

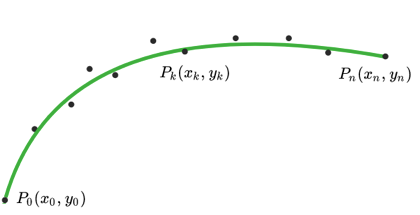
车道线的多项式曲线拟合
离散点平滑 基于优化的离散点平滑 模型检测到的车道线,最终的输出的是车道线的点坐标(x,y),这些点能够大概描述车道线在画面中的位置,但是如果想要拟合出车道线的高阶方程,可能还是不够平滑,一些离散点会影响拟合的效果。 优化变量:车道线点坐标(x_i,y_i) 优化目标有三个,分别是平滑度、长度和相对

点云数据处理踩坑进行时
读取 .bag文件报错 [FATAL] [1702017430.130428395]: Required op field missing 报错如下: $ rosbag play tsari.bag
[ INFO] [1702017430.118011688]: Opening tsari.bag



车道线检测功能综述【深度学习方法】
深度学习方法 车道线检测常用数据集见 FunnyWii's Zone 车道线检测功能综述【传统方法】 基于分割的方法 利用语义分割或实例分割方法来区分图像中的车道线与其他物体或背景。这种方法将车道线检测问题转化为一个像素级分类问题。这种方法会将场景图片的每一个车道线像素都进行分类,判断该像素是否属于

车道线检测功能综述【传统方法】
车道线检测技术 车道线检测技术是计算机视觉和自动驾驶领域中的关键技术之一,它能够帮助车辆在道路上准确识别和跟踪车道线,从而实现自动驾驶、车道保持等功能。 车道线检测方法总体上可以分为 传统方法 和 基于深度学习的方法。 车道线数据集 数据集 数量(张) 尺寸 场景 特点 TuSimple 72k 1

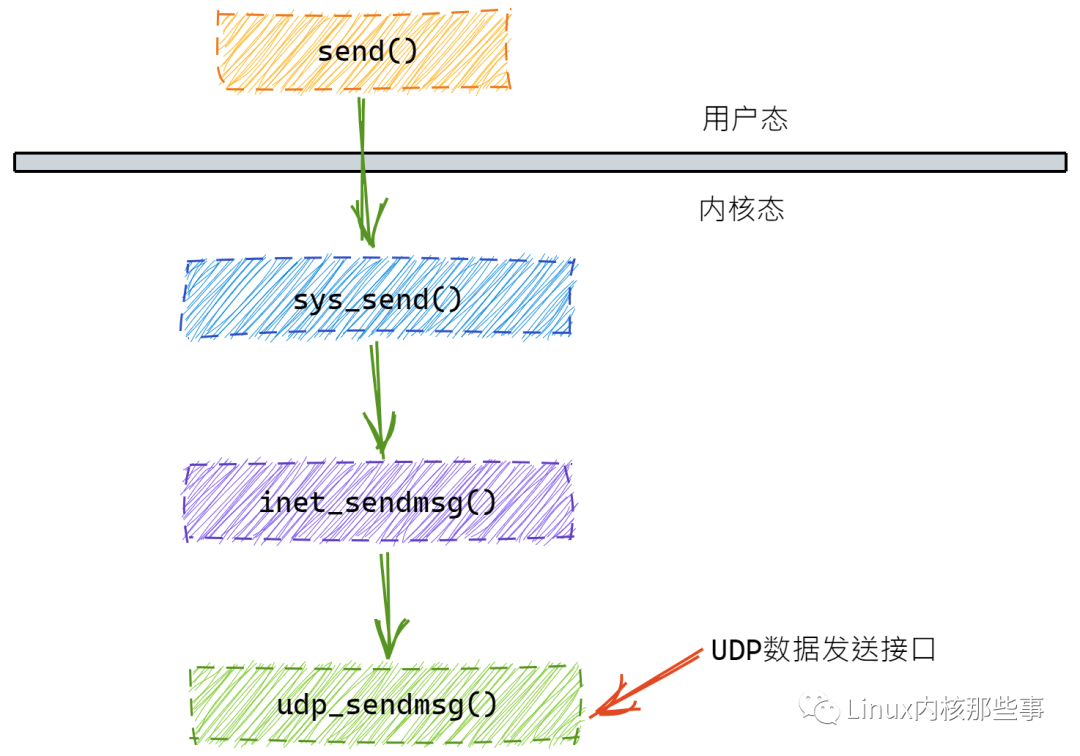
基于 Jetson 官方 Docker 镜像制作所需镜像的步骤
关于Docker的基础知识见:FunnyWii's Zone Docker基础知识 硬件设备:天准Orin,基于Nvidia Jetson Orin 系统版本:Ubuntu 20.04 需打包的库:CUDA,OPENCV 值得一提的是,我的设备是ARM架构的。所以要注意一点,使用 Docker 构建
Docker基础知识
Docker基础知识 Docker的优势在于一次创建或配置,便可在任意地方正常运行。使用一个标准镜像构建一套开发容器,在开发完成后,其他人便可使用这个容器来部署代码。 相比传统的虚拟机VM是在硬件层面实现虚拟化,Docker是在操作系统层面实现了虚拟化,直接复制 localhost 的操作系统 Do

使用OpenCV的VideoCapture的实例化vector读取多个相机
写在前面 现在车上有7个相机,如果想要用OpenCV同时读取这些相机的画面的话,实例化7个 VideoCapture是没有问题的,虽然会涉及到多线程的问题,但是多线程我还不会(ciao,是反废话)。直接实例化多个 VideoCapture未免有些显得技术力过低,因此使用 vector容器来存放读取的