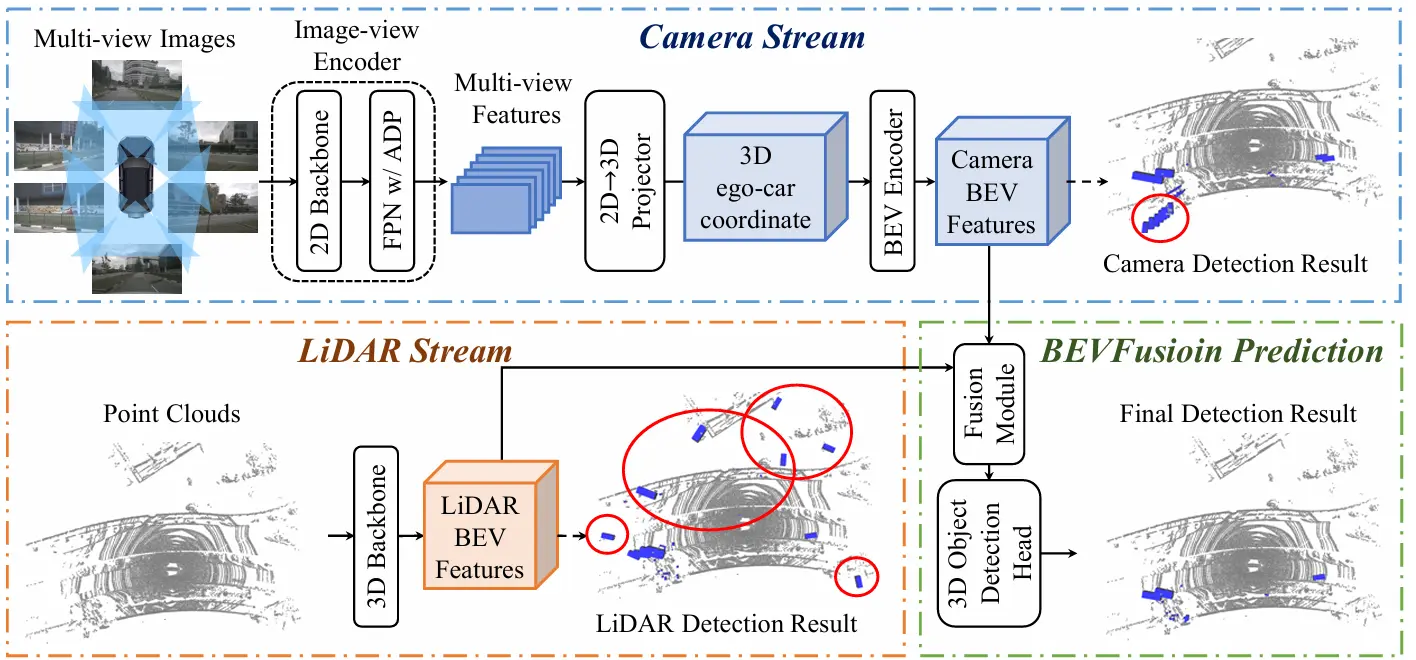
BEVFusion有两篇论文: 一篇名为《BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework》,发表于2022年。 另一篇名为《BEVFusion: Multi-Task Multi-Sensor Fusion with Unif
【重读经典】BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation
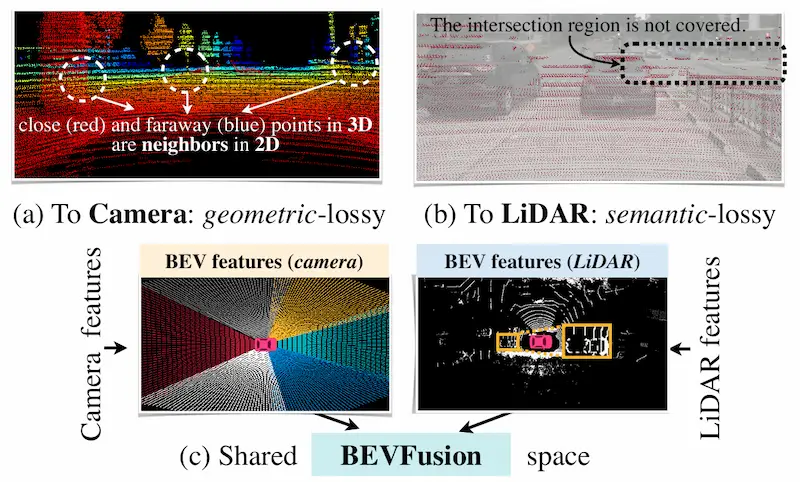
自动驾驶常见传感器包括相机,LiDAR,雷达等传感器。 相机能提供丰富语义,LiDAR提供准确的空间信息,雷达能进行速度估计。 对于多传感器方案,当时的传感器投影存在信息损失的问题: LiDAR->Cam:存在几何损失,像素坐标系中相邻的像素点,在3D空间中可能距离很远。设想一个人站在墙前面,在像素
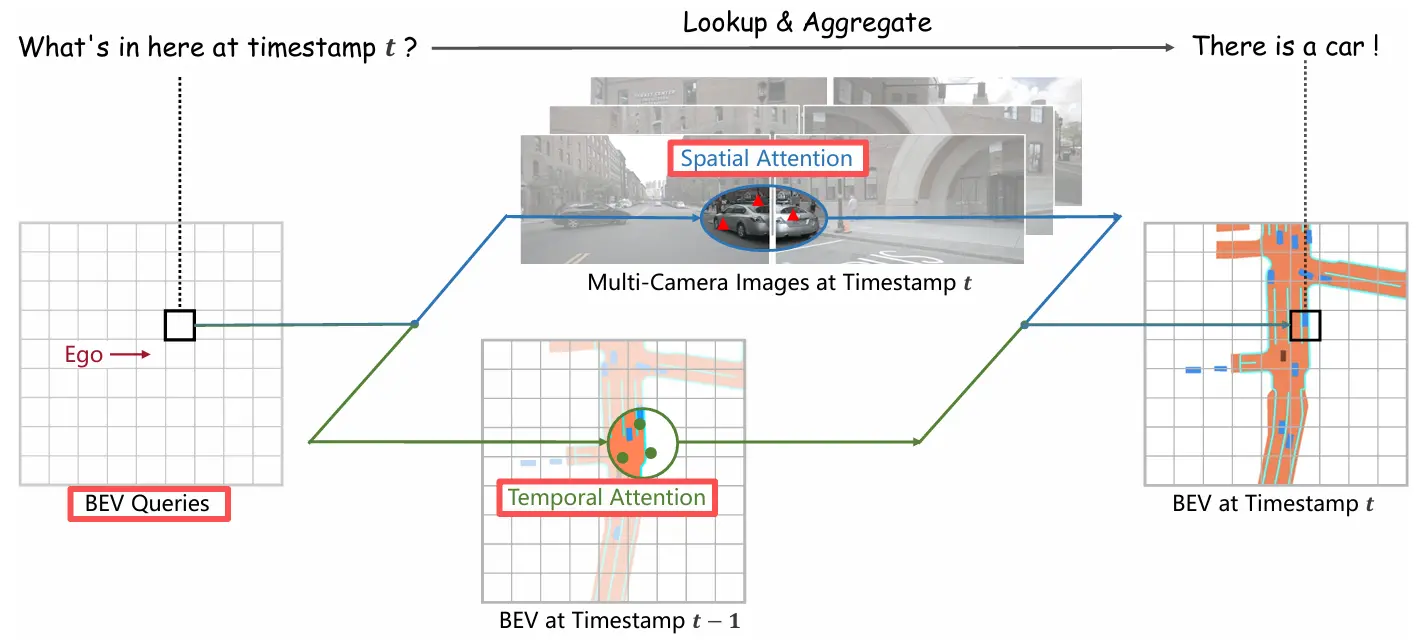
【重读经典】BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
先看论文题目 Multi-Camera:多相机纯视觉方案,Camera-based的mAP天然比LiDAR-based和Fusion-based的要低 Spatiotemporal:时间空间 Transformer:用到了Transformer架构以及Attention机制 创新点 论文摆脱了之前L

nuscenes-devkit的使用
nuScenes数据集说明 - FunnyWii's Zone 一文了解nuScenes数据集的结构。 我们使用nuscenes-devkit进一步学习数据集的使用。 安装非常简单,建议python版本3.12和3.9。 pip install nuscenes-devkit devkit使用 仍以
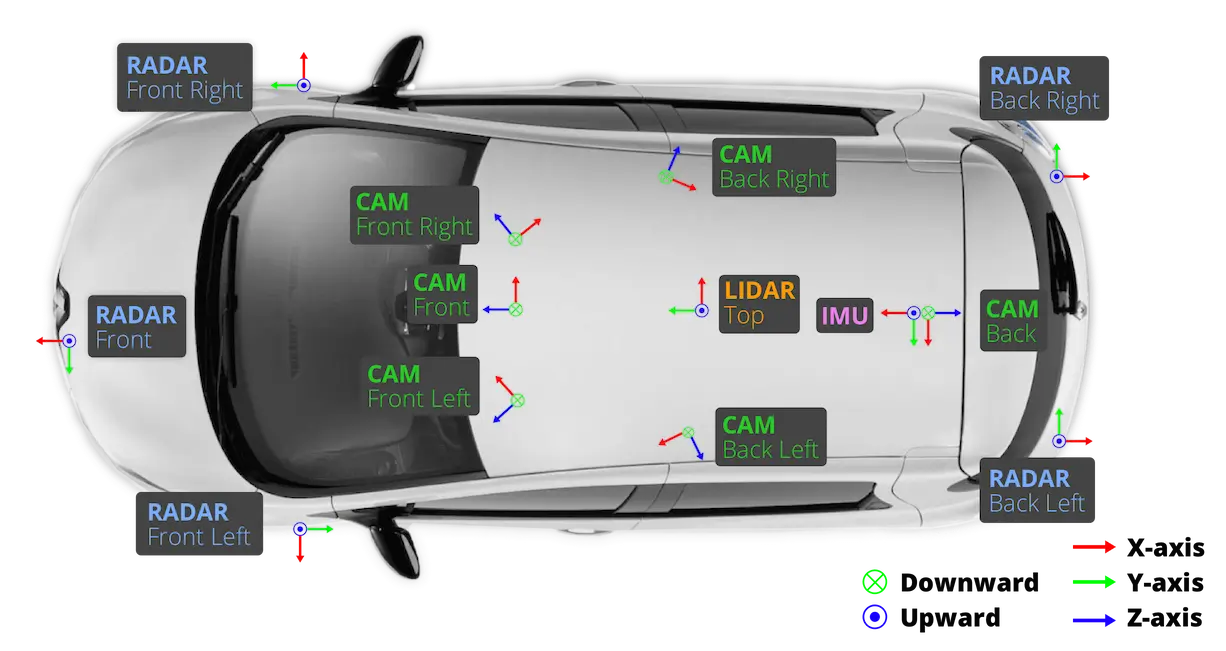
nuScenes数据集说明
nuScenes数据集包含6个Camera,1个LiDAR,5个Radar,1个GPS以及IMU。 数据量比KITTI大得多,所以目前Occ Networks更多使用nuScenes数据集。 数据集分成两大块:Full和Mini。 Full Dataset包含140万Camera图像,39万LiDA

Ubuntu22部署FlashOcc踩坑实录
环境配置 conda create --name FlashOcc python=3.8.5
conda activate FlashOcc
pip install torch==1.10.0+cu111 torchvision==0.11.0+cu111 torchaudio==0.10.0 -f
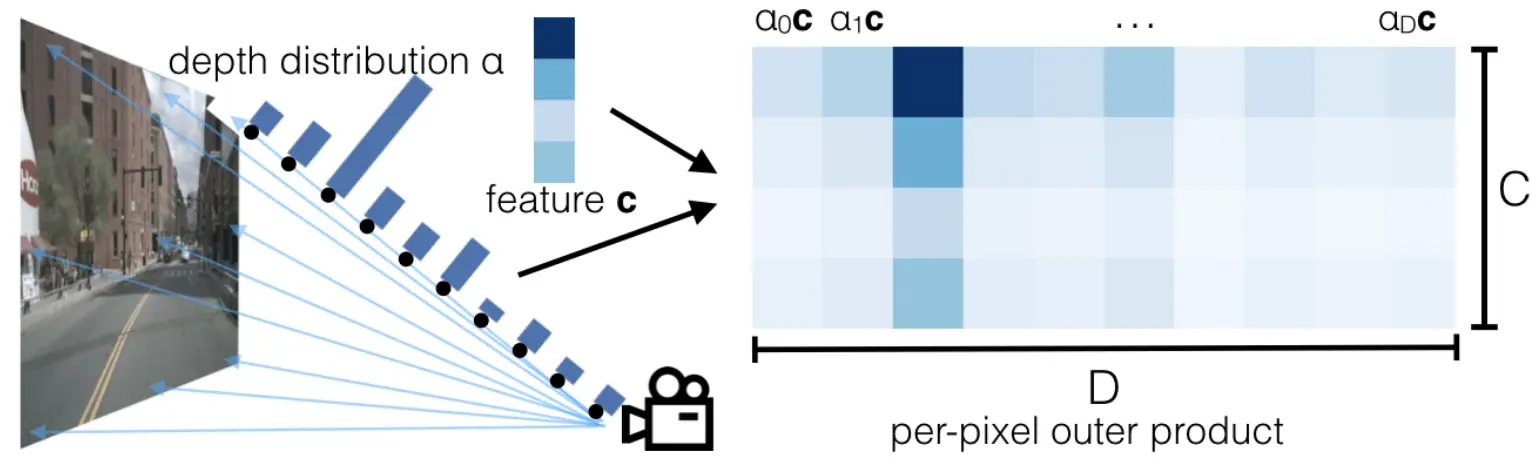
【重读经典】Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
LSS是NVIDIA在ECCV2020上发表的文章。 理解一下论文标题中的Lift, Splat, Shoot三个单词。 这三个单词对应模型中三个核心步骤。 Lift:提升。2D图像特征提升到3D视锥空间特征。 Splat:泼溅。所有相机生成的3D视锥特征,泼洒到统一的BEV平面网格。 Shoot:

【重读经典】3D Bounding Box Estimation Using Deep Learning and Geometry
Deep3DBox是一篇比较早的使用单目相机进行3D目标检测和姿态估计的方法。 Deep3DBox先用CNN回归目标的方向和尺寸,因为这两类属性稳定性比较高。然后结合2D BBOX的几何约束求解平移量,以生成完整的3D BBOX。 有些传统的方法基于PnP,通过2D-3D关键点对应关系求解姿态,需要
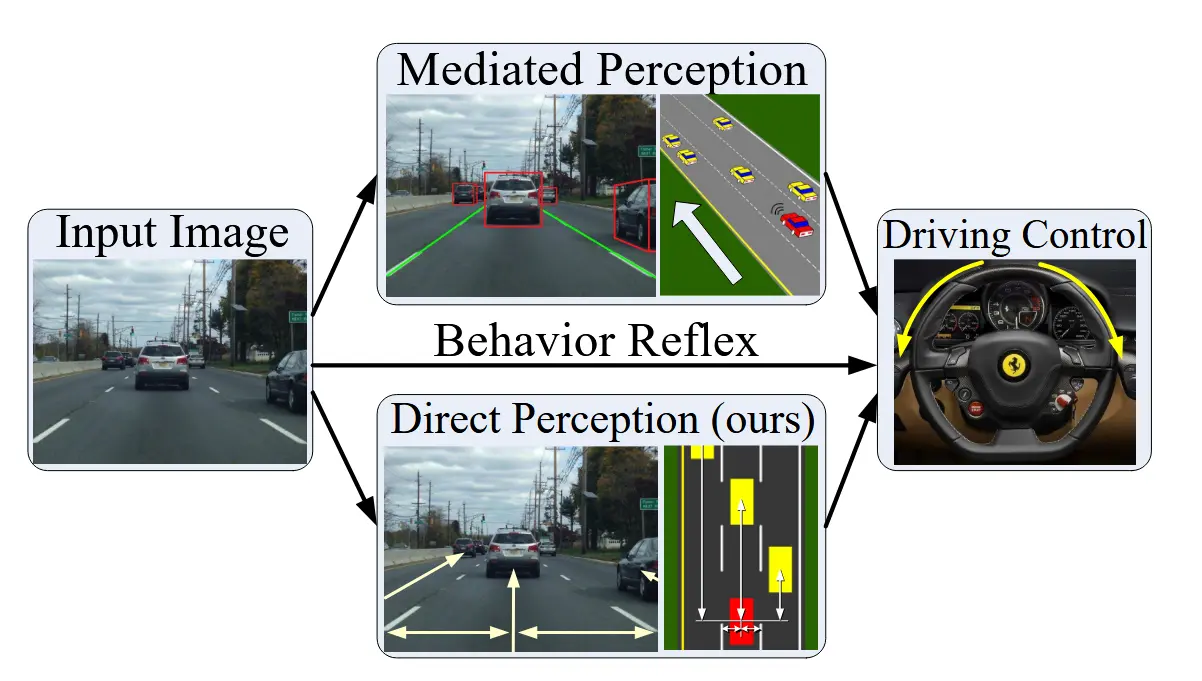
【重读经典】DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving
标题中的Affordance一词,本意是”预设用途,功能特性“,最初在知觉心理学和设计学领域出现。 后来在人机交互领域,Affordance的含义变成了:一个产品让用户自然领悟到用法的能力。 在机器人领域(自动驾驶和机器人的感知不分家),被引申为可以执行的潜在动作,即在特定情况下哪些动作是可执行的。

深度学习 - 网络的优化 Optimisation for Training Deep Networks
深度学习 - 网络的优化 Optimisation for Training Deep Networks 深度学习问题需要一个损失函数,我们的目标就是通过优化算法来最小化损失,即最小化目标(损失)函数。需要注意的是,优化和深度学习的本质目标有差异,优化关注的是最小(最大)化目标,深度学习更关注模型。

Kalman Filter原理及公式推导
卡尔曼滤波是一种高效的递归(自回归)滤波器。能够从一系列的不完全及包含噪声的测量中,估计动态系统的状态。卡尔曼滤波会根据各测量值在不同时间下的值,考虑各时间下的联合分布,再产生对未知变量的估计,因此会比只以单一测量值为基础的估计方式要准^{[1]}。 几个值 先说明一下卡尔曼滤波中涉及到的各个值:


多传感器融合——后融合
多传感器融合的方案可以分成前融合(Early Fusion)方案和后融合(Late Fusion)方案。 前融合也叫特征级融合,不同传感器的数据会在特征级别进行合并,也就是说,不同模态的数据经过处理和合并后会得到一个特征集合。一般来说,每个模态数据的特征会被分别提取,然后被提取到的特征会被合并为一个

C++ STL容器的底层原理
C++ STL 容器是使用频率超高的基础设施,只有了解各个容器的底层原理,才能得心应手地用好不同的容器,做到用最合适的容器干最合适的事情[1]。看了文章[1],可惜其中对容器方法的底层几乎没有提及,那就自己边查边写吧。本文大部分内容来自cplusplus.com/reference/ 。 C++ S

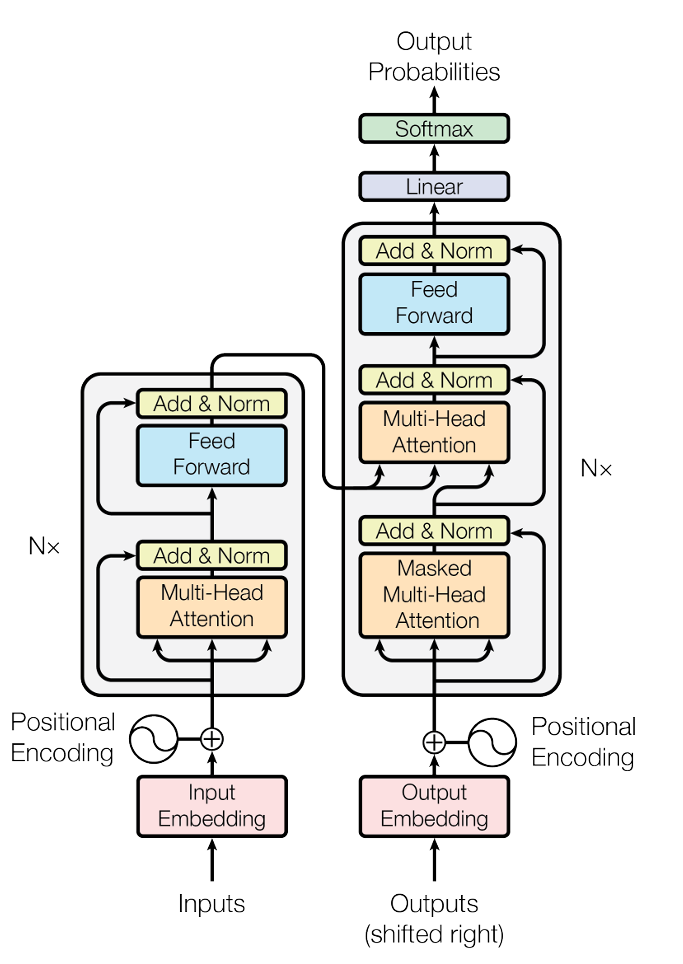
学习Transformer
Transformer在谷歌2017年的论文 [1706.03762] Attention Is All You Need 中首次被提出,主要用于NLP(Natuarl Language Processing,自然语言处理)的各项任务。 后来在CV领域,研究者们基于Transformer架构开展了一
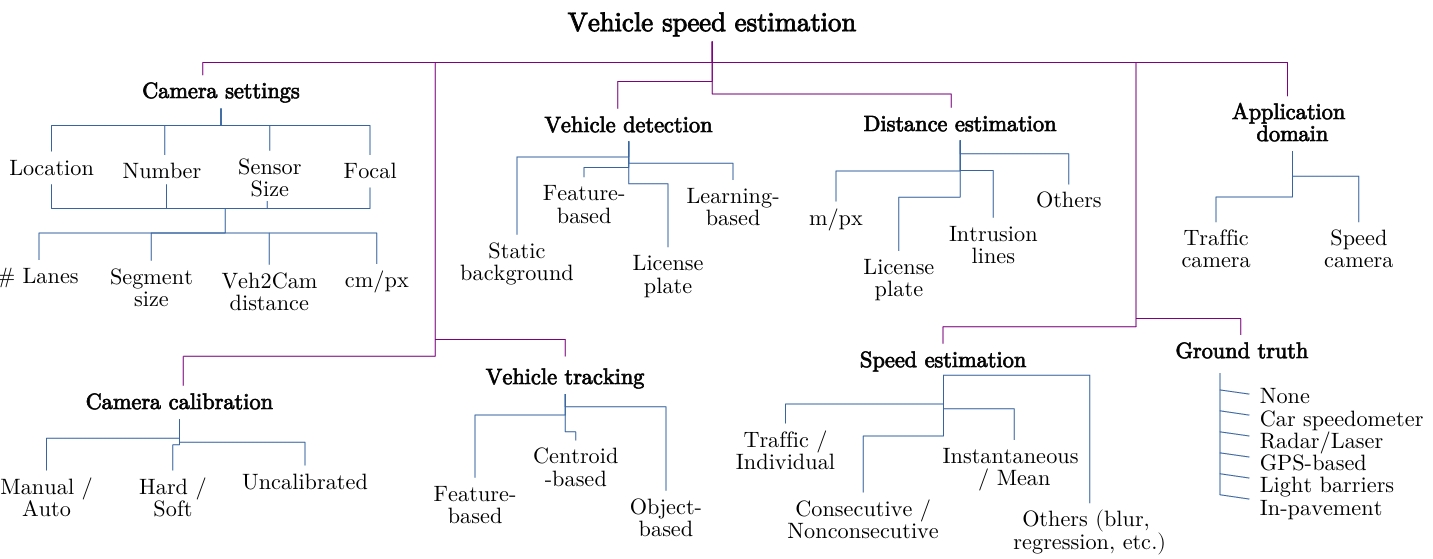
单目相机的相对速度估计
前言 单目相机的目标距离估计本身就已经充满了挑战,那么目标的(相对)速度估计也必然是十分困难... 目前单目相机的相对速度估计算法可以分成两类:传统方法和深度学习方法。没错,什么任务都可以深度学习。 传统方法中,最经典的是Mobileye在2003年的一篇论文中提出的算法。这个算法包含目标距离和速度

道路目标流量统计算法
实现流量统计算法有两个前提: 能够实现目标检测,最基本的前提,必须能够识别到视频帧中的车辆和行人。 能够进行目标跟踪,在检测的基础上,为目标分配一个唯一的ID。流量计数依赖于目标的唯一ID。 目标检测算法以YOLO系列为例。 跟踪算法以ByteTrack跟踪结果为例。将检测结果objects作为By