

Deep3DBox是一篇比较早的使用单目相机进行3D目标检测和姿态估计的方法。
Deep3DBox先用CNN回归目标的方向和尺寸,因为这两类属性稳定性比较高。然后结合2D BBOX的几何约束求解平移量,以生成完整的3D BBOX。
有些传统的方法基于PnP,通过2D-3D关键点对应关系求解姿态,需要人工标注关键点和3D模型。
论文中提到了一个数据集:PASCAL 3D+。这个数据集包含了PASCAL VOC中的12个类别,主要用于估计相机的拍摄视角和距离,而非用于3D目标检测。CNN出现以后,很多方法采用CNN进行目标检测,然后将检测到的2D BBOX区域作为输入,传递给另一个CNN,利用PASCAL 3D+来训练并估计物体姿态。总的来说,这些方法都需要带有标注的关键点,和Deep3DBox并没有太大关系。
Deep3DBox放弃直接回归3D姿态,而是使用CNN回归关键参数,再用几何约束求解剩余的参数。
3D BBOX估计的几何基础
论文先使用2D检测的结果得到2D BBOX,且2D BBOX必须是3D BBOX经相机透视投影后的约束框,也就是3D BBOX的投影应该恰好贴合2D BBOX的4条边。
论文中3D BBOX定义如下,是后续求解的对象(9DoF):
平移:中心点,分别为相机坐标系下的X/Y/Z轴坐标
尺寸:
朝向:,分别为方位角,俯仰角,滚转角
相机将目标坐标系3D点,投影到像素坐标系2D点的公式:
其中各符号含义:
:目标坐标系下的3D齐次坐标,原点在3D BBOX中心
:位姿矩阵,实现目标坐标系到相机坐标系的刚体变换
:相机内参矩阵
:像素坐标系下的2D齐次像素坐标
文中的目标坐标系是为每个3D BBOX单独建立的局部坐标系。检测出N个目标,就应该有N个目标坐标系。
3D BBOX的8个顶点坐标,可以由D 直接推导得出:
贴合约束的要求是:3D BBOX的投影应该紧密的贴在2D BBOX上,2D框的4条边,每条至少被一个3D框的顶点触碰。
举个例子,2D框左边界x_min,3D框顶点应该恰好触碰x_min ,则满足:
其中表示:取透视投影结果的x轴像素坐标。2D框其他3个顶点也对应一个几何约束方程,这样就得到了4个约束条件。3D框是9DoF,4个约束不够。
要注意,4个约束方程的来源是2D BBOX的4个边界,而非3D BBOX的8个顶点。约束实际来自于2D BBOX。
论文在这9个DoF中,选择使用CNN来回归尺寸和朝向,使用集合约束来求解平移。
原因有二:
类内方差小:因为在交通场景下,同一类别的目标尺寸差异很小。拿人举例,姚明和我的身高差距很大,但也只是厘米级别的。除此之外,目标的尺寸不会随朝向产生变化。这说明这二者是比较稳定的属性,容易通过CNN从视觉特征中回归。
尺寸与目标外观存在强关联:不同类型的目标的视觉特征有显著差异,显著的视觉差异大多来自于目标的尺寸。但是平移
T没有这么强的关联。
回到2D框和3D框之间的约束问题。我们需要确定:2D框的4条边和3D框的8个顶点的存在多少对应关系?2D每1个边可以可能对应3D的8个点,枚举下来,就是84=4096种可能性,需要求解4096次公式2。下面是为了简化这个问题做的处理:
目标直立的假设:2D框的上下边,应该分别对应3D框的上下顶点,左右暂时没有这个假设。基于此假设,组合总数变成 4x4x8x8=1024。
2D上边:对应3D框顶部 4 个顶点
2D下边:对应3D框底部 4 个顶点
2D左右边:仍然是分别对应 8 个顶点
投影面分离:组合总数变成 4x4x4x4=256。
2D左右边:2D 框的 和 只能由 3D 框的 4 个垂直线决定。在局部坐标系中,这对应于坐标。由于 坐标上下变化并不影响投影的左右极值点,因此左右边各有 4 种配置。
2D上下边:同理, 和 对应于 3D 框的水平边缘,各有 4 种配置。
KITTI特殊先验:相机Pitch&Roll=0,目标无俯仰和翻滚,而且这时候模型推理得到了Yaw角。相机坐标系和地面是严格平行的。这导致3D框的“上”就是”上“,"下"就是"下"。组合总数变成4x4x2x2=64种。
2D上边: 只能来自于 3D 框顶面(局部坐标),排除底部平面()。对于上下边配置,代表高度的 符号被唯一固定为负( )。变量只剩下前/后()。所以,顶边只剩下 2 种有效配置。
2D下边:同理,2D 框的底边 只能来自于 3D 框底部平面(即局部坐标)。 的符号被唯一固定为正,变量同样只剩前/后( )。底边也只剩下 2 种有效配置。

朝向的回归
这一部分解决俩问题,一是回归什么朝向,局部还是全局,二是损失函数设计。
朝向问题
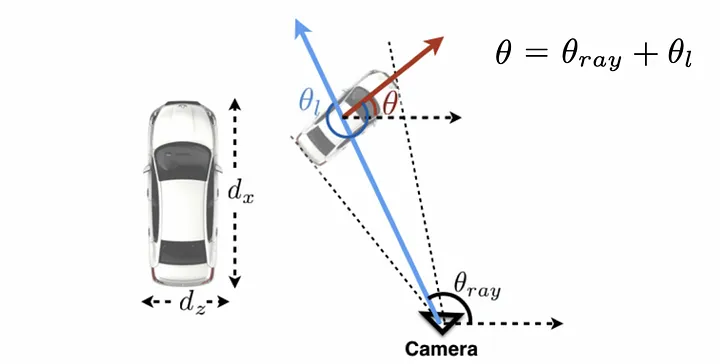
论文用MS-CNN输出物体的2D BBOX,仅使用BBOX内的像素和相机内参。所以CNN仅能看到框内的像素,无法获取BBOX在整张图像中的位置信息。而相机的射线方向(小孔成像那个物体到CMOS的射线)由像素位置决定,所以没办法直接估计物体的全局朝向。
顺手说一下全局和局部朝向:
全局朝向:物体在相机坐标系中的绝对朝向,是最终需要的3D参数
局部朝向:物体相对于BBOX中心的相机射线的相对朝向,可以由内参直接计算。网络训练的输出就是局部朝向。
从下图可以看出,尽管目标一直朝前开,绝对朝向没变,但是射线方向和在BBOX内的相对朝向是有变化的。

损失函数设计
然后对于多模态的回归问题,L2损失不合适,因为L2损失会促使网络最小化所有模态的平均损失。
那用啥损失函数呢?作者提出了个MultiBin架构,核心是先分类,再回归。
分类是将局部朝向划分为多个bin,bin之间存在重叠,每个bin有一个中心角度。
每个bin输出:
置信度:局部朝向角落在第 i 个bin的概率
:第 i 个bin的中心角度到真实朝向角的残差的余弦
最终损失函数为:
置信度损失:Softmax交叉熵损失,本质是分类任务,判断朝向属于哪个bin。
定位损失:余弦的距离损失,让估计角度接近真实角度。
权重,用于平衡两个损失的贡献度。
网络设计
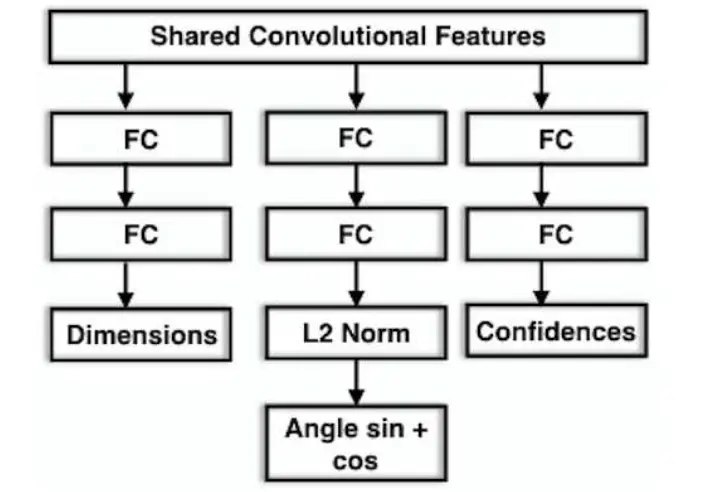
网络设计的比较简单,使用无FC的预训练的VGG,仅保留Conv和Pooling。
VGG网络共享Conv特征,共享的目的是确保朝向和尺寸估计使用一套特征,避免特征冗余,同时模型还能学习到朝向和尺寸的关联特征。
有3个分支:
一组FC(dim=256)接置信度分支,输出 n 个bin的置信度。
一组FC接L2归一化后,给出每个bin的三角函数值。
最后一组FC用来回归目标尺寸。
尺寸的回归
尺寸回归直接使用L2损失计算,原因在开头说过了。
不过论文没有直接回归真实尺寸,而是回归了真实尺寸D相对于数据集中同类别目标平均尺寸 的残差。
优势在于,数据集中同类别平均尺寸 是固定值,是统计出来的,残差 的数值远小于 本身。小数值的残差更容易收敛。
其中:
为尺寸dim=3。
为真实尺寸GT。
是类别平均尺寸。
是估计尺寸和目标平均尺寸的残差,也就是 , 是模型估计出的尺寸。
最终模型总损失为
参考文章
[1] [1612.00496] 3D Bounding Box Estimation Using Deep Learning and Geometry
[2] PASCAL 3D+ 数据集概述 - 知乎
评论