

LSS是NVIDIA在ECCV2020上发表的文章。
理解一下论文标题中的Lift, Splat, Shoot三个单词。
这三个单词对应模型中三个核心步骤。
Lift:提升。2D图像特征提升到3D视锥空间特征。
Splat:泼溅。所有相机生成的3D视锥特征,泼洒到统一的BEV平面网格。
Shoot:发射。向BEV代价图中发射预生成的轨迹模板,实现E2E的运动规划。
如果使用多个单目相机传感器,要使用多个单图像的Detector,然后根据相机内外参,将每个Detector的结果平移到自车坐标系。这类方法具备三大对称性,也是优势:
平移等变性:若图像内的像素坐标整体平移,Detector的输出也同步平移。
置换不变性:最终自车系得预测结果,与相机位置无关。
自车系等距等变性:相机相对自车的空间位置,不会影响检测结果;若自车系旋转平移,则预测结果也旋转平移。
这类方法的缺陷是:
自车系的预测结果无法通过反向传播到原始传感器输入,模型无法通过数据学习跨相机信息融合的策略
没法利用运动规划模块的反馈,感知和规划模块依然是独立的
LSS
Lift
对相机中的每张图像单独处理,将单张图像从2D像素坐标系Lift到所有相机共享的3D世界坐标系,生成视锥(frustum)3D特征点云。
每个像素不是预测单一深度值,而是生成所有可能深度下的特征表征。
Step1
为每个像素生成离散深度的3D点云,这步没有需要学习的参数。
对于图像,对应内参、外参;取图像中任意像素,其像素坐标为。
定义一个离散的深度集合,为最小深度, 为深度步长,为深度离散数量。在论文中,深度范围为4m到45m,步长为1m,共41个档。
像素点关联 个3D点 。
遍历像素点,得到该相机图像的3D点云。点云的规模为,形状是视锥,也就是相机可观测的3D空间。
这部分没有可学习参数,仅通过设计规则,即相机内外参和离散深度生成。
Step2
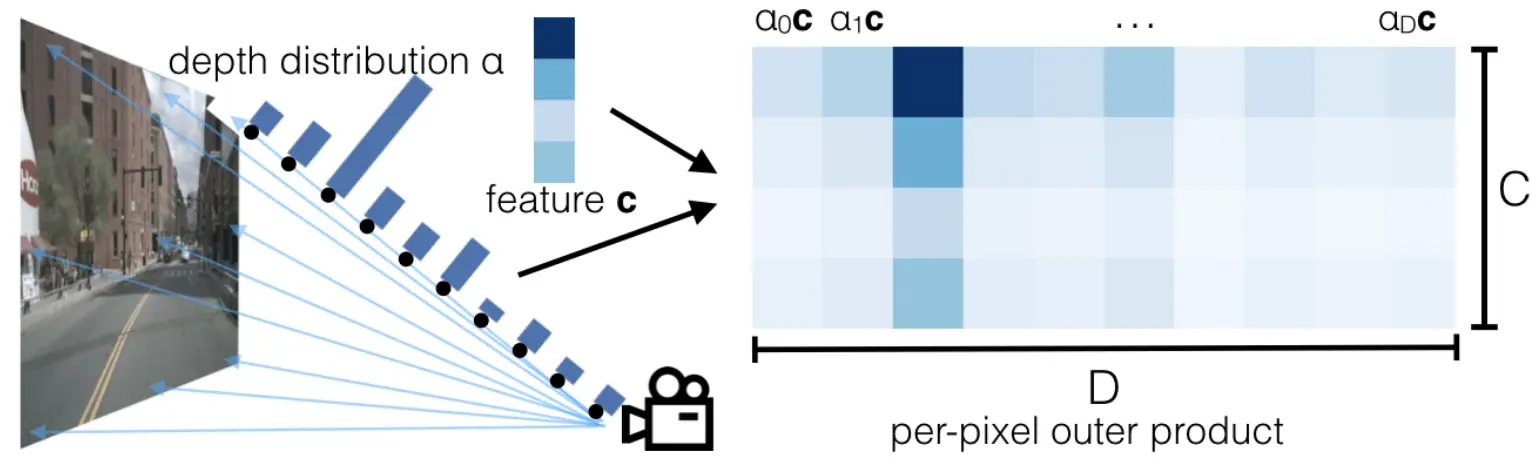
为3D点云赋予深度相关特征,这步Learnable。
对像素点,模型使用双分支预测,得到俩输出:
上下文特征向量,其中 为特征通道数,表征该像素的2D特征,比如深度,纹理。
深度概率分布,也就是对这个像素,在深度集合中每个深度的置信度,也可以说是权重。
最终像素点在深度 处的最终特征定义为。
如何理解这一步呢,假设深度分布置信度(权重) ,其中每个元素都是标量。还有一个 维的特征向量。相乘就是在加权,加权之前每个像素只有一个的 向量,加权后,每个深度都有了一个对应的向量。用给加权,那当 越大,该向量 也就越大,模型更会专注于 深度下的特征向量,因为它置信度高啊。
看下面右图中 深度更高,更多的信息就被编码在了 这个深度。
如果某个像素深度比较确定,那么会得到近似one-hot的深度分布,把所有特征都集中到这个真实深度点上,效果类似pseudolidar。
反之,这个像素深度比较模糊,那么网络会预测一个均匀的深度分布,把特征平摊到整个射线上,效果类似OFT (Orthographic feature transform)。OFT不做深度选择,直接把特征扩散到整个射线上。这样的好处是,当深度明确时,特征集中到准确的深度上,提升3D定位精度;若深度不确定,均匀分布,避免错误深度带来估计的偏差。
Lift阶段最终输出的3D特征点云维度为。
Splat
所有相机经过Lift步骤后得到对应的Frustum3D特征点云,将这些点云融合并栅格化为统一的BEV特征张量。
弄成BEV张量有啥好处呢,BEV张量是2D的,可以直接输入2D的CNN进行下游任务。
LLS借鉴了PointPillars (PP) 的方法,使用Pillar Pooling方法,实现了多相机的3D特征到BEV的2D特征的转换。
Step1
在BEV 3D坐标系中,定义柱体也就是Pillar——也就是BEV平面上每个栅格对应一个Pillar,每个Pillar是高度无限的Voxel。
所有相机组成的3D特征点云中的每个点,分配到其在BEV平面上的最近的Pillar,根据 坐标分配。坐标是世界坐标系,通过41个深度分布,结合内外参进行坐标系逆运算得来。
Step2
然后对每个Pillar内所有3D特征点执行按通道求和,最终将所有Pillar的Pooling特征按BEV排列,生成BEV 2D的特征张量:,其中 为特征通道, 为BEV的栅格的空间维度,有量纲,单位为米,注意和前面特征点云维度区分。文中设置为50米,grid分辨率=0.5米。
为了避免逐个求和(太慢),作者使用了前缀和方法。注意Pytorch中数组索引是左闭右开。
具体做法是把所有 3D 点排成一个连续的长列表,不补零、不浪费空间;再用两个极小的数组,记住每个 Pillar 的点,在长列表里从第几个开始、到第几个结束,这两个数组就是起始(start)、结束(end)索引。
假设Pillar的分配结果为:
P0:点0,1
P1:点2,3,4
P2:点5,6
那么可以得到如下连续的长列表:
长列表 = [点0, 点1, 点2, 点3, 点4, 点5, 点6]
索引: 0 1 2 3 4 5 6然后生成索引数组,意思就是每个Pillar在长列表中的哪里开始哪里结束
start = [0, 2, 5]
end = [2, 5, 7]我们假设长列表里存的是数字(向量同理):
长列表 points = [1, 2, 3, 4, 5, 6, 7]
索引: 0 1 2 3 4 5 6计算前缀和数组:
S[0] = 1
S[1] = 1+2 = 3
S[2] = 1+2+3 = 6
S[3] = 1+2+3+4 = 10
S[4] = 1+2+3+4+5 = 15
S[5] = 1+2+3+4+5+6 = 21
S[6] = 1+2+3+4+5+6+7 = 28
最终前缀和数组和索引数组
S = [0, 1, 3, 6, 10, 15, 21, 28]
Pillar 0: start=0, end=2 → 点0点1
Pillar 1: start=2, end=5 → 点2点3点4
Pillar 2: start=5, end=7 → 点5点6直接计算:
Pillar 0 的和(1+2)
S[end] - S[start] = S[2] - S[0] = 3 - 0 = 3
Pillar 1 的和(3+4+5)
S[5] - S[2] = 15 - 3 = 12
Pillar 2 的和(6+7)
S[7] - S[5] = 28 - 21 = 13
Shoot
Shoot阶段的输入是BEV特征图和轨迹模板,输出是最优轨迹和Cost Map。
先对驾驶轨迹进行K-Means聚类,得到1000个轨迹模板。
然后使用BEV特征图作为输入,输出得到Cost Map。每个网格输出,索引为的Grid代价越大,那么置信度越小,让模型各个倾向于走代价小的轨迹。
Model
超参
模型输入
最终输入图像的尺寸resize为[128, 352]
Lift
Frustum生成,下采样16倍
ds: [D, fH, fW] → [41, 8, 22]
xs: [D, fH, fW] → [41, 8, 22]
ys: [D, fH, fW] → [41, 8, 22]
frustum = stack(xs, ys, ds, dim=-1) → [D, fH, fW, 3] = [41, 8, 22, 3]
# xs, ys, ds 可以理解为(x_pixel, y_pixel, depth)反投影到World Frame,获取点云
geom = rots @ inv(intrins) @ points + trans → [B, N, D, fH, fW, 3] = [B, N, 41, 8, 22, 3]相机特征提取
# 合并BN
[B, N, 3, H, W] → [B*N, 3, 128, 352]EfficientNet-B0:
input: [B*N, 3, 128, 352]
reduction_5 [B*N, 320, 4, 11] # 最深层
reduction_4 [B*N, 112, 8, 22] # 倒数第二层
reduction_5 upsample x 2 → [B*N, 320, 8, 22]
res = concat(reduction_4, reduction_5) → [B*N, 432, 8, 22]
Conv2d(res) → [B*N, 512, 8, 22]depthnet
depthnet: [B*N, 512, 8, 22] → [B*N, 105, 8, 22]外积
depth = softmax(x[:, :D]) → [24, 41, 8, 22] # 深度概率分布
feat = x[:, D:D+C] → [24, 64, 8, 22] # 图像语义特征
# outer product: 每个像素 × D个深度
depth.unsqueeze(1) * feat.unsqueeze(2)
= [B*N, 1, 41, 8, 22] * [B*N, 64, 1, 8, 22]
→ [B*N, 64, 41, 8, 22]
# 恢复B, N
= [B, N, 41, 8, 22, 64]Splat
Voxel Pooling
input = [B, N, 41, 8, 22, 64]
total= B*N*D*H*W = 4×6×41×8×22 = 173184
input.reshape(total, 64) → [173184, 64]
geom.view(total, 3) → [173184, 3] # ego(x,y,z)
geom → [173184, 4] # ego(x,y,z,batch_id)
# 过滤点云(越界/重复删除)
total → kept[]
input → [kept, 64]
geom → [kept, 4]
# 压缩高度,投影到BEV
[B, 64, 200, 200]BEV Encoder
B = 4
input: [4, 64, 200, 200]
conv1 (7×7, s=2): [4, 64, 100, 100]
bn1 + relu: [4, 64, 100, 100]
layer1 (x1): [4, 64, 100, 100] ← skip connection
layer2: [4, 128, 50, 50]
layer3: [4, 256, 25, 25]
Up1(64+256→256, scale=4):
layer3 upsample ×4: [4, 256, 100, 100]
cat(x1): [4, 320, 100, 100] # 256+64=320
conv → out: [4, 256, 100, 100]
Up2:
upsample ×2: [4, 256, 200, 200]
conv(256→128): [4, 128, 200, 200]
conv(128→outC=1): [4, 1, 200, 200] # 最终输出
评论