

内存管理
内存分配和释放
CUDA编程模型存在HOST和DEVICE两个异构系统,每个异构系统都有独立的内存空间。
在HOST上,可以使用下面语句分配全局内存:
cudaError_t cudaMalloc(void ** devPtr,size_t count)要注意的是第一个参数,是指针的指针。函数执行失败会返回 cudaErrorMemoryAllocation 。
分配完地址后,使用下面函数初始化:
cudaError_t cudaMemset(void * devPtr,int value,size_t count)注意分配的内存在DEVICE上。
当内存不再使用,使用下面函数释放内存:
cudaError_t cudaFree(void * devPtr)这个函数中的参数是cudaMalloc 分配的空间,否则会返回cudaErrorInvalidDevicePointer 错误。
内存传输
分配好全局内存后,由于HOST不能访问DEVICE内存,反之亦然,所以需要传输数据:
cudaError_t cudaMemcpy(void *dst,const void * src,size_t count,enum cudaMemcpyKind kind)注意参数是指针,而非指针的指针,第一个参数dst是目标地址,第二个参数src是原始地址,然后是拷贝内存的大小,最后的kind是复制的方向,方向包括以下几种:
cudaMemcpyHostToHostcudaMemcpyHostToDevicecudaMemcpyDeviceToHostcudaMemcpyDeviceToDevice
固定内存
在CUDA架构的HOST端,内存分为两种,一种是可分页内存(pageable memroy), 一种是页锁定内存(pinned memory)。可分页内存由操作系统API malloc()在主机上分配,页锁定内存是由CUDA函数cudaMallocHost()和cudaHostAlloc()在HOST内存中分配。
页锁定内存的重要属性是HOST的OS将不会对这块内存进行分页和交换操作,确保该内存始终保留在物理内存中。实质是让OS在物理内存中完成内存申请和释放的工作,不参与页交换,提高系统效率。GPU知道页锁定内存的物理地址,可以通过直接内存访问(Direct Memory Access,DMA) 技术直接在HOST和DEVICE间复制数据,速率很快。由于每个页锁定内存都需要分配物理内存,并且这些内存不能交换到磁盘上,所以页锁定内存比使用标准malloc()分配的可分页内存更消耗内存空间[1]。
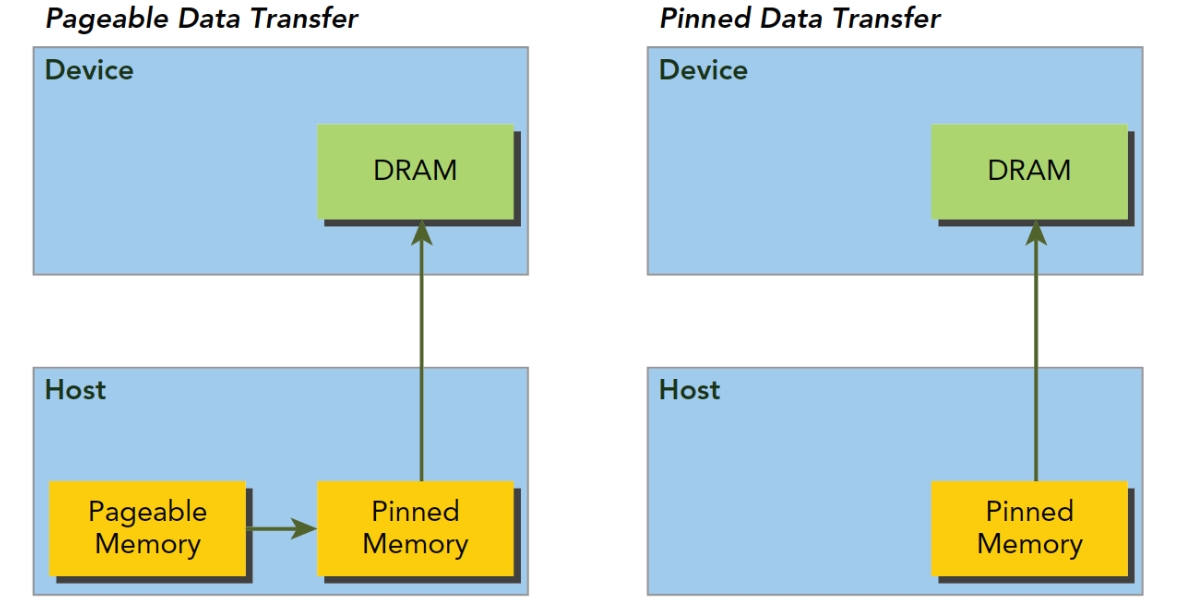
GPU不能在可分页的HOST内存上安全的访问数据,因为当HOST在物理位置上移动数据时,DEVICE无法控制。可分页内存从HOST到DEVICE的过程参见上图左。
CUDA运行时可以使用下面指令直接分配固定主机的内存:
cudaError_t cudaMallocHost(void ** devPtr,size_t count)分配count字节的固定内存,这些内存是页锁定的,可以直接传输到DEVICE端。
HOST内存释放必须使用:
cudaError_t cudaFreeHost(void *ptr)页锁定内存虽然分配和释放成本更高,但是为大规模数据传输提供更大吞吐量。
零拷贝内存
前面说的内容都是:HOST不可以直接访问DEVICE内存,反之亦然。零拷贝内存(Zero-Copy)是个例外,HOST和DEVICE都可以访问零拷贝内存。
CUDA的Kernel使用零拷贝内存有以下集中情况:
当设备内存不足的时候可以利用主机内存
避免主机和设备之间的显式内存传输
提高PCIe传输率
要注意,使用零拷贝共享HOST和DEVICE间数据时,必须同步HOST和DEVICE间的内存访问,即避免内存竞争。
零拷贝内存是页锁定内存,该捏村映射到设备空间地址中,通过以下函数创建固定到内存的映射:
cudaError_t cudaHostAlloc(void ** pHost,size_t count,unsigned int flags)其中flags 参数可以有以下值:
cudaHostAllocDefalt:和cudaMallocHost函数一致。cudaHostAllocPortable:返回能被所有CUDA上下文使用的固定内存,而非指定内存分配的那个。cudaHostAllocWriteCombined:返回写结合内存,在特定系统配置下通过PCIe传输很快,对缓冲区来说是个很好的选择。cudaHostAllocMapped:产生零拷贝内存
此时DEVICE还不能通过pHost直接访问对应的内存地址,DEVICE要访问HOST上的零拷贝内存,需要先获得另一个地址,这个地址让DEVICE访问到HOST对应的内存,方法是:
cudaError_t cudaHostGetDevicePointer(void ** pDevice,void * pHost,unsigned flags);此处的flags 要置0,原因以后会说。
还得注意,因为每次都要经过PCIe,在频繁读写操作时,零拷贝内存的效率将显著降低。而且仅适用于HOST和DEVICE间的少量数据传输,当有大量数据传输时,性能也会显著下降。在《CUDA C编程权威指南》和谭升老师的Blog中都对此进行了测试。
统一虚拟寻址
CUDA 4.0 之后的版本开始支持统一虚拟寻址(Unified Virtual Addressing,UVA)。在UVA出现之前,我们需要管理哪些指针指向HOST内存,哪些指针指向DEVICE内存。UVA使得指针指向的内存空间对程序代码变成了透明的。

通过UVA,cudaError_t cudaHostGetDevicePointer(void ** pDevice,void * pHost,unsigned flags); 这个函数无需再使用,通过cudaHostAlloc 返回的指针可以直接传递给Kernel。
统一内存寻址
CUDA 6.0 中又引入了统一内存寻址(Uniform Memory Access,UMA)这个特性。不同于UVA,UMA的目的是简化内存管理。它会创建一个托管内存池,池中已分配的空间可以用相同的内存地址(指针)在HOST和DEVICE上进行访问。底层系统在统一的内存空间中自动进行DEVICE和HOST间的传输。
UMA依赖与UVA,但是二者又完全不同。UVA为系统所有处理器提供了一个单一的虚拟内存地址空间,但UVA不会自动将数据转移。
托管内存指的是由系统底层自动分配的统一内存,未托管内存就是我们自己分配的内存。可以同时传递给Kernel两种类型的内存,已托管和未托管内存。托管内存可以是静态的,也可以是动态的,添加 managed 关键字修饰托管内存变量。静态声明的托管内存作用域是文件,这一点可以注意一下[3]。
cudaError_t cudaMallocManaged(void ** devPtr,size_t size,unsigned int flags=0)所有托管内存必须在HOST代码上动态声明,或者全局静态声明。DEVICE代码不能调用上面的函数。
内存访问模式
我们所编写的GPU程序容易受到内存带宽的限制,因此,最大限度利用全局内存带宽是提高Kernel性能的重要手段。
CUDA执行模型的特征之一就是指令必须以Warp为单位发布和执行。存储操作也是如此。
对齐与合并访问
全局内存(DRAM)通过缓存来实现加载和存储,所有对全局内存的访问都会通过L2 Cache,也有些访问会通过L1 Cache。
当Kernel从DRAM中读取数据时,有两种缓存粒度,128Byte和32Byte。哪怕读1个Byte的变量,也会读128Byte。CUDA支持通过编译指令停用L1 Cache。如果启用L1 Cache,那么每次从DRAM上加载数据的粒度是128Byte,如果不用L1 Cache,只用L2 Cache,那粒度是32Byte。
SM执行的基础是线程束,也就是说,当一个SM中正在被执行的某个线程需要访问内存,那么,和它同线程束的其他31个线程也要访问内存,这个基础就表示,即使每个线程只访问一个字节,那么在执行的时候,只要有内存请求,至少是32个字节,所以不使用一级缓存的内存加载,一次粒度是32字节而不是更小[5]。
所以在优化程序时,需要注意设备内存访问的2个特性:
对齐内存访问
合并内存访问
当设备内存事务的第一个地址,是用于事物服务的缓存粒度的偶数倍(32Byte L2 Cache 或 128Byte L1 Cache),会出现对齐内存访问。非对齐的加载会造成带宽浪费。
当一个Warp中的32个Thread访问一个连续内存Block时,会出现合并内存访问。
下图描述了对齐与合并内存的加载操作,其中蓝色表示全局内存,橙色是Warp要的数据,绿色是对齐的地址段:
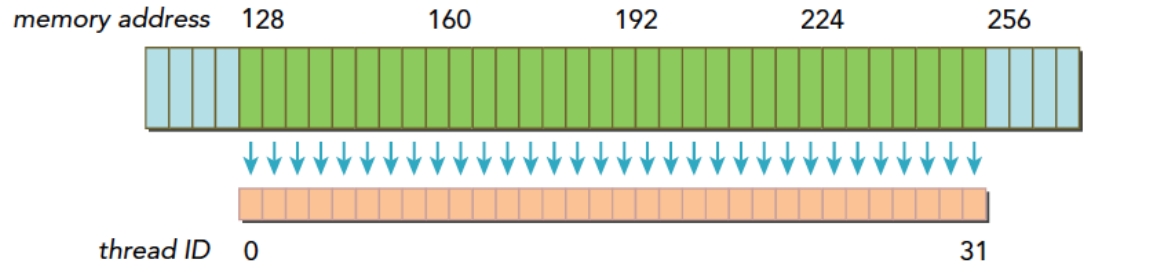
下图描述了非对齐和未合并的内存访问:
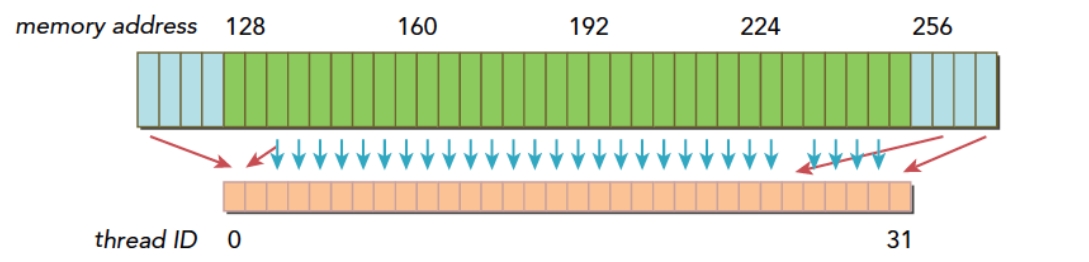
上图的情况下,thread0在128之前,还有请求在256之后,很明显需要3个内存事务,内存利用率为对齐和合并情况下的1/3。在极端情况下,每个thread的请求都在不同的段,利用率会变成1/128。
全局内存读取
在SM中,根据不同设备和类型,加载数据有三种途径:
L1/L2 Cache
常量缓存
只读缓存
默认情况下会通过L1/L2 Cache,如果想通过其他途径需要显式地说明。禁用L1 Cache的编译器选项为-Xptxas -dlcm=cg ,启用L1为-Xptxas -dlcm=ca
如果L1 Cache被禁用,那么所有对全局内存的加载请求会直接进入L2 Cache;如L2 Cache缺失,则由DRAM完成请求。
内存加载可分为2类:
缓存加载
没有缓存的加载
内存加载的访问模式有几个特点:
有无Cache,如启用L1 Cache,则内存加载被缓存
对齐&非对齐:如内存访问首地址为32倍数,则对齐加载
合并&非合并:如Warp访问一个连续的数据块,则加载合并
缓存加载
缓存加载操作会经过L1 Cache,下图为理想情况,对齐与合并的内存访问,利用率100%

下图为对齐访问,但引用地址不是连续ID,而是128Byte内的随机值,不过由于thread访问的数据都在一个block内,利用率也是100%

下图为warp请求连续的非对齐的,32个4Byte数据,数据横跨2个block,需要2个128Byte的事务,利用率50%。

下图warp中所有thread都请求相同的地址,只需请求一个内存事务。如果请求的数据为4Byte,那么利用率为4/128=3.125%

下图是最差的情况,warp中所有thread请求分散的32个4Byte地址,所有数据分布在N个缓存行(1行L1 Cache=128Byte)上,请求32个4Byte的数据,就需要N个内存事务,利用率为1/N。

GPU的L1 Cache可以通过编译选项等控制,CPU不可以。而且CPU的L1 Cache有使用频率和时间局限性,GPU则没有。
无缓存加载
相比L1 Cache加载,内存段粒度从128变成了32Byte,更细粒度的加载会带来更好的总线利用率。下图是一种理想情况,对齐与合并的内存访问,总线利用率100%:

下图为一种随机访问,但是利用率也是100%:

下图为连续但是不对齐的情况,请求的地址落在5个内存段内(连续的情况下,不可能超过5个),利用率至少为80%:

下图为Warp中所有Thread都请求相同的数据,地址落在同1个内存段内。利用率为4(请求4Byte)/32(加载32Byte)=12.5%:

下图是最坏的情况,Warp请求32个分散在全局内存中4Byte的数据,由于请求的128个字节Byte最多落在N个32Byte的内存分段内而不是N个128Byte的内存分段内,比Figure4-13的情况还要好些。

只读缓存
只读缓存是留给纹理内存加载用的。在目前的设备中,只读缓存也支持使用全局内存加载代替L1 Cache。
只读缓存的加载粒度是32Byte。有两种方式可以指导内存通过只读缓存进行读取:
函数
__1dg(2个_)间接引用的指针上使用修饰符
下面代码使用函数__1dg 通过只读缓存直接对数组进行读取访问:
__global__ void copyKernel(float * in,float* out){
int idx=blockDim*blockIdx.x+threadIdx.x;
out[idx]=__ldg(&in[idx]);
}也可以使用__restrict__ 修饰符应用到指针上。这些修饰符帮助nvcc编译器识别无别名指针。
__global__ void copyKernel_2(int *__restrict__ out,const int *__restrict__ in){
int idx = blockIdx.x*blockDim.x+threadIdx.x;
out[idx] = in[idx];
}全局内存写入
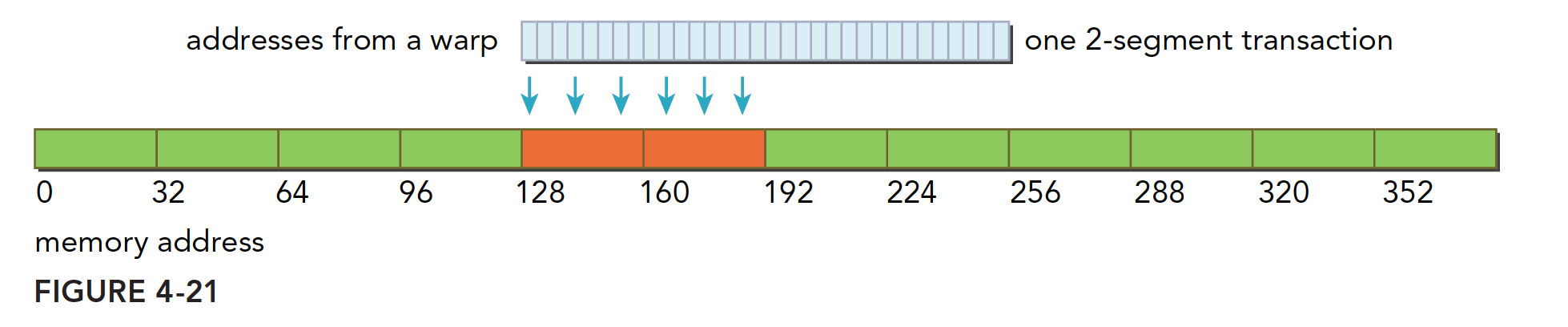
内存的写入和加载(读取)是不同的,写入相对简单些。L1 Cache不能进行存储操作,发送到Device前只能经过L2 Cache,存储操作在32个Byte的粒度上进行,内存事务也会被分为1段、2段或者4段。e.g. 如果2个地址属于一个128Byte的区域,但是不属于一个对齐的64Byte区域,则会执行一个4段事务。
下图是理想情况,对齐的内存访问,并且Warp中所有Thread访问一个连续的128Byte范围。存储操作使用一个4段事务完成。
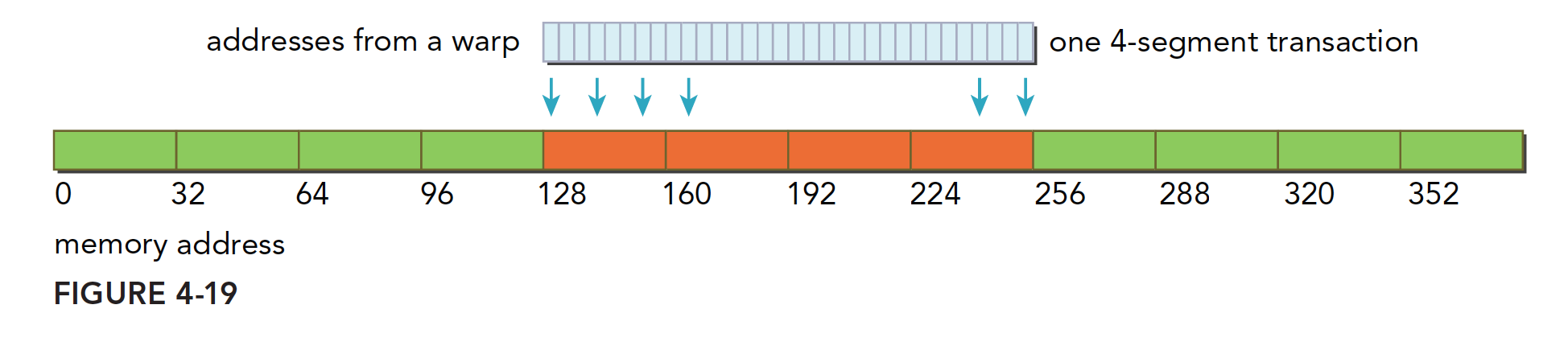
下图数据分散在一个192字节的范围内,不连续,使用三个1段事务完成。

下图为对齐的访问,在一个64Byte的范围内,使用一个2段事务完成。
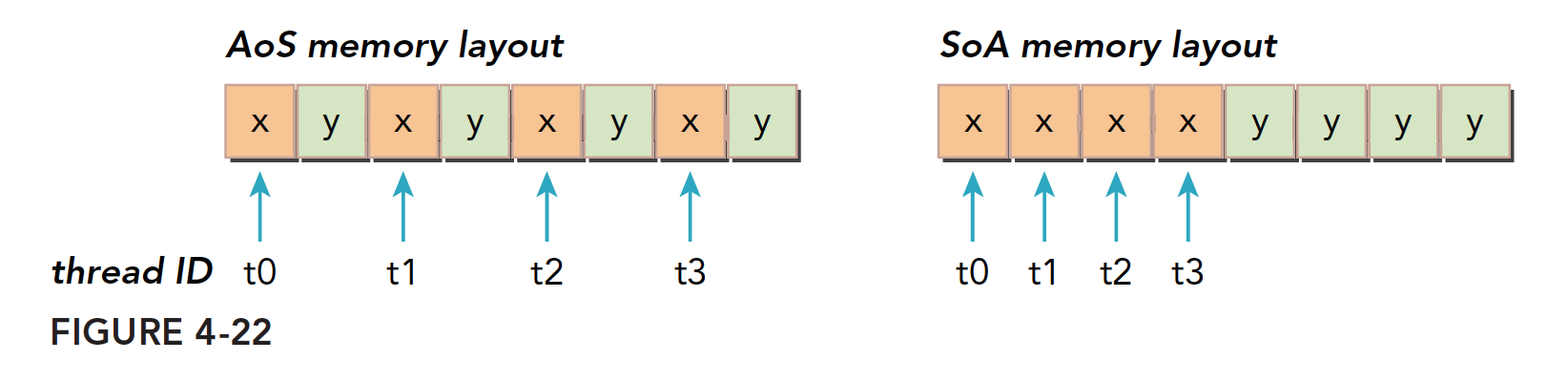
结构体数组(SoA)& 数组结构体(AoS)
SoA本质上是结构体,AoS本质上是数组。
如果使用AoS方法存储数据,先定义一个结构体,再定义一个结构体的数组。存储的是空间中相邻的数据,比如x和y,在CPU上有较好的缓存局部性。
// Array of structures (AOS)
struct AoS{
float x, y, z, w
};
AoS myAoS[N];如果是SoA方式存储数据,在原结构体中的每个字段中的值都被分发到各自的数组中。这不仅能将相邻数据点紧密存储,还可以跨数组保存数据。
// Structure of arrays (SOA)
struct SoA{
float x[N];
float y[N];
};
SoA mySoA;如何区分AoS和SoA呢?我区分不了...(笑
其实SoA和AoS的中文名称是很容易让人困惑的,因为结构体数组SoA的全程是Structure of Array——数组的结构体,不知道为什么直接翻译过来还省略了of...这样就很好理解了,数组的结构体,本质是一个结构体,再看它的实例化,也是声明为结构体;数组结构体AoS全称Array of Structure——结构体的数组,本质是一个数组,再看它的实例化,也是实例化为一个数组。
下图说明了两种方法的内存布局。
AoS模式在GPU上存储数据并执行一个只有x字段的代码,会导致50%的带宽损失,同时AoS在不需要存储的y变量上浪费了存储空间。
SoA模式可以充分列用GPU内存带宽,可以实现更高效的全局内存利用。
指针数组和数组指针
单纯的复习一下...
指针数组:可以说成是指针的数组,首先是一个数组,数组的所有元素都是指针类型。
数组指针:可以说成是数组的指针,首先是一个指针,指针存放着一个数组的首地址,或者说这个指针指向一个数组的首地址。
AoS进行简单数学运算
#include <cuda_runtime.h>
#include <stdio.h>
#include "freshman.h"
struct naiveStruct{
float a;
float b;
};
void sumArrays(float * a,float * b,float * res,const int size){
for(int i=0;i<size;i++){
res[i]=a[i]+b[i];
}
}
__global__ void sumArraysGPU(float*a,float*b,struct naiveStruct* res,int n){
//int i=threadIdx.x;
int i=blockIdx.x*blockDim.x+threadIdx.x;
if(i<n)
res[i].a=a[i]+b[i];
}
void checkResult_struct(float* res_h,struct naiveStruct*res_from_gpu_h,int nElem){
for(int i=0;i<nElem;i++)
if (res_h[i]!=res_from_gpu_h[i].a){
printf("check fail!\n");
exit(0);
}
printf("result check success!\n");
}
int main(int argc,char **argv){
int dev = 0;
cudaSetDevice(dev);
int nElem=1<<18;
int offset=0;
if(argc>=2)
offset=atoi(argv[1]);
printf("Vector size:%d\n",nElem);
int nByte=sizeof(float)*nElem;
int nByte_struct=sizeof(struct naiveStruct)*nElem;
float *a_h=(float*)malloc(nByte);
float *b_h=(float*)malloc(nByte);
float *res_h=(float*)malloc(nByte_struct);
struct naiveStruct *res_from_gpu_h=(struct naiveStruct*)malloc(nByte_struct);
memset(res_h,0,nByte);
memset(res_from_gpu_h,0,nByte);
float *a_d,*b_d;
struct naiveStruct* res_d;
CHECK(cudaMalloc((float**)&a_d,nByte));
CHECK(cudaMalloc((float**)&b_d,nByte));
CHECK(cudaMalloc((struct naiveStruct**)&res_d,nByte_struct));
CHECK(cudaMemset(res_d,0,nByte_struct));
initialData(a_h,nElem);
initialData(b_h,nElem);
CHECK(cudaMemcpy(a_d,a_h,nByte,cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(b_d,b_h,nByte,cudaMemcpyHostToDevice));
dim3 block(1024);
dim3 grid(nElem/block.x);
double iStart,iElaps;
iStart=cpuSecond();
sumArraysGPU<<<grid,block>>>(a_d,b_d,res_d,nElem);
cudaDeviceSynchronize();
iElaps=cpuSecond()-iStart;
CHECK(cudaMemcpy(res_from_gpu_h,res_d,nByte_struct,cudaMemcpyDeviceToHost));
printf("Execution configuration<<<%d,%d>>> Time elapsed %f sec\n",grid.x,block.x,iElaps);
sumArrays(a_h,b_h,res_h,nElem);
checkResult_struct(res_h,res_from_gpu_h,nElem);
cudaFree(a_d);
cudaFree(b_d);
cudaFree(res_d);
free(a_h);
free(b_h);
free(res_h);
free(res_from_gpu_h);
return 0;
}SoA进行简单数学运算
#include <cuda_runtime.h>
#include <stdio.h>
#include "freshman.h"
void sumArrays(float * a,float * b,float * res,int offset,const int size){
for(int i=0,k=offset;k<size;i++,k++){
res[i]=a[k]+b[k];
}
}
__global__ void sumArraysGPU(float*a,float*b,float*res,int offset,int n){
//int i=threadIdx.x;
int i=blockIdx.x*blockDim.x*4+threadIdx.x;
int k=i+offset;
if(k+3*blockDim.x<n){
res[i]=a[k]+b[k];
res[i+blockDim.x]=a[k+blockDim.x]+b[k+blockDim.x];
res[i+blockDim.x*2]=a[k+blockDim.x*2]+b[k+blockDim.x*2];
res[i+blockDim.x*3]=a[k+blockDim.x*3]+b[k+blockDim.x*3];
}
}
int main(int argc,char **argv)
{
int dev = 0;
cudaSetDevice(dev);
int block_x=512;
int nElem=1<<18;
int offset=0;
if(argc==2){
offset=atoi(argv[1]);
}
else if(argc==3){
offset=atoi(argv[1]);
block_x=atoi(argv[2]);
}
printf("Vector size:%d\n",nElem);
int nByte=sizeof(float)*nElem;
float *a_h=(float*)malloc(nByte);
float *b_h=(float*)malloc(nByte);
float *res_h=(float*)malloc(nByte);
float *res_from_gpu_h=(float*)malloc(nByte);
memset(res_h,0,nByte);
memset(res_from_gpu_h,0,nByte);
float *a_d,*b_d,*res_d;
CHECK(cudaMalloc((float**)&a_d,nByte));
CHECK(cudaMalloc((float**)&b_d,nByte));
CHECK(cudaMalloc((float**)&res_d,nByte));
CHECK(cudaMemset(res_d,0,nByte));
initialData(a_h,nElem);
initialData(b_h,nElem);
CHECK(cudaMemcpy(a_d,a_h,nByte,cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(b_d,b_h,nByte,cudaMemcpyHostToDevice));
dim3 block(block_x);
dim3 grid(nElem/block.x);
double iStart,iElaps;
iStart=cpuSecond();
sumArraysGPU<<<grid,block>>>(a_d,b_d,res_d,offset,nElem);
cudaDeviceSynchronize();
iElaps=cpuSecond()-iStart;
printf("warmup Time elapsed %f sec\n",iElaps);
iStart=cpuSecond();
sumArraysGPU<<<grid,block>>>(a_d,b_d,res_d,offset,nElem);
cudaDeviceSynchronize();
iElaps=cpuSecond()-iStart;
CHECK(cudaMemcpy(res_from_gpu_h,res_d,nByte,cudaMemcpyDeviceToHost));
printf("Execution configuration<<<%d,%d>>> Time elapsed %f sec --offset:%d \n",grid.x,block.x,iElaps,offset);
sumArrays(a_h,b_h,res_h,offset,nElem);
checkResult(res_h,res_from_gpu_h,nElem-4*block_x);
cudaFree(a_d);
cudaFree(b_d);
cudaFree(res_d);
free(a_h);
free(b_h);
free(res_h);
free(res_from_gpu_h);
return 0;
}性能调整
优化设备内存带宽利用率的目标有二:
对齐于合并内存访问,减少带宽浪费
足够并发的内存操作,隐藏内存延迟
之前优化吞吐量的内容中提到了,实现并发内存访问最大化是通过:
增加每个线程中执行独立内存操作的数量
对Kernel启动的配置进行试验
展开技术
包含内存操作的展开循环,增加更独立的内存操作
增大并行性
通过调整Block的大小来实现并行性调整
参考文章
[1] CUDA:页锁定内存(pinned memory)和按页分配内存(pageable memory ) - 牛犁heart - 博客园 (cnblogs.com)
[2] CUDA C++ / 内存管理以及优化 - Laplace蒜子 - 博客园 (cnblogs.com)
[3]【CUDA 基础】4.2 内存管理 | 谭升的博客 (face2ai.com)
[4] CUDA:cudaMalloc vs cudaMallocHost-CSDN博客
[5]【CUDA 基础】4.3 内存访问模式 | 谭升的博客 (face2ai.com)
评论