
CUDA 内存模型
存储器的类型有两种:
- 可编程:显式控制哪些数据存放。
- 不可编程:不能决定数据存储位置。
在 CPU 层次结构中,一级缓存(L1 Cache)和二级缓存(L2 Cache)都是不可编程的。可编程的存储器类型包括:
- 寄存器
- 共享内存
- 本地内存
- 常量内存
- 纹理内存
- 全局内存
下图为上面提到的存储器类型:
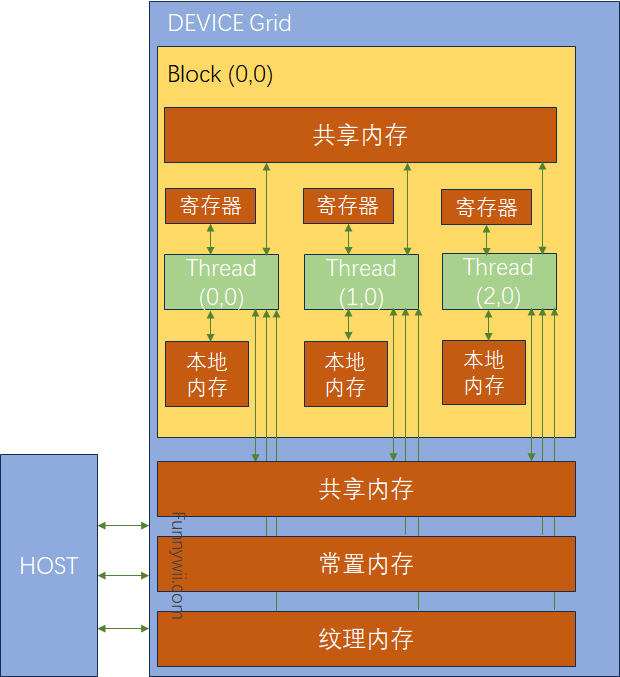
根据这张图可以分析:
- 一个 Kernel 中的每个 Thread 都有私有的本地内存地址空间。需要注意,本地内存虽然对线程私有,但它通常位于设备全局内存中,并可能经过缓存访问。
- 一个 Block 有自己的共享内存,对本 Block 内的所有 Thread 可见,且其内容持续整个 Block 的生命周期。
- 所有 Thread 都可以访问全局内存。
- 所有 Thread 也都可以访问只读的常量内存和纹理内存。
对一个应用程序来说,全局内存、常量内存、纹理内存中的内容有相同的生命周期。
寄存器
寄存器是 GPU 上运行速度最快的内存空间。寄存器对于每个 Thread 来说是私有的,一个 Kernel 使用寄存器来保存需要频繁访问的 Thread 私有变量。寄存器变量和 Kernel 的生命周期相同。
如果 Kernel 使用的寄存器数量超过硬件限制,多出来的数据可能会被放到本地内存中,也就是常说的寄存器溢出,这会降低性能。nvcc 编译器会使用启发式策略决定寄存器分配和相关优化。所谓启发式策略,就是编译器根据一套预设规则和经验来生成代码,目标是提升运行效率,但并不保证一定达到全局最优。
- 占用计算器 API:
cudaOccupancyMaxActiveBlocksPerMultiprocessor可以根据 Kernel 的 Block 大小和共享内存使用情况提供占用预测。此函数根据每个多处理器的并发线程块数报告占用情况。 - 这个值可以继续转换为其他指标。乘以每个块的
Warp数,可以得到每个多处理器的并发Warp数;再将并发Warp数除以每个多处理器的最大Warp数,就能得到百分比形式的占用率。 - 基于占用率的启动配置器 API:
cudaOccupancyMaxPotentialBlockSize和cudaOccupancyMaxPotentialBlockSizeVariableSMem可以启发式地计算实现最大多处理器级占用率的执行配置。 - 也可以在代码中为 Kernel 显式加入额外信息:
__global__ void
__launch_bounds__(MAX_THREADS_PER_BLOCK, MIN_BLOCKS_PER_MP)
fooKernel(int *inArr, int *outArr)
{
// ... Computation of kernel
}
MAX_THREADS_PER_BLOCK 指定每个 Block 的最大 Thread 数;MIN_BLOCKS_PER_MP 指出每个 SM 中预期的最小常驻 Block 数。
本地内存
本地内存的特点是高延迟、低带宽。
Kernel 中本来希望放在寄存器里,但是不能进入该 Kernel 寄存器空间的变量,可能会被溢出到本地内存中。常见情况包括:
- 编译期无法确定索引方式的本地数组。
- 可能占用大量寄存器空间的较大本地结构体和数组。
- 寄存器压力过高,或其他不满足寄存器分配条件的变量。
要注意:溢出到本地内存的变量,本质上通常和全局内存在同一块设备内存区域中,只是从线程视角看属于自己的私有地址空间。
共享内存
Kernel 中使用 __shared__ 修饰的变量存放在共享内存中。共享内存相比全局内存和本地内存,有更高的带宽和更低的延迟。
每个 SM 都有一定数量由 Block 分配的共享内存,因此不能过度使用共享内存,否则会限制活跃 Warp 的数量。
共享内存的生命周期伴随着整个 Block。当一个 Block 的执行结束后,其分配的共享内存将被释放,并重新分配给其他 Block。
线程间通信的主要方式就是共享内存。当多个线程之间存在数据依赖时,访问共享内存通常需要使用 void __syncthreads() 进行同步,以避免潜在的数据冲突。如果各线程访问互不依赖,或者在特定场景下使用 warp 内同步语义,就不一定每次访问共享内存都需要调用 __syncthreads()。
SM 中的 L1 Cache 和共享内存都使用片上内存,每个 SM 上有 64 KB 的片上内存,默认通过静态划分,但在运行时也可以使用 cudaError_t cudaDeviceSetCacheConfig(cudaFuncCache cacheConfig); 进行动态配置,其中 cacheConfig 支持如下缓存配置:
cudaFuncCachePreferNone: no preference(default)
cudaFuncCachePreferShared: prefer 48KB shared memory and 16 KB L1 cache
cudaFuncCachePreferL1: prefer 48KB L1 cache and 16 KB shared memory
cudaFuncCachePreferEqual: prefer 32KB L1 cache and 32 KB shared memory
常量内存
常量内存使用 __constant__ 进行修饰,保存在设备内存中,并在每个 SM 专用的常量 Cache 中缓存。
常量变量必须在全局空间内和Kernel 函数外声明。常量内存空间通常为 64 KB,具体限制应以设备属性和 CUDA 文档为准。需要注意,常量内存空间大小和常量缓存大小不是同一个概念。
Kernel 只能从常量内存读取数据,因此常量内存必须在 Host 端初始化:
cudaError_t cudaMemcpyToSymbol(const void* symbol, const void* src, size_t count);
这个函数会将 count 个字节从 src 复制到 symbol。
纹理内存
纹理内存驻留在设备内存中,并在每个 SM 的只读 Cache 中缓存。纹理内存可以理解为一种通过指定的只读 Cache 进行访问的全局内存。
此外,纹理路径适合具有空间局部性的 2D / 3D 数据访问和特定采样模式。在这类场景中,使用纹理内存可能获得更好的性能,但并不保证总是最优,具体仍然需要结合访问模式和硬件架构测试。
全局内存
全局内存是 GPU 中最大、延迟最高、使用最多的内存类型。
要注意多个线程访问全局内存时,因为 Thread 的执行不能跨 Block 同步,不同 Block 的多个 Thread 并发修改同一位置的全局内存时,可能会导致未定义的行为。需要时应使用原子操作、合适的数据划分方式,或者通过多 Kernel 调度建立全局同步边界。
可以通过 32 / 64 / 128 Byte 的内存事务访问全局内存,这些内存事务必须自然对齐,也就是首地址必须是 32 / 64 / 128 Byte 的整数倍。当一个 Warp 执行内存加载和存储时,所需的传输数量取决于:
- 跨线程的内存地址分布。
- 每个事务内存地址的对齐方式。
GPU 缓存
和 CPU 缓存一样,GPU 缓存也是不可编程的。但是 CPU 内存的加载和存储通常都可以被缓存;传统 CUDA 资料中常强调全局内存读取缓存。现代 GPU 中,L2 Cache 也会参与写入、原子操作等访问路径,具体缓存行为和 GPU 架构、访问类型、编译选项都有关系。
GPU 上常见的缓存包括:
- 1 级缓存:每个 SM 都有一个 1 级缓存,用来缓存本地内存和全局内存的部分数据,包括寄存器溢出的本地内存访问。
- 2 级缓存:所有 SM 共享一个 2 级缓存,用于服务全局内存、本地内存以及部分写入等访问路径。
- 只读常量缓存:用于加速常量内存访问。
- 只读纹理缓存:用于加速纹理路径访问。
静态全局内存
CPU 内存有动态分配和静态存储期对象等不同概念。从内存位置来说,动态分配通常在堆上进行,使用 new、malloc 等函数申请空间,并使用 delete、free 释放;静态存储期对象一般位于静态存储区,而不是栈上。栈上通常是函数内的自动变量。
CUDA 中也有类似的动态分配和静态声明之分。我们前面用到的很多设备内存都是通过 cudaMalloc 动态分配的。与动态分配类似,静态声明的设备端变量也需要显式地将内存复制到设备端。下面用一段代码来看一下程序的运行结果:
#include <cuda_runtime.h>
#include <stdio.h>
__device__ float devData;
__global__ void checkGlobalVariable()
{
printf("Device: The value of the global variable is %f\n", devData);
devData += 2.0;
}
int main()
{
float value = 3.14f;
cudaMemcpyToSymbol(devData, &value, sizeof(float));
printf("Host: copy %f to the global variable\n", value);
checkGlobalVariable<<<1, 1>>>();
cudaMemcpyFromSymbol(&value, devData, sizeof(float));
printf("Host: the value changed by the kernel to %f \n", value);
cudaDeviceReset();
return EXIT_SUCCESS;
}
其中的 cudaMemcpyToSymbol(devData, &value, sizeof(float));,是由于 __device__ float devData; 是 Device 上的变量定义,和 Host 变量定义不同。在主函数中,全局变量的值通过 cudaMemcpyToSymbol 初始化,在 Kernel 中运行完后,新的值通过 cudaMemcpyFromSymbol 复制回 Host。
虽然上面 Device 和 Host 的代码在同一个文件中,也在同一个文件中可见,但是 Host 代码不能直接访问 Device 变量,反之亦然。
总结
Table 1 CUDA 变量和类型修饰符
| 修饰符 | 变量名称 | 存储器 | 作用域 | 生命周期 |
|---|---|---|---|---|
float var |
寄存器 | 线程 | 线程 | |
float var[100] |
本地 | 线程 | 线程 | |
__shared__ |
float var* |
共享 | 块 | 块 |
__device__ |
float var* |
全局 | 全局 | 应用程序 |
__constant__ |
float var* |
常量 | 全局 | 应用程序 |
Table 2 设备存储器特征
| 存储器 | 片上 / 片外 | 缓存 | 存取 | 范围 | 生命周期 |
|---|---|---|---|---|---|
| 寄存器 | 片上 | n/a | R/W | 一个线程 | 线程 |
| 本地 | 片外 | 2.x 以上设备 | R/W | 一个线程 | 线程 |
| 共享 | 片上 | n/a | R/W | 块内所有线程 | 块 |
| 全局 | 片外 | 2.x 以上设备 | R/W | 所有线程 + 主机 | 主机配置 |
| 常量 | 片外 | Yes | R | 所有线程 + 主机 | 主机配置 |
| 纹理 | 片外 | Yes | R | 所有线程 + 主机 | 主机配置 |
评论