

写在前面
即便是完全依靠着CNN检测出的2D bbox可以估计目标的深度,但是后续的预测,规划和运动控制,都需要物体的3D信息。更何况,如果能恢复目标的3D信息,对测距精度的提高也有很大的帮助。
激光雷达和深度相机固然精度很高,但是贵。而且在Lidar和Depth Cam的基础上加入RGB单目相机可以增加系统冗余度,that is,可劲儿的融合。
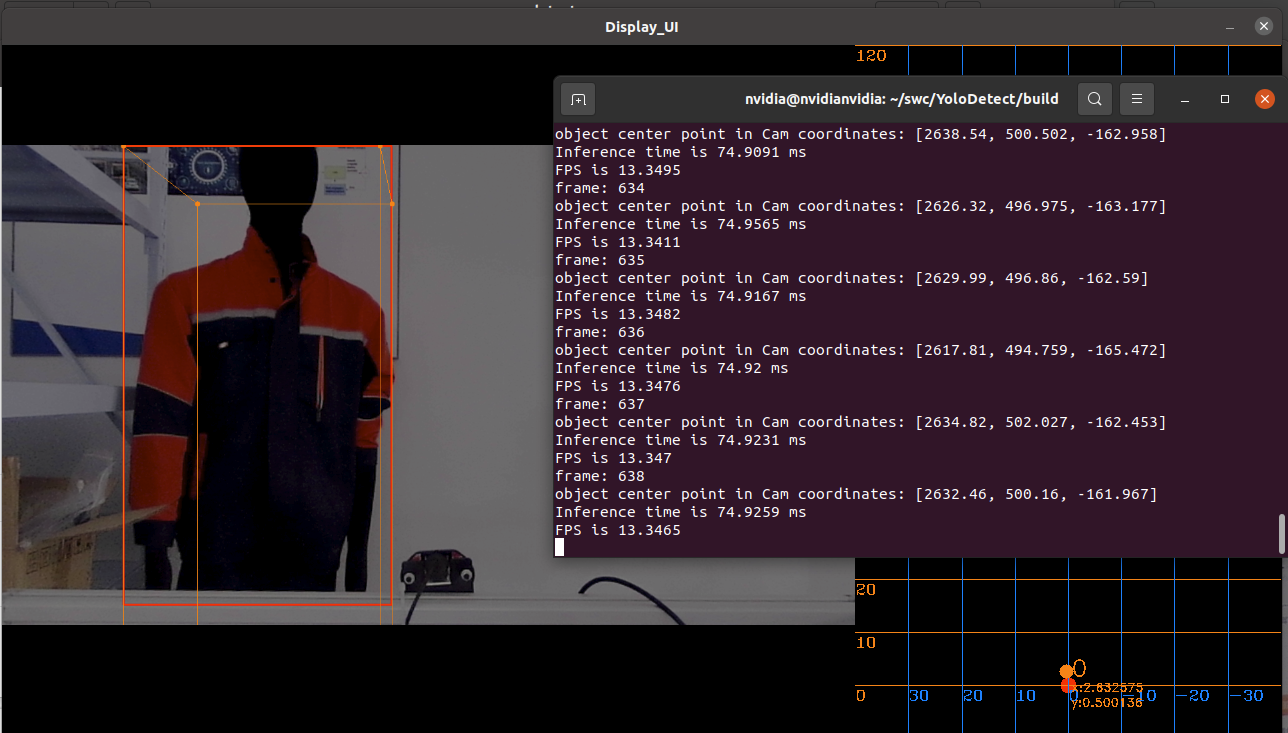
表征转换 - BEV
这是一种将目标从3D世界坐标简化为平面的 Birds-eye-view (BEV)坐标系,可以理解为是一种投影的方法。
将相机图像转换为BEV可以通过 Orthographic Feature Transform (OFT) 的方法,ResNet-18 (深度学习框架)被用来提取透视图像特征。然后通过在投影的 voxel area 积累基于图像的特征,生成基于voxel 的特征(类似CT图像重建的反投影?)。然后 voxel 沿着垂直与地面的坐标轴进行折叠,产生BEV角度的特征。最后另一个 ResNet 被用来推理并细化BEV图。
在这里 voxel 是体素,和点云(Point Clouds)类似,体素网格(Voxel Grids),多边形网格(Polygon meshes),多视图表示(Multi-view Representations)都可以用来表示3D数据。
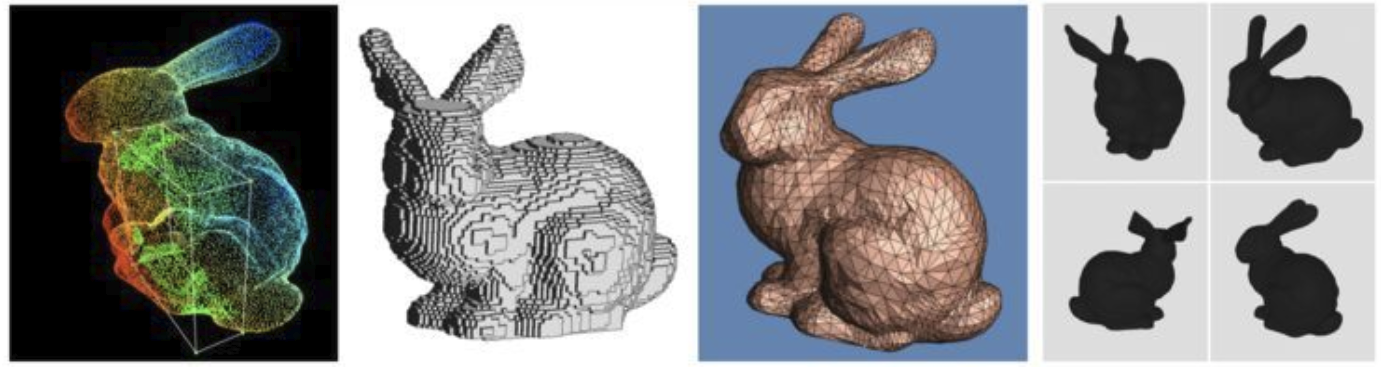
- 点云:三维空间(xyz坐标)点的集合。
- 体素:3D空间的像素。量化的,大小固定的点云。每个单元都是固定大小和离散坐标。可以当成是Minecraft中的cube。
- 多边形网格:是点(vertex)和面(face)的集合。
- 多视图表示:不同模拟视点渲染的2D图像集合。
此外,使用BirdGAN也可以实现相机图像到BEV的转换,但是实验结果显示,只有在正面距离10-15m的范围内,BirdGAN才有不错的效果,因此使用场景受限。
伪激光雷达 Pseudo Lidar
这类方法的思路是通过图像的估计深度生成点云,因此叫伪激光雷达。估计深度信息是通过使用MonoDepth( mrharicot/monodepth: Unsupervised single image depth prediction with CNNs (github.com) )的固定预训练权重将RGB图像的每个像素都投影到3D空间得到RGBD(Depth)图像,然后将生成的点云和图像的特征融合,最后回归得到3D bbox。


Pseudo Lidar的作者又提出了Pseudo Lidar++(mileyan/Pseudo_Lidar_V2: (ICLR) Pseudo-LiDAR++: Accurate Depth for 3D Object Detection in Autonomous Driving (github.com)),加入了低精度的Lidar来增强单目/双目相机生成的Pseudo Lidar点云。之所以用相机图像和稀疏点云结合,是因为稀疏点云中存在深度信息,这种方法可以显著提高相机估计深度的准确性。
此外,Pseudo Lidar Color还可以通过融合颜色信息 (x ,y,z) -> (x,y,z,R,G,B) 改善结果。
目前,Pseudo Lidar方法的瓶颈有两个:其一是深度估计不准确会导致局部错位,其二是物体外围的深度尾影造成的边缘泄漏。总的来说,此类方法都依赖于对目标的深度估计。
关键点和形状
这个思路是根据车辆和人目标的刚体假设,并且都拥有共同的特征,比如车头的角点,A/C柱和车顶的角点,人的头、肩等。此外车辆和行人的基本尺寸是已知的,尺寸包括目标整体尺寸和关键点间距。
这种方法大多是依靠2D物体检测模型,如YOLO或者RCNN来扩展到关键点。
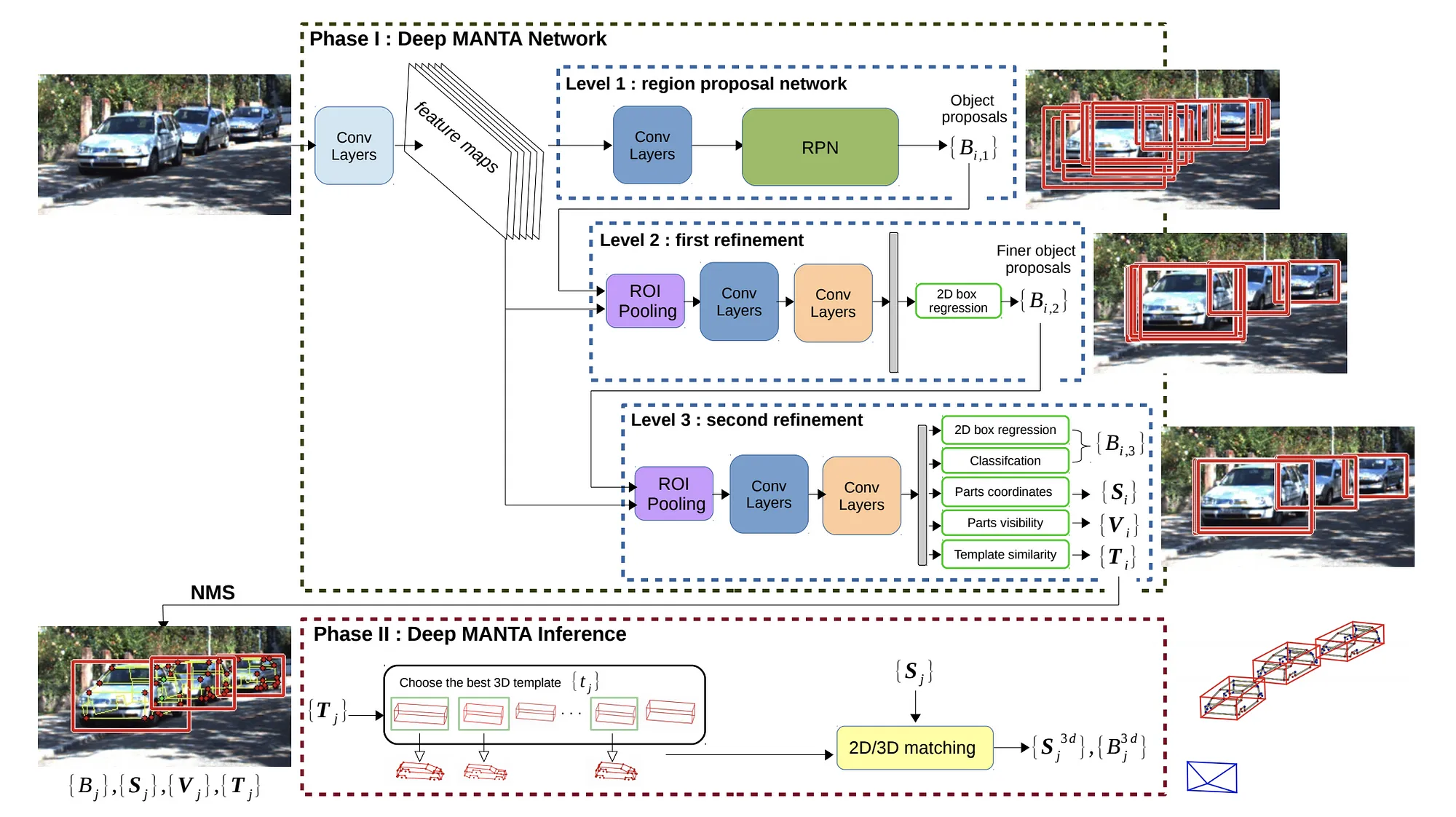
Deep MANTA 在第一阶段:训练和推理中,使用一个级联的RCNN架构获取2D bbox,关键点,和模板匹配度,模板是3D bbox (L,W,H)。在第二阶段,通过推理并结合模板匹配度,选择出最优的3D模型,并进行2D/3D 匹配(EPnP算法)来恢复3D的位置和方向。
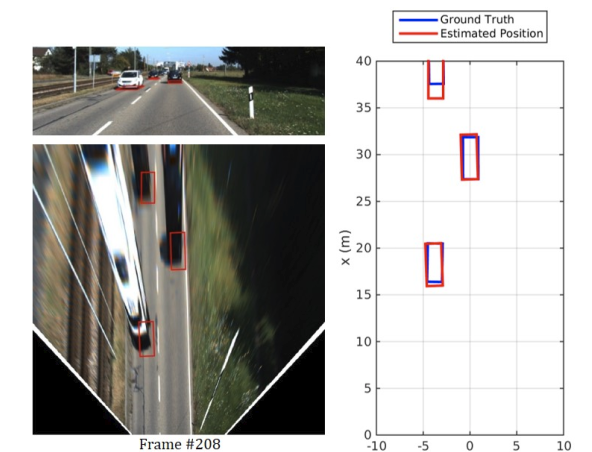
The Earth ain't Flat,这篇文章主要是为了解决目标在不平整道路上的目标重建。在这个算法中的关键是从单目相机图像中估计3D形状和6个DOF。它也结合了MANTA的36个关键点。但是它并不根据模板匹配度选择最好的3D bbox,而是使用基向量和变形系数来捕捉目标的形状,使用一组基础形状和他们的组合系数来代表目标的box。这个算法对真实数据有较好的概括性。
3D-RCNN 可以估计形状,姿态和尺寸等参数并渲染场景。但是这种方法需要很多的输入,如3D bbox,3D CAD模型,2D 实例分割等。因此不再赘述。
此外,RoI-10D,Mono3D++ ,MonoGRNet,MonoGRNet V2等相似算法都使用semi-automatic的方式,通过将CAD模型和3D bbox ground truth结合来标注3D关键点。但是大规模对目标关键点进行标注是非常复杂且耗时的。目前仅有百度ApolloScape提供了密集关键点标注和mesh格式形状的数据集。
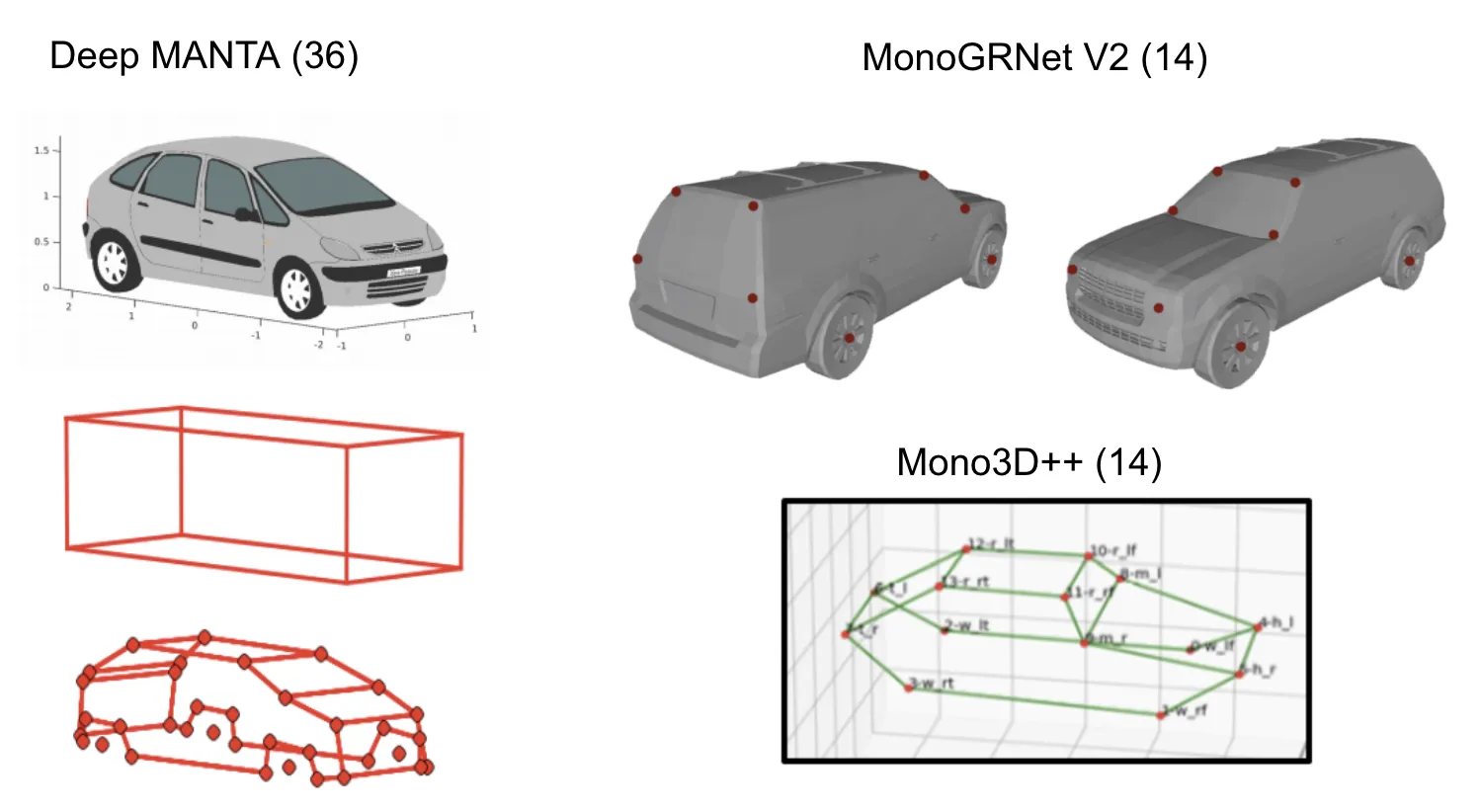
Ground Plane Polling (GPP) 则是自动生成3D bbox注释的虚拟关键点。它预测了比估计 3D bbox 所需的更多的信息,并使用这些预测信息生成公共属性集,方式类似于RANSAC(随机抽样一致),对异常值非常 robust。
RTM3D (real-time mono-3D) 也使用虚拟关键点,并且使用类似 CenterNet 的结构直接检测8个立方体 vertex + 立方体中心的 2D 投影。这种方法还回归了距离、方向和大小。这个算法是第一个实时单目 3D 目标检测算法(0.055秒/帧)。
受 CenterNet 的启发,SMOKE (Single-Stage Monocular 3D Object Detection via Keypoint Estimation)放弃了2D bbox回归,直接预测 3D bbox。将3D bbox 编码为3D立方体中心投影上的一个点,尺寸、距离、偏航角为其附加属性。这种算法还实现了在60m内小于5%的距离预测误差。代码:https://github.com/lzccccc/SMOKE
Monocular 3D Object Detection with Decoupled Structured Polygon Estimation and Height-Guided Depth Estimation 这篇论文指出了3D vertex的2D 投影估计(结构化多边形)和深度估计解耦的方法。它使用与 RTM3D 类似的方法对立方体的八个投影点进行回归,然后使用垂直边缘高度作为指导距离估计的强先验信息。由此得到一个粗略的 3D 立方体,这个 3D 立方体可以用作 BEV 的种子位置,这种方法比 Pseudo Lidar 的结果更加理想。
Monoloco与上述方法有点不同,因为它专注于回归行人的位置,因为行人不是刚体,有各种姿势,所以预测行人的位置更加困难。它使用关键点检测器(自上而下的,如Mask RCNN或自下而上的)来提取行人的关键点。它利用行人相对固定的高度,特别是肩部到臀部这一段(约50厘米)来推断深度,与MonoGRNet V2的做法相似。该方法使用多层感知器(Full Connected Neural Network)将深度与所有关键点线段的长度进行回归。
通过2D/3D限制进行测距
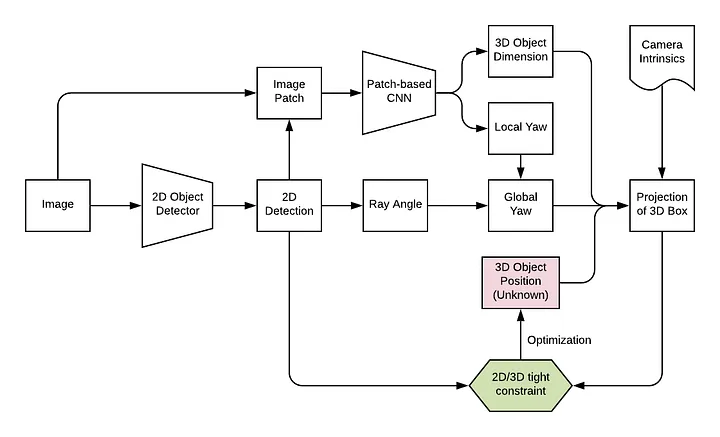
FQNet 为Deep3DBox增加了一个细化的阶段,即在3D种子位置周围进行密集采样,再利用渲染得到的3D线框对2D patch进行评分。不过密集采样需要大量时间,因此算法实时性较差。
Shift R-CNN 通过主动回归 Deep3DBox 提出的尺寸偏移量,避免了密集采样。所有已知的2D和3D bbox都作为ShiftNet全连接网络的输入,并细化3D 位置。
MVRA 在神经网络中加入了2D/3D的约束,并迭代地细化被截断的box。它引入了一个3D重建层,将2D提升为3D。这个算法认识到了Deep3DBox不能处理被截断的box,被截断的box意味着它的vertex不对应真实的物体范围。因此它对截断的box迭代地使用3个约束(不是4个约束)的方向细化,全局偏航角通过两次迭代中在 \pi/8 和 \pi/32区间的试验和错误进行估计。
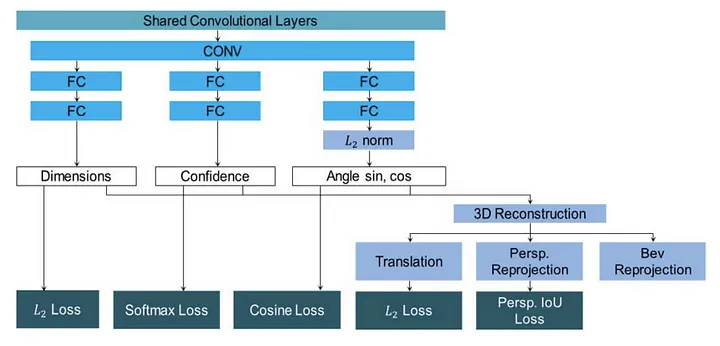
MonoPSR 首先生成3D预测,然后重建物体的局部点云。中心点预测阶段使用2D bbox的height和回归得到的3D height来估计深度,并在估计深度的基础上将2D bbox 重投影至3D空间。它的3D预测比较准确,平均绝对误差 \pm1.5 m。
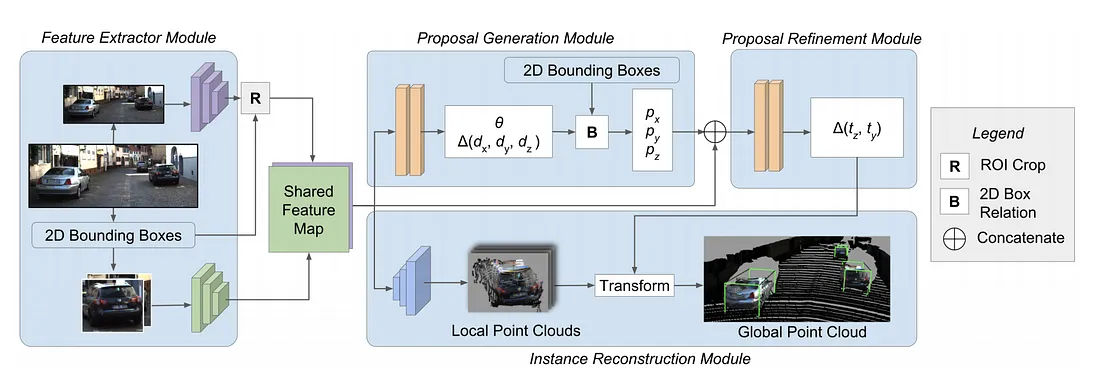
GS3D 基于 Faster RCNN框架。使用本地方向和从2D bbox 高度估计的距离生成一个粗略的3D bbox。深度估计使用了一个统计先验:即3D Bbox的height在 2D图像中的投影大约是2D bbox height的0.93倍,这个先验是通过分析训练数据集得到的。此外它还使用了RoIAlign拓展的表面特征提取算法来改善3D检测的结果。

直接生成3D bbox
MonoDIS 基于扩展的RetinaNet架构直接回归2D bbox和3D bbox。它并没有直接监督2D和3D bbox输出的每个部分,而是从整体上进行bbox回归。它的思想主要是为不同距离的目标学习不同的表征,但是模型对超出训练距离范围的目标缺乏泛用性。为了增强在远距离的表现,必须增加模型的容量和相应的训练数据。
CenterNet是一个多功能的物体检测框架,可以扩展到许多检测相关的任务,如关键点检测、深度估计、方向估计等。它首先回归一个表示物体中心位置置信度的HeatMap,并回归其它物体属性。将CenterNet扩展到包括二维和三维物体检测是一种很直接的方法。
SS3D使用类似CenterNet的结构,首先找到物体的潜在中心,然后同时回归2D和3D bbox。回归任务对2D和3D bbox信息进行回归,为优化提供了更充分的信息。在一个2D和3D bbox 元组的参数化中,总共有26个代理元素。总损失是26个元素的加权损失,其中的权重是动态学习的。损失函数有fake局部最小值,训练可以从基于启发式算法的初始估计得到改善。
直接生成3D bbox通常使用启发式方法或2D物体检测,例如,汽车通常在地面上,汽车的3D bbox都在其相应的2D bbox所包围的区域内,等等。
参考文章
[1] Kim, Y. and Kum, D., 2019, June. Deep learning based vehicle position and orientation estimation via inverse perspective mapping image. In 2019 IEEE Intelligent Vehicles Symposium (IV) (pp. 317-323). IEEE.
[2] Roddick, T., Kendall, A. and Cipolla, R., 2018. Orthographic feature transform for monocular 3d object detection. arXiv preprint arXiv:1811.08188.
[3] Srivastava, S., Jurie, F. and Sharma, G., 2019, November. Learning 2d to 3d lifting for object detection in 3d for autonomous vehicles. In 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (pp. 4504-4511). IEEE.
[4] Xu, B. and Chen, Z., 2018. Multi-level fusion based 3d object detection from monocular images. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2345-2353).
[5] Wang, Y., Chao, W.L., Garg, D., Hariharan, B., Campbell, M. and Weinberger, K.Q., 2019. Pseudo-lidar from visual depth estimation: Bridging the gap in 3d object detection for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 8445-8453).
[6] You, Y., Wang, Y., Chao, W.L., Garg, D., Pleiss, G., Hariharan, B., Campbell, M. and Weinberger, K.Q., 2019. Pseudo-lidar++: Accurate depth for 3d object detection in autonomous driving. arXiv preprint arXiv:1906.06310.
[7] Chabot, F., Chaouch, M., Rabarisoa, J., Teuliere, C. and Chateau, T., 2017. Deep manta: A coarse-to-fine many-task network for joint 2d and 3d vehicle analysis from monocular image. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2040-2049).
[8] Ansari, J.A., Sharma, S., Majumdar, A., Murthy, J.K. and Krishna, K.M., 2018, October. The earth ain't flat: Monocular reconstruction of vehicles on steep and graded roads from a moving camera. In 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (pp. 8404-8410). IEEE.
[9] Li, P., Zhao, H., Liu, P. and Cao, F., 2020. Rtm3d: Real-time monocular 3d detection from object keypoints for autonomous driving. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16 (pp. 644-660). Springer International Publishing.
[10] Rangesh, A. and Trivedi, M.M., 2020. Ground plane polling for 6dof pose estimation of objects on the road. IEEE Transactions on Intelligent Vehicles, 5(3), pp.449-460.
[11] Liu, Z., Wu, Z. and Tóth, R., 2020. Smoke: Single-stage monocular 3d object detection via keypoint estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (pp. 996-997).
[12] Cai, Y., Li, B., Jiao, Z., Li, H., Zeng, X. and Wang, X., 2020, April. Monocular 3d object detection with decoupled structured polygon estimation and height-guided depth estimation. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 34, No. 07, pp. 10478-10485).
[13] Bertoni, L., Kreiss, S. and Alahi, A., 2019. Monoloco: Monocular 3d pedestrian localization and uncertainty estimation. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 6861-6871).
[14] Mousavian, A., Anguelov, D., Flynn, J. and Kosecka, J., 2017. 3d bounding box estimation using deep learning and geometry. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (pp. 7074-7082).
[15] Liu, L., Lu, J., Xu, C., Tian, Q. and Zhou, J., 2019. Deep fitting degree scoring network for monocular 3d object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 1057-1066).
[16] Naiden, A., Paunescu, V., Kim, G., Jeon, B. and Leordeanu, M., 2019, September. Shift r-cnn: Deep monocular 3d object detection with closed-form geometric constraints. In 2019 IEEE international conference on image processing (ICIP) (pp. 61-65). IEEE.
[17] Choi, H.M., Kang, H. and Hyun, Y., 2019, October. Multi-view reprojection architecture for orientation estimation. In 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW) (pp. 2357-2366). IEEE.
[18] Ku, J., Pon, A.D. and Waslander, S.L., 2019. Monocular 3d object detection leveraging accurate proposals and shape reconstruction. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 11867-11876).
[19] Li, B., Ouyang, W., Sheng, L., Zeng, X. and Wang, X., 2019. Gs3d: An efficient 3d object detection framework for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 1019-1028).
[20] Simonelli, A., Bulo, S.R., Porzi, L., López-Antequera, M. and Kontschieder, P., 2019. Disentangling monocular 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 1991-1999).
[21] Jörgensen, E., Zach, C. and Kahl, F., 2019. Monocular 3d object detection and box fitting trained end-to-end using intersection-over-union loss. arXiv preprint arXiv:1906.08070.
[22]https://towardsdatascience.com/geometric-reasoning-based-cuboid-generation-in-monocular-3d-object-detection-5ee2996270d1 Lifting 2D object detection to 3D in autonomous driving
[23]https://towardsdatascience.com/monocular-3d-object-detection-in-autonomous-driving-2476a3c7f57e Monocular 3D Object Detection in Autonomous Driving — A Review
评论