

BEVFusion有两篇论文:
一篇名为《BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework》,发表于2022年。
另一篇名为《BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation》,发表于2024年。
本文介绍第一篇,文中出现的BEVFusion也是指代此篇。
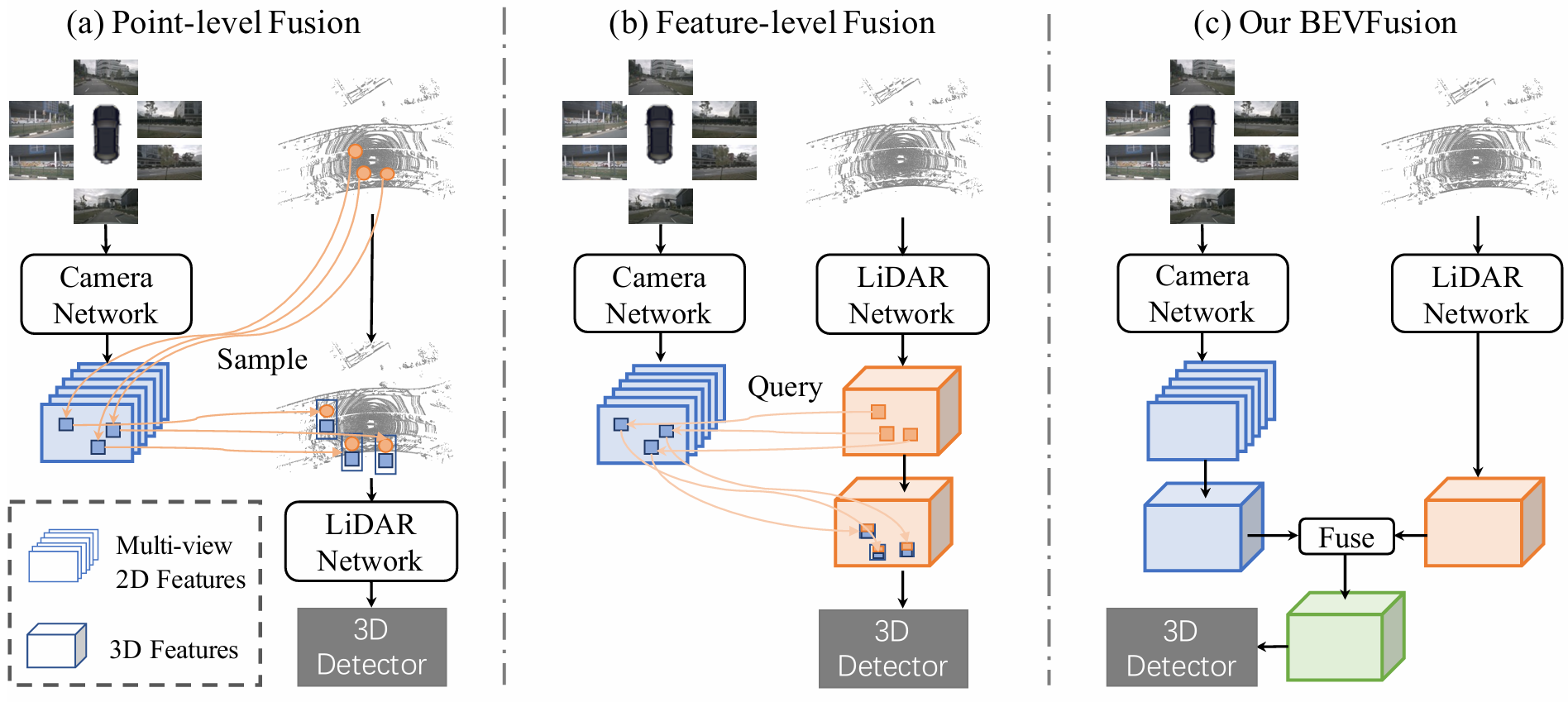
这篇论文认为,LiDAR数据过于稀疏,且经常局部缺失。对Camera-LiDAR多模态的模型,在任一模态数据缺失时仍然能正常运行。双模态的数据协同可以进一步提升精度。
BEVFusion的框架通过将Camera分支和LiDAR分支处理解耦,从根源上解决了某模态传感器数据缺失时导致模型不能正常工作的问题。
框架分为3部分:
Camera Stream
LiDAR Stream
BEVFusion Prediction
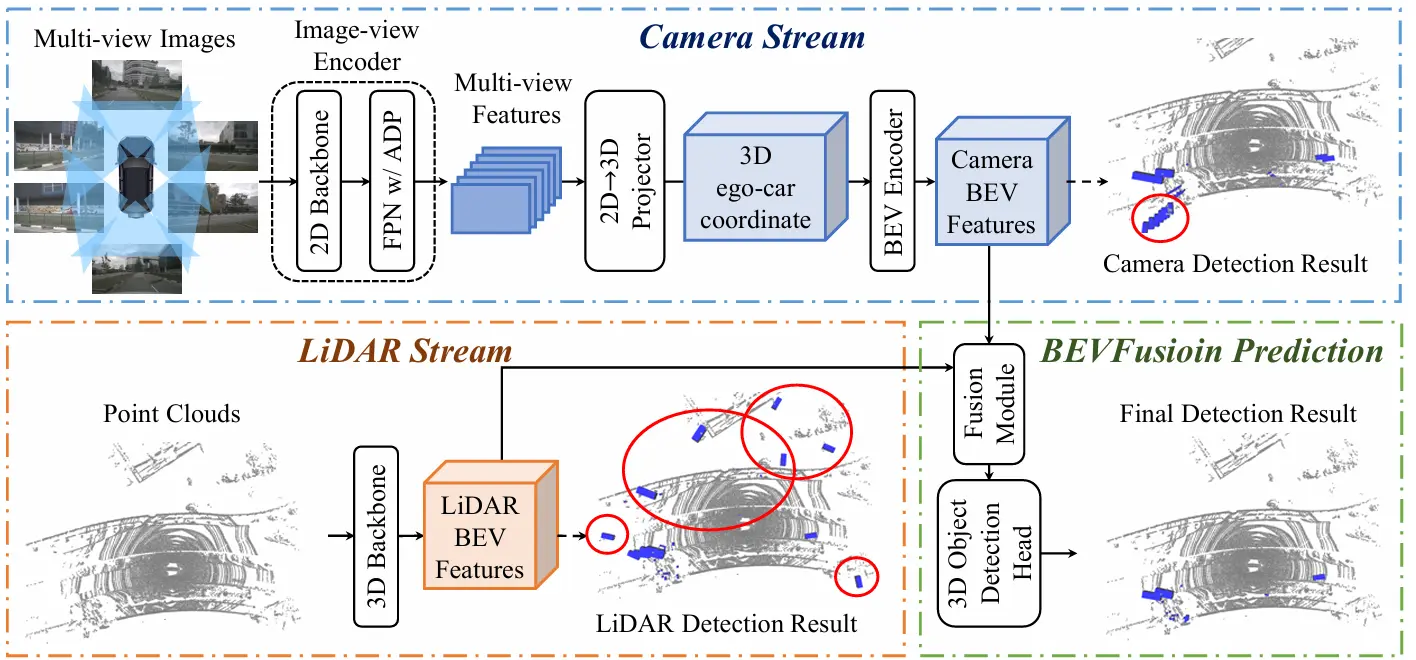
Camera Stream
基于LSS,不过由于LSS最初面向BEV的Semantic Segmentation,而非Detection任务,因此没有直接沿用其结构。
相机分支包含3部分结构,
图像编码器:BEVFusion采用Swin-Tiny(Shift Windows Transformer)作为主干,主干网络后的Neck为FPN,挖掘多分辨率尺度特征。
视角投影模块:设计的投影模块用于将2D图像特征转换到ego-3D坐标系。以2D特征为输入,通过分类方式对深度进行预测。结合相机外参和深度,得到伪体素
BEV编码器:将进一步编码为BEV空间的特征。为了最大程度保留空间信息,不使用下采样/池化,而是采用空间转通道(Spatial to Channel, S2C),将4D Tensor转换为3D Tensor,尽可能保留语义并降低计算开销。
num_views = 6
model = dict(
type='BEVF_TransFusion',
freeze_img=True,
se=True,
camera_stream=True,
grid=0.6,
num_views=6,
final_dim=final_dim,
downsample=downsample,
imc=imc,
lic=256 * 2,
lc_fusion=True,
pc_range = point_cloud_range,
img_backbone=dict(
type='CBSwinTransformer',
...
out_indices=(0, 1, 2, 3),
use_checkpoint=False),
img_neck=dict(
type='FPNC',
...
out_channels=256,
outC=imc,
use_adp=True,
num_outs=5),图像编码器
Backbone采用 CBSwinTransformer,输出4个stage的特征,通道分别是96/192/384/768。标准的多尺度 Transformer 图像编码器。
Neck就是FPN,把4种尺度的特征进行融合,输出统一通道(256)的图像特征给下游LSS模块使用。
img_backbone=dict(
type='CBSwinTransformer',
embed_dim=96,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
window_size=7,
...
out_indices=(0, 1, 2, 3),
use_checkpoint=False),
img_neck=dict(
type='FPNC',
final_dim=final_dim,
downsample=downsample,
in_channels=[96, 192, 384, 768],
out_channels=256,
outC=imc,然后到BEV特征是基于LSS的。这部分输入是上游的图像特征:
class CamEncode(nn.Module):
# D: 深度 bins 的数量
# C: 最终输出的特征通道数
# inputC: 输入图像特征的通道数
def __init__(self, D, C, inputC):
super(CamEncode, self).__init__()
self.D = D # 深度离散层数
self.C = C # 特征通道数
# 1x1 卷积:把输入特征 → 输出 (D + C) 个通道
# 前 D 个通道:预测深度概率
# 后 C 个通道:图像特征
self.depthnet = nn.Conv2d(inputC, self.D + self.C, kernel_size=1, padding=0)
# 对深度预测做 softmax,得到归一化的深度概率分布
def get_depth_dist(self, x, eps=1e-20):
return x.softmax(dim=1) # 在深度维度做 softmax
# 预测深度 + 生成 3D 深度特征
def get_depth_feat(self, x):
# 1. 1x1 卷积得到深度预测 + 图像特征
x = self.depthnet(x)
# 2. 取出前 D 个通道 → 做 softmax → 得到每个像素属于哪个深度的概率
depth = self.get_depth_dist(x[:, :self.D])
# 3. 深度权重 × 图像特征 = 3D 体素特征
# depth.unsqueeze(1) → (B, 1, D, H, W)
# x_feat.unsqueeze(2) → (B, C, 1, H, W)
# 广播相乘机制 → (B, C, D, H, W)
new_x = depth.unsqueeze(1) * x[:, self.D:(self.D + self.C)].unsqueeze(2)
return depth, new_x视角投影
通过几何变换从frustum(u, v, d)转换到车体ego的3D点:
def get_geometry(
self,
rots, # 相机外参:旋转矩阵 R (B, N, 3, 3)
trans, # 相机外参:平移向量 T (B, N, 3)
post_rots=None,
post_trans=None,
extra_rots=None,
extra_trans=None
):
B, N, _ = trans.shape
# B = batch 大小
# N = 相机数量(比如 nuScenes 有 6 个相机)
# 生成图像视锥点(frustum)
if post_rots is not None or post_trans is not None:
... # 图像增强后的坐标变换(不重要)
else:
# self.frustum:预先定义好的图像视锥点 (H, W, D, 3)
# repeat → 扩展到 B, N 维度
# points 形状:[B, N, H, W, D, 3, 1]
points = self.frustum.repeat(B, N, 1, 1, 1, 1).unsqueeze(-1)
# 步骤2:像素坐标 → 相机坐标系
# points[:, :, :, :, :, :2] = (u, v) 像素坐标
# points[:, :, :, :, :, 2:3] = depth 深度
# 公式:x = u * d, y = v * d, z = d, 经典的变换公式[u, v, 1] * z_c
points = torch.cat((
points[:, :, :, :, :, :2] * points[:, :, :, :, :, 2:3],
points[:, :, :, :, :, 2:3]
), 5)
# 相机坐标系 → 车身坐标系(外参旋转)
points = rots.view(B, N, 1, 1, 1, 3, 3).matmul(points).squeeze(-1)
# 加上平移向量(外参平移)
# points = R @ p + T
points += trans.view(B, N, 1, 1, 1, 3)
return points这部分核心原理是相机外参变换公式:
BEV特征
把散落在3D空间里的特征Splat到BEV网格里,生成最终的BEV特征。
def voxel_pooling(self, geom_feats, x):
B, N, D, H, W, C = x.shape
...
geom_feats = ((geom_feats - (self.bx - self.dx / 2.)) / self.dx).long()
...
kept = (geom_feats[:, 0] >= 0) & (geom_feats[:, 0] < self.nx[0]) \
& (geom_feats[:, 1] >= 0) & (geom_feats[:, 1] < self.nx[1]) \
& (geom_feats[:, 2] >= 0) & (geom_feats[:, 2] < self.nx[2])
...
final = torch.zeros((B, C, self.nx[2], self.nx[0], self.nx[1]), device=x.device)
final[geom_feats[:, 3], :, geom_feats[:, 2], geom_feats[:, 0], geom_feats[:, 1]] = x
return final然后再使用S2C
def s2c(self, x):
B, C, H, W, L = x.shape
bev = torch.reshape(x, (B, C*H, W, L))
bev = bev.permute((0,1,3,2))
return bev
def forward(self, x, rots, trans, lidar2img_rt=None, img_metas=None, post_rots=None, post_trans=None, extra_rots=None,extra_trans=None):
x, depth = self.get_voxels(x, rots, trans, post_rots, post_trans,extra_rots,extra_trans)
bev = self.s2c(x)
x = self.bevencode(bev)
return x, depthLiDAR Stream
对原始点云执行Voxelization,压缩高度维度,然后借助Sparse 3D Conv提取BEV特征。
model = dict(
type='TransFusionDetector',
pts_voxel_layer=dict(
max_num_points=10,
voxel_size=voxel_size,
max_voxels=(120000, 160000),
point_cloud_range=point_cloud_range),
pts_voxel_encoder=dict(
type='HardSimpleVFE',
num_features=5,
),
pts_middle_encoder=dict(
type='SparseEncoder',
in_channels=5,
sparse_shape=[41, 1440, 1440],
output_channels=128,
order=('conv', 'norm', 'act'),
encoder_channels=((16, 16, 32), (32, 32, 64), (64, 64, 128), (128, 128)),
encoder_paddings=((0, 0, 1), (0, 0, 1), (0, 0, [0, 1, 1]), (0, 0)),
block_type='basicblock'),
pts_backbone=dict(
type='SECOND',
in_channels=256,
out_channels=[128, 256],
layer_nums=[5, 5],
layer_strides=[1, 2],
norm_cfg=dict(type='BN', eps=0.001, momentum=0.01),
conv_cfg=dict(type='Conv2d', bias=False)),
pts_neck=dict(
type='SECONDFPN',
in_channels=[128, 256],
out_channels=[256, 256],
upsample_strides=[1, 2],
norm_cfg=dict(type='BN', eps=0.001, momentum=0.01),
upsample_cfg=dict(type='deconv', bias=False),
use_conv_for_no_stride=True),
pts_bbox_head=dict(
type='TransFusionHead',
...
in_channels=256 * 2,
hidden_channel=128,
...
),
)通过代码可以看出,LiDAR分支是基于SECOND的Backbone最终接了TransFusion的检测头。
Fusion
融合模块可以表示为:
其中表示沿通道维度的拼接操作,是一个静态的通道与空间融合函数,由 3x3 卷积实现,用于将拼接特征的通道数压缩至。
是一个特征自适应选择函数,可以理解为一个Attention,定义为:
其中表示线性变换矩阵(如 1x1 卷积),表示全局平均池化,表示 Sigmoid 激活函数。
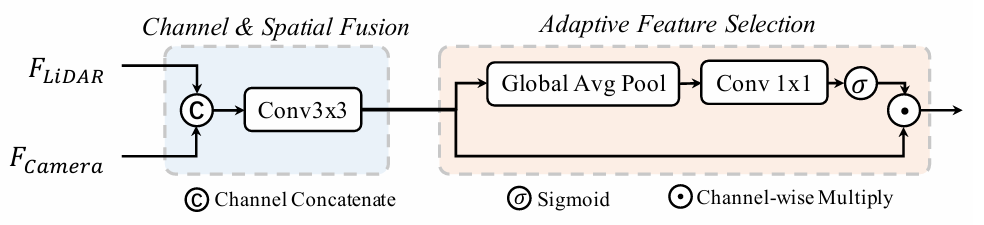
这里的Attention更偏向于通道层面,对通道维度进行加权,去关注更重要的通道。因为有些场景需要关注图像数据,有些场景更关注雷达数据。
Head
看起来论文中似乎有3个Head,Camera Head,LiDAR Head,Fusion Head,不过并不意味着网络就必须要用到3个Head,最终用到的Head只有Fusion的Head
camera
有一个单独的检测流和Head
model = dict(
type='BEVF_TransFusion',
camera_stream=True,
grid=0.6,
num_views=6,
final_dim=final_dim,
downsample=downsample,
imc=imc,
lic=256 * 2,
pc_range = point_cloud_range,
img_backbone=dict(...),
img_neck=dict(...),
pts_bbox_head=dict(
type='TransFusionHead',
fuse_img=False,
...
in_channels=imc,lidar
也有一个单独的检测流和Head
model = dict(
type='TransFusionDetector',
pts_voxel_layer=dict(
max_num_points=10,
voxel_size=voxel_size,
max_voxels=(120000, 160000),
point_cloud_range=point_cloud_range),
pts_voxel_encoder=dict(
type='HardSimpleVFE',
num_features=5,
),fusion
pts_bbox_head=dict(
type='TransFusionHead',
fuse_img=False,
num_views=num_views,
in_channels_img=256,
out_size_factor_img=4,
num_proposals=200,
auxiliary=True,
in_channels=256 * 2,
hidden_channel=128,这里 fuse_img=False, 意味着检测头这里不再对Camera和LiDAR特征进行手动融合,Head的输入就是融合完毕的特征了。
评论