

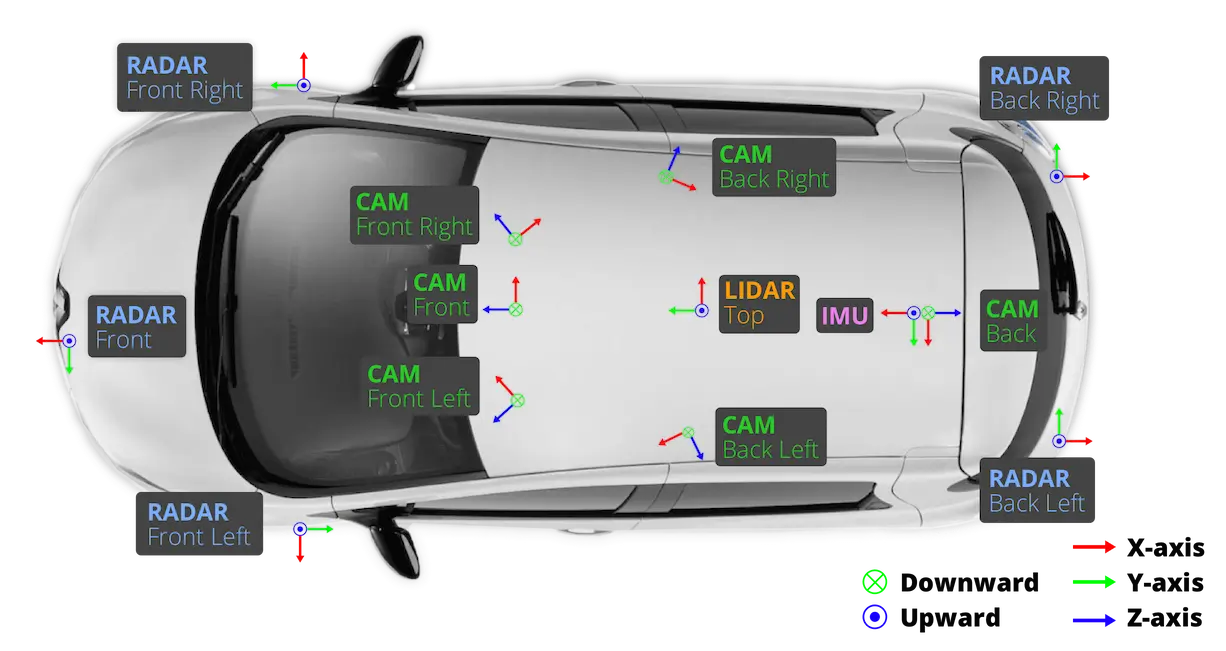
nuScenes数据集包含6个Camera,1个LiDAR,5个Radar,1个GPS以及IMU。
数据量比KITTI大得多,所以目前Occ Networks更多使用nuScenes数据集。
数据集分成两大块:Full和Mini。
Full Dataset包含140万Camera图像,39万LiDAR数据,140万Radar数据,以及4万个Key frame中的140万个BBox
Mini数据集一共10个场景。
数据集结构
下载并解压mini数据集后的文件夹结构如下:
.
├── LICENSE
├── maps
├── samples
├── sweeps
└── v1.0-minimaps:存放地图文件,以png格式存储。
.
├── 36092f0b03a857c6a3403e25b4b7aab3.png
├── 37819e65e09e5547b8a3ceaefba56bb2.png
├── 53992ee3023e5494b90c316c183be829.png
└── 93406b464a165eaba6d9de76ca09f5da.pngsamples:Key frame的各种传感器数据,文件夹中的frame数量应该是相同的,比如mini数据集中这些文件夹的文件数量都是404。
.
├── CAM_BACK
├── CAM_BACK_LEFT
├── CAM_BACK_RIGHT
├── CAM_FRONT
├── CAM_FRONT_LEFT
├── CAM_FRONT_RIGHT
├── LIDAR_TOP
├── RADAR_BACK_LEFT
├── RADAR_BACK_RIGHT
├── RADAR_FRONT
├── RADAR_FRONT_LEFT
└── RADAR_FRONT_RIGHTsweeps:结构和samples类似,是Intermediate frames中间帧的传感器数据。sweeps里的数据应该没有被使用。
.
├── CAM_BACK
├── CAM_BACK_LEFT
├── CAM_BACK_RIGHT
├── CAM_FRONT
├── CAM_FRONT_LEFT
├── CAM_FRONT_RIGHT
├── LIDAR_TOP
├── RADAR_BACK_LEFT
├── RADAR_BACK_RIGHT
├── RADAR_FRONT
├── RADAR_FRONT_LEFT
└── RADAR_FRONT_RIGHTv1.0-mini:各种json文件
.
├── attribute.json
├── calibrated_sensor.json
├── category.json
├── ego_pose.json
├── instance.json
├── lidarseg.json
├── log.json
├── map.json
├── sample_annotation.json
├── sample_data.json
├── sample.json
├── scene.json
├── sensor.json
└── visibility.jsonjson文件解析
attribute.json:实例的属性。
attribute {
"token": <str> -- Unique record identifier.
"name": <str> -- Attribute name.
"description": <str> -- Attribute description.
}这里都是json文件,用[]包裹的数组,里面包含的对象用{}包裹。
以attribute为例,单个对象的结构如上所述,每个对象有3个字段,token,name和description。
其中token是不会重复的唯一标识符,可以理解为字典的key,每个对象都可以通过token去获取,有些对象还包含了prev/next对象的token,可以快速按顺序查找。有人可能在想,就这点东西有必要用token吗?看到后面你就知道了。
calibrated_sensor.json:传感器标定数据。
calibrated_sensor {
"token": <str> -- Unique record identifier.
"sensor_token": <str> -- Foreign key pointing to the sensor type.
"translation": <float> [3] -- Coordinate system origin in meters: x, y, z.
"rotation": <float> [4] -- Coordinate system orientation as quaternion: w, x, y, z.
"camera_intrinsic": <float> [3, 3] -- Intrinsic camera calibration. Empty for sensors that are not cameras.
}这里就加入了一个新token字段sensor_token ,用来快速查找这是哪个传感器。
Foreign key 说明该字段会出现在其他json文件的字段中(存在映射关系),否则只在本json文件中出现。
category.json:类别划分的描述。
category {
"token": <str> -- Unique record identifier.
"name": <str> -- Category name. Subcategories indicated by period.
"description": <str> -- Category description.
"index": <int> -- The index of the label used for efficiency reasons in the .bin label files of nuScenes-lidarseg. This field did not exist previously.
}在name字段中,你会看到多个类别,顺序是大类->子类。比如"human.pedestrian.child",其中human是大类,pedestrain是human的子类,child是pedestrain的子类。
在lidarseg数据集中(一会说这是什么),还有一个index字段,主要是为了在.bin文件中更有效率的索引物体类别。而且其他数据集(full,mini)中的 category.json 是lidarseg数据集 category 内容的子集。
ego_pose.json:给定timestamp下的自车位姿。
ego_pose {
"token": <str> -- Unique record identifier.
"translation": <float> [3] -- Coordinate system origin in meters: x, y, z. Note that z is always 0.
"rotation": <float> [4] -- Coordinate system orientation as quaternion: w, x, y, z.
"timestamp": <int> -- Unix time stamp.
}这个文件就能明显看出token的便利性了,根据时间戳分出的大量对象,要是没token,想要快速定位数据还是比较麻烦。
instance.json:一个被持续跟踪的物体实例,跨多个Frame的目标轨迹索引。
instance {
"token": <str> -- Unique record identifier.
"category_token": <str> -- Foreign key pointing to the object category.
"nbr_annotations": <int> -- Number of annotations of this instance.
"first_annotation_token": <str> -- Foreign key. Points to the first annotation of this instance.
"last_annotation_token": <str> -- Foreign key. Points to the last annotation of this instance.
}其中的category_token字段可以和category.json文件中的类别建立映射。你可以随便找一个category_token ,在category.json文件中肯定能搜到。
nbr_annotations字段代表该实例在数据集中出现了多少条 sample_annotation,也就是被标注了多少帧。这个在 sample_annotation.json 中还会有解释
因此,first_annotation_token和last_annotation_token 分别代表该instance被标注的首帧和尾帧。
lidarseg.json:在lidarseg和sample_datas建立映射。
lidarseg {
"token": <str> -- Unique record identifier.
"filename": <str> -- The name of the .bin files containing the nuScenes-lidarseg labels. These are numpy arrays of uint8 stored in binary format using numpy.
"sample_data_token": <str> -- Foreign key. Sample_data corresponding to the annotated lidar pointcloud with is_key_frame=True.
}full和mini数据集中没有这个,得去专门下对应的lidarseg,才有这个标注文件。lidarseg中也会有一个和full/mini数据集同名的 category.json 文件。根据前面说的子集关系,lidarseg的 category.json 直接覆盖原有的 category.json 即可。
filename :指向文件夹中一个前缀包含了token的.bin点云文件。
sample_data_token :和token好像完全一样?能在 sample_annotation.json 中找到对应的。
log.json:数据的采集日志,说明啥车,啥时候,在哪采集的,训练和复现过程应该用不上。
map.json:把某次采集映射到对应地图文件,用于可行驶区域先验。
map {
"token": <str> -- Unique record identifier.
"log_tokens": <str> [n] -- Foreign keys.
"category": <str> -- Map category, currently only semantic_prior for drivable surface and sidewalk.
"filename": <str> -- Relative path to the file with the map mask.
}category字段内容都是semantic_prior ;filename 对应maps文件夹中的.png文件;log_tokens 列表中的每个 token 都指向 log.json 里的一条 log 记录。
sample.json:按照2Hz频率采集的Key frame。这里的数据可以认为和LiDAR是时间同步的。对应samples文件夹,对于mini数据集(404个Key frame),这个文件中应该有404个对象(是Frame,这里的对象不是目标)。
sample {
"token": <str> -- Unique record identifier.
"timestamp": <int> -- Unix time stamp.
"scene_token": <str> -- Foreign key pointing to the scene.
"next": <str> -- Foreign key. Sample that follows this in time. Empty if end of scene.
"prev": <str> -- Foreign key. Sample that precedes this in time. Empty if start of scene.
}每个token对应一个Frame,scene_token 指向 scene.json 中的一个对象,next和prev 分别代表当前上一帧和下一帧的token,如果是首/尾帧,那么为空。
Mini数据集共有10个scene,sample就被划分成10个部分,10个部分内部的token是首尾相连的,有10个prev和next为空。
sample_annotation.json:重头戏,目标标注。
sample_annotation {
"token": <str> -- Unique record identifier.
"sample_token": <str> -- Foreign key. NOTE: this points to a sample NOT a sample_data since annotations are done on the sample level taking all relevant sample_data into account.
"instance_token": <str> -- Foreign key. Which object instance is this annotating. An instance can have multiple annotations over time.
"attribute_tokens": <str> [n] -- Foreign keys. List of attributes for this annotation. Attributes can change over time, so they belong here, not in the instance table.
"visibility_token": <str> -- Foreign key. Visibility may also change over time. If no visibility is annotated, the token is an empty string.
"translation": <float> [3] -- Bounding box location in meters as center_x, center_y, center_z.
"size": <float> [3] -- Bounding box size in meters as width, length, height.
"rotation": <float> [4] -- Bounding box orientation as quaternion: w, x, y, z.
"num_lidar_pts": <int> -- Number of lidar points in this box. Points are counted during the lidar sweep identified with this sample.
"num_radar_pts": <int> -- Number of radar points in this box. Points are counted during the radar sweep identified with this sample. This number is summed across all radar sensors without any invalid point filtering.
"next": <str> -- Foreign key. Sample annotation from the same object instance that follows this in time. Empty if this is the last annotation for this object.
"prev": <str> -- Foreign key. Sample annotation from the same object instance that precedes this in time. Empty if this is the first annotation for this object.
}sample_token 指向 sample.json 中的的某个token ,也就是那个Frame。注意,此处和 sample_data.json 没有对应关系。
instance_token 指向 instance.json 中的某个token ,也就是属于哪条轨迹。
attribute_tokens 指向 attribute.json 中的某个token ,描述该目标的属性。
visibility_token 指向 visibility.json,描述目标整体可见度等级。
translation 描述目标位置,size 描述物体尺寸,rotation 描述物体朝向(四元数,数据集中描述朝向都用四元数)。
num_lidar_pts 和num_radar_pts描述落在BBOX内的LiDAR/Radar点的数量。
next和prev 记录同一个instance前/后帧的token。
sample_data.json:描述某个sample下某个传感器的原始数据
sample_data {
"token": <str> -- Unique record identifier.
"sample_token": <str> -- Foreign key. Sample to which this sample_data is associated.
"ego_pose_token": <str> -- Foreign key.
"calibrated_sensor_token": <str> -- Foreign key.
"filename": <str> -- Relative path to data-blob on disk.
"fileformat": <str> -- Data file format.
"width": <int> -- If the sample data is an image, this is the image width in pixels.
"height": <int> -- If the sample data is an image, this is the image height in pixels.
"timestamp": <int> -- Unix time stamp.
"is_key_frame": <bool> -- True if sample_data is part of key_frame, else False.
"next": <str> -- Foreign key. Sample data from the same sensor that follows this in time. Empty if end of scene.
"prev": <str> -- Foreign key. Sample data from the same sensor that precedes this in time. Empty if start of scene.
}sample_token 指向 sample.json 中的某个 sample。
ego_pose_token 指向 ego_pose.json 中的某时刻位姿。
calibrated_sensor_token 指向 标注文件中的某个标注。
fileformat:文件格式,比如 pcd、jpg、png。
is_key_frame:是否是关键帧。
height / width:图像尺寸;对雷达/激光通常是 0。
filename:相对路径,真正的数据文件就在这个路径下。
prev:同一传感器时间序列中的前一帧 sample_data。
next:同一传感器时间序列中的后一帧 sample_data。
scene.json:每个时长20s(2Hz->40Frame)的场景描述。
sensor.json:记录每个Sensor(Camera,LiDAR,Radar)的描述。
visibility.json:描述能见度等级。因为只有4个level,token直接0-4整型编码。
json文件对完了。其实在nuScenes官网也能看到,他们还有nuPlan,nuImages等。我看了nuImages数据集,是2D-Det/Seg数据集,算得上是nuScenes的子集。所以能看出来Scenes数据集关注点在于宏观场景。
下面图像也描述了各个文件内的数据流向。学到这一步我还没用上nuscenes-dev-toolkit。一个比较笨的方法是复制某个字段的token,到其他文件夹去搜,如果能搜到证明二者有映射关系。
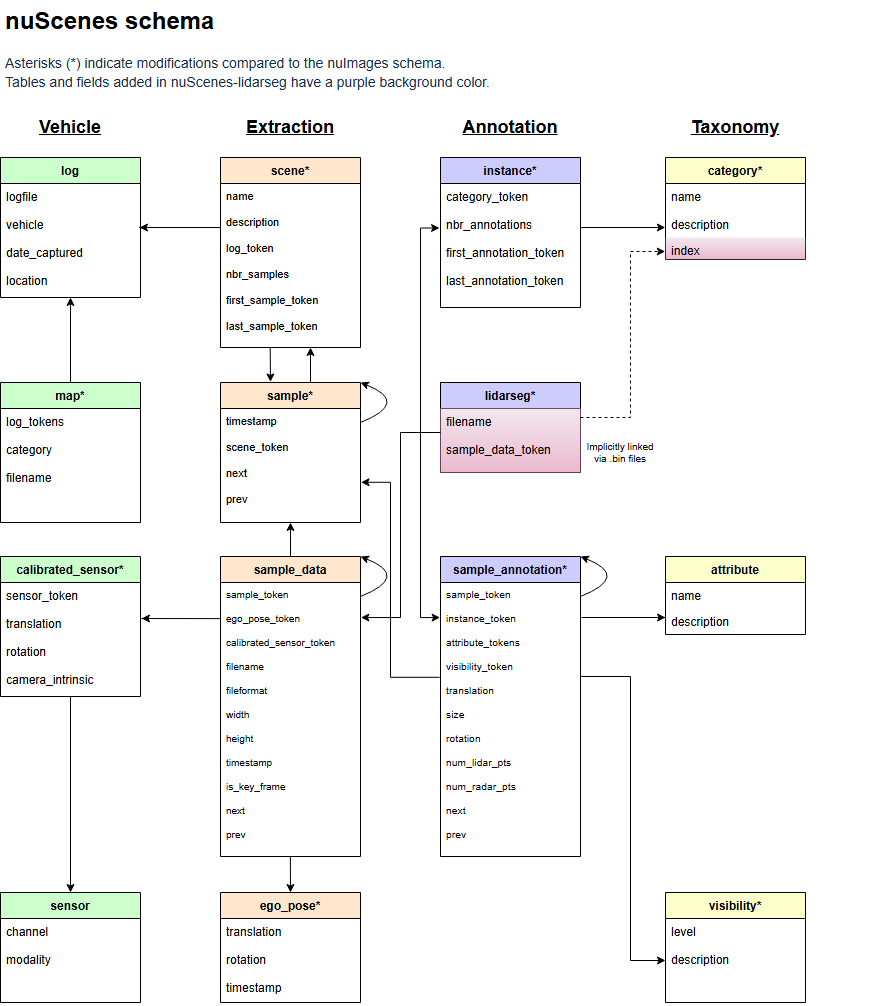
json文件层级
根据上面解析的内容,能看出不同json文件面向不同层级的数据。
上图做了一定程度的层级划分。
我根据自己的理解重新分了层级,方便从宏观层面理解数据集,如有理解错误请斧正:
Highest-Level:scene.json可以认为是最高层级,一切数据都基于场景划分。
Meta-Level:log.json,map.json,这部分内容过于宏观,上图中能看出来,在训练阶段这些都处于边角料地位(和其他module交叉关联较少)。
Dict-Level: attribute.json,category.json,calibrated_sensor.json,sensor.json,visibility.json,仅做字典查询,也是边角料。
calibrated_sensor.json,虽然内容很多,但是我认为仍然是在查表。
Frame-Level:
sample.json,非常重要的一个层级。Mini数据集json中有404个对象(重申此处对象是json文件中的概念),也就对应了404个Key frame。
sample_data.json,所有传感器数据,通过
is_key_frame字段判断是否为Key frame,filename字段也能看出位于 samples/sweeps 两个文件夹。即便包含了一些中间帧,所以我认为仍然属于Frame-Level。不过很明显,sample_data 更细致,或许叫SubFrame-Level更合理,但是不做更多细分。lidarseg.json,每个对象对应一个 sample_data.json 中的对象,所以应该被划分为同一个层级。
ego_pose.json,看起来是边角料,但是描述ego在每个TimeStamp下的全局位姿,我认为基于时间戳的数据都可以认为是Frame-Level。
Object-Level:
sample_annotation.json,生命周期在Frame内部,每个对象对应一个sample(Frame)中的Object标注。
instance.json,生命周期跨Frame,annotation中的每个对象是一个Object,归属于一个Instance实例。通俗点讲,Instance是Object他爹,但是仍然可以认为描述的是同一个层级的东西。
参考文章
[2] nuScenes
评论