

标题中的Affordance一词,本意是”预设用途,功能特性“,最初在知觉心理学和设计学领域出现。
后来在人机交互领域,Affordance的含义变成了:一个产品让用户自然领悟到用法的能力。
在机器人领域(自动驾驶和机器人的感知不分家),被引申为可以执行的潜在动作,即在特定情况下哪些动作是可执行的。具象含义就是:路面-可以走;行人-需避让;绿灯-可通行;红灯-不可通行。
回到标题,就是在自动驾驶的直接感知中,学习场景的Affordance,以Affordance作为直接感知的核心表示。
ADAS视觉感知范式
作者认为,基于视觉的ADAS有两种常见范式:
中介感知:先解析整个场景,再做出驾驶决策。图像->场景解析->驾驶行为。
行为反射:通过回归器,将图像直接映射为驾驶动作,无中间推理,纯黑盒。图像->驾驶行为。
论文提出了第三种范式:
即通过图像直接估计Affordance,利用估计得到的Affordance做决策,即图像->Affordance->驾驶行为。
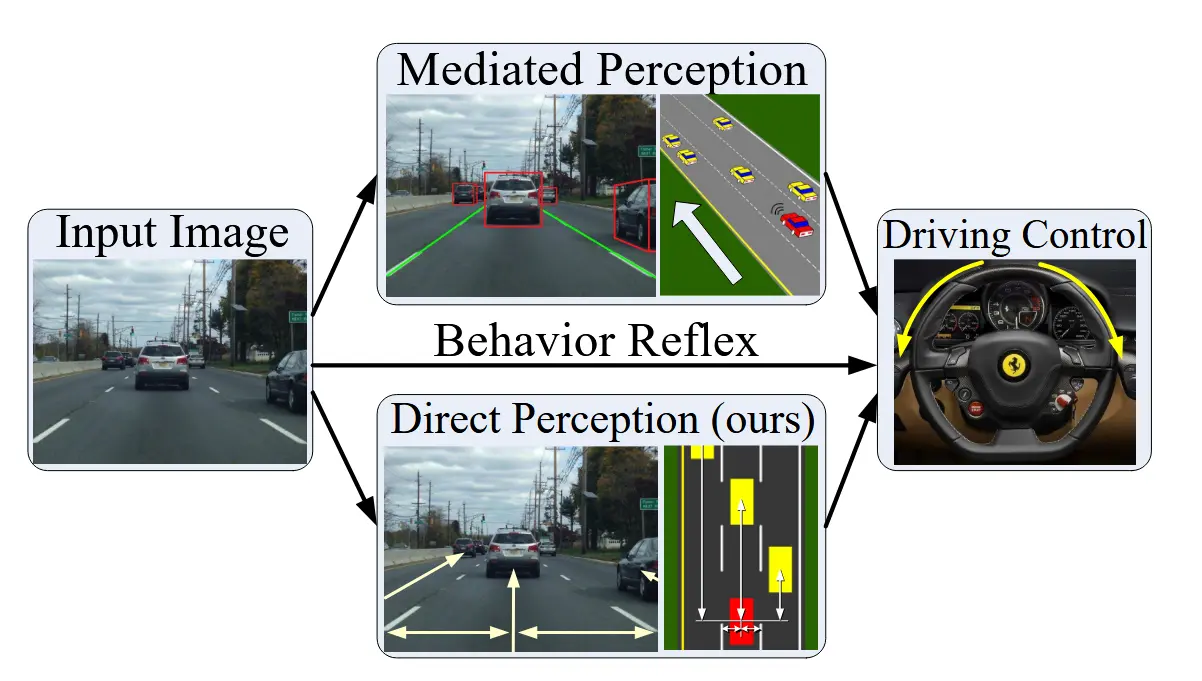
中介感知
包含多个子系统,比如车辆/行人检测,信号灯识别,车道线识别等。检测结果会被整合为ego周围环境的统一表征,不过这些表征只有很少一部分会被直接用于决策,也就是说,很多检测结果是冗余的。比如估计目标距离,要先检测它的2D BBOX,再估计距离,那直接估计深度不得了?
行为反射
早在40年前就有人利用神经网络构建从图像到方向盘转向角的直接映射(好早)。作者认为在复杂场景下这种方法存在致命缺陷:
同一个输入图像,不同的人类驾驶员会有不同决策。比如直线行驶,前方有龟速车,你是一起当龟速车,还是超车?也就是同输入的不同输出。
抽象层级过低。超车行为会被解读为“方向盘往左打->方向盘往右打”,并不知道超车这个意图。
整张图像太大,导致监督不到关键信息。
Image到Action的映射
Dataset使用游戏TORCS录制,这个游戏能收集驾驶过程中的指标。
模型基于当时SOTA的CNN框架,关注多车道高速驾驶场景,从ego视角出发(和人类一致)。
Image到Affordance
高速驾驶场景的车辆Action可以分为2类:
沿车道中心线(两条车道线正中间)行驶
变道/减速以避免撞前车
论文使用两个坐标系:
车道内坐标系
压线坐标系(压在车道线上时)
使用三种指标表征驾驶状态:
航向角
与附近车道线的距离
和前车的距离。
此外,使用13个Affordance指标,能覆盖车道和车辆感知的需求。除了航向角始终激活,其他指标可能不激活。比如在车道内坐标系行驶,那么压线坐标系的指标都不会被激活;而当车辆在最左/最右车道,那么左侧/右侧就没有车道了,对应指标也不会激活。
根据这些指标的激活情况,ego可以确定自己在哪条车道上。
下图和上表一一对应:
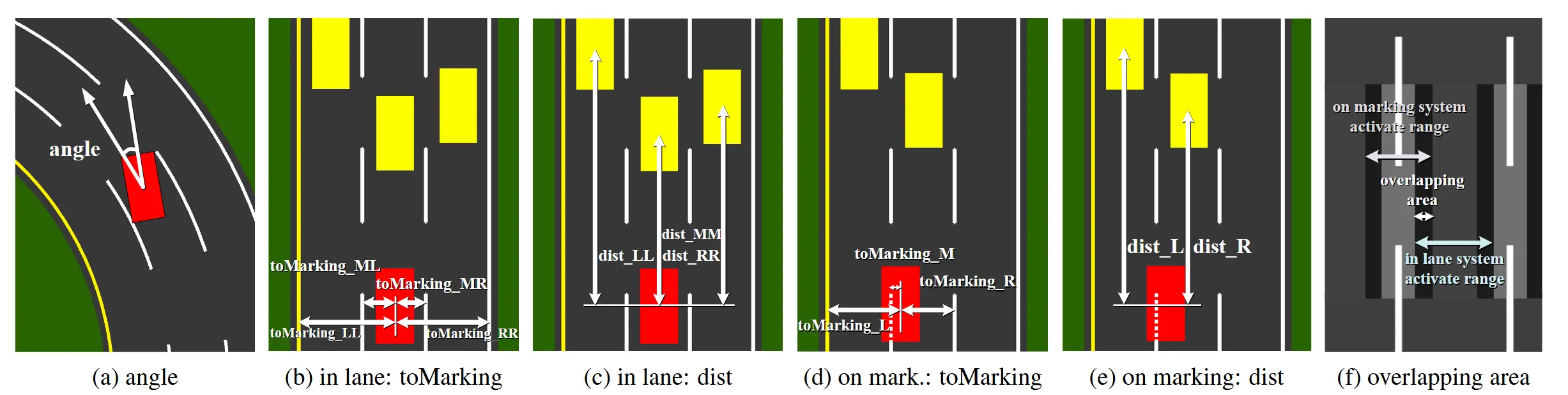
解读部分指标:
in lane: toMarking,车道内坐标系下,到当前车道的左/右车道线距离,和到相邻左右车道的左/右车道线距离,4个指标。
in lane: dist,车道内坐标系下,到左/当前/右车道前车的距离,3个指标。
on mark: toMarking,压线坐标系下,到左边/右边车道线的距离,和车辆中心到压到的车道线的距离,3个指标。
on mark: dist,压线坐标系下,和左/右两边前方车辆的距离,2个指标。
图片(f)主要是展示车道线坐标系和压线坐标系的激活范围和重叠区域。两个坐标系存在一个重叠区,实现坐标系之间的平滑过渡,避免突变。
Affordance到Action
这部分是从Affordance到驾驶的Action的映射,也就是Affordance如何影响控制逻辑。
下面两者无监督,不参与训练,都是公式化计算,属于手工规则,这可以提升模型的可解释性,否则就又是黑盒了。
Steering Control
目的是为了让车辆尽可能贴近车道线中心行驶,最小化位置偏差。
其中:
steerCmd:最终输出的方向盘转向角。C:随驾驶条件变化的调节系数,用于控制转向响应的强度。angle:车辆航向与道路切线的夹角(即之前提到的航向角指标)。
dist_center:车辆到当前车道中心线的距离。dist_center / road_width:将车辆偏离中心线的距离归一化到道路宽度的尺度上,作为位置修正项。
最终期望的结果是,当车辆变道时,能平滑的从一个车道中心,变到目标车道中心。
Speed Control
目的是根据场景动态调整车速,通过加/减速控制让实际车速保持期望车速。
其中:
v(t):t时刻的期望车速。v_max:最大允许车速。dist(t):t时刻到前车的距离,来自Affordance指标。c, d:待校准的系数,用于调节跟车的响应特性。
目的是实现平滑的速度控制,类似ACC。
网络和模型
网络基于Caffe框架(那时候的主流框架),使用标准的AlexNet,也就是5个Conv,接4个FC,FC输出维度分别为4096,4096,256,13。最终FC输出的13对应13个Affordance指标,属于回归任务,输出每个Affordance的预测值。论文对AlexNet做了修改,输入尺寸280x210,没有做数据增强,因为论文的方法对空间位置有要求,裁剪会破坏空间关系,镜像则违背行驶逻辑(左舵变右舵)。
Loss Function使用适合回归任务的Euclidian Loss,也就是L2 Loss。13个Affordance指标被归一化为[0.1, 0.9] 的范围。
TORCS评估
论文的TORCS虚拟场景Evaluation有两个部分,定性评估和与基线方法的定量对比。
定性评估
定性评估部分没有量化指标,主要是关注TORCS中的驾驶表现。结论为:
模型能在 TORCS 的多车道、有交通流场景中无碰撞平稳行驶;仅在部分变道场景中出现轻微的位置超调(即暂时偏离目标车道中心线),但控制器能快速修正位置,恢复到目标车道的期望行驶位置。证明Affordance到Action的映射逻辑能支撑决策。
对车道感知的精度极高,车辆感知30m内较好,30-60m有噪声,60m外基本不行。主要还是输入分辨率太低,提取不到远处车辆的特征。
模型对Affordance的误差具有鲁棒性,ego作为一个连续运动系统,控制器可以根据指标修正位置,哪怕Affordance出现零星错误估计,也不会导致驾驶失控。
基线定量对比
论文设计了3种基线方法,这三种Baseline基本覆盖了ADAS的主流思路,以MAE(平均绝对误差)为量化指标。直接说结论:
行为反射基线:作为纯E2E的范式,只能处理简单空赛道驾驶,有车流的时候完全失效。基本印证了本文开头作者对这一范式的评价。
间接感知基线:聚焦车道线感知的子任务,使用Caltech进行车道线检测,检测结果映射到Affordance指标。对任务做了大幅简化,无车流,同赛道,高分辨率图像,但是精度仍然明显低于论文中的方法。
手工特征的直接感知基线:和论文范式相同,主要验证CNN学习特征和手工视觉特征的差异。用自动驾驶场景经典手工特征GIST替代Conv提取的特征。结果是CNN特征远优于手工特征。
真实场景评估
智能手机视频
定性测试。测试数据来自手机拍摄的驾驶视频,无标注和人工干预。视频逐帧输入模型,模型输出13个Affordance指标,对指标结果进行可视化。结论是:
车道线:能正确识别车道线,正确定位ego在车道中的位置,变道时车道线过渡状态正确。
车辆感知:存在轻微噪声,距离感知精度略低于TORCS场景。对前车有无,远近有一定感知能力。
也就是TORCS中训练的模型无需微调,即可处理真实世界驾驶视频。
KITTI数据集
因为KITTI和TORCS场景差异巨大,KITTI并非专注于高速场景,而且车辆多,车道线不清晰。
论文重新定义了坐标系,定义自车为中心的2D地面坐标系,ego为中心,Y前,X右,类似BEV。聚焦前车距离估计,这个是ADAS感知的核心任务。这部分内容是为了引出下面与DPM的对比。
DPM基线
属于开篇提到的中介感知范式,DPM是当时SOTA的目标检测算法。
需要先输出检测框,再基于地平假设,将BBOX的下边缘中心点投影到平坦地面,得到车辆位置。
论文在KITTI数据集上训练模型,并与DPM做对比。
结论就是,媲美SOTA的DPM。
可视化分析
从神经元特征学习和空间注意力两个维度,证明模型不是随机拟合,而是主动学习到了自动驾驶任务的视觉特征,而且能关注图像中和驾驶有关的区域,如车道线和车辆。
下面左图展示了第一个FC的4096个神经元的激活模式,证明模型对航向角,车道线,车辆产生强烈响应。
第一个FC是Conv提取出来的基础视觉特征,像边缘,纹理,轮廓。特征的匹配度越高,FC中神经元的激活强度越大,比如对车道线激活强度高,对天空激活强度低。激活强度就是激活函数输出的数值。
具体如何操作,作者写的有些模糊,论文中21000张图像的数据集,会得到21000个激活强度数值,从高到低排列,取前100对应的图像。每个神经元最后应该都会得到自身激活强度最高的TOP100张图像,最后应该是4096*100张图像,每组的100张图像做像素级平均,得到4096个神经元分别的激活模式图像,然后作者挑了几张特征明显的放在Figure12中。
不过这个图,其实我并没能看出来什么东西……不如热力图明显。

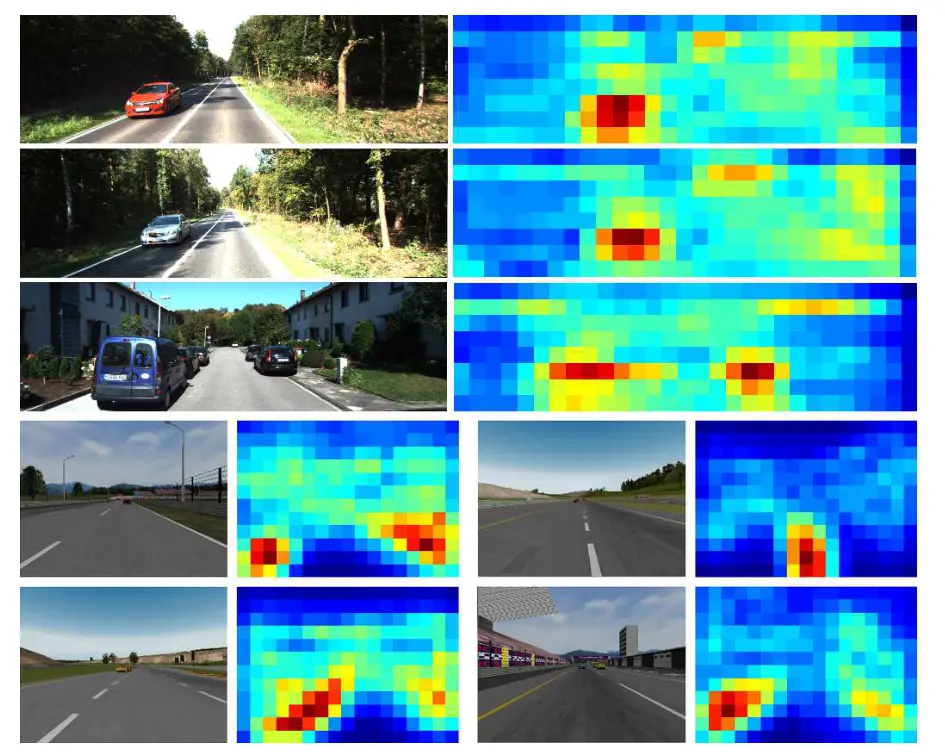
右图展示了第四个Conv的热力图。上方证明了证明了CNN对真实场景的车辆由很强的响应,也就是能关注这些区域。下图证明在TORCS场景下对车道线区域也有响应。
响应越高,视觉上就越突出(红)。
结论
相比纯E2E直接输出方向盘转角和油门开度,Affordance是有物理意义的中间表示,具备可解释性。
相比传统模块化感知,跳过冗余的目标建模,更贴合人类直观感知行为可行性的逻辑,效率更高。
本论文方法在虚拟和真实场景均取得不错的效果,而且在虚拟场景数据训练得到的模型,在真实场景下有良好泛化性。
参考文章
[1] 机器人学科中,什么是“Affordance”? - 知乎
[2] 功能可供性_百度百科
[3] DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving
评论