
写在前面
为什么不直接输出一堆内容,主要是因为自己太菜了。上学时的那些深度学习知识,已经差不多都还给老师了,而且工程应用又是另一码事。所以我就一边用 MMYOLO 框架训模型,一边从头学起。
快成炼丹师了,不过对如何调整 hyperparameters 还是一点头绪都没。以下提到的功能使用方式,都可以在 MMYOLO 官方文档中找到说明。
MMYOLO 的安装
见 OpenMMLab 的 GitHub: OpenMMLab
因为是 Python 部署,直接新建一个 conda 环境即可。部署中遇到任何问题,可以直接 Google。需要注意的是,OpenMMLab 系列项目通常依赖 mmengine、mmcv、mmdet 等包,版本之间要互相匹配,安装时最好优先参考当前 MMYOLO 文档中对应版本的安装说明。
AMP(Automatic Mixed Precision)自动混合精度训练
AMP 指的是在神经网络训练过程中,针对不同计算步骤采用不同的数据精度,从而实现节省显存和加快训练速度的目的。PyTorch 的 AMP 功能位于 torch.cuda.amp 模块下。
Tensor Core 能显著加速 FP16 / BF16 计算,因此在支持 Tensor Core 的 NVIDIA GPU 上,AMP 的收益通常更明显。但 AMP 本身并不只限于 Tensor Core GPU,只是不同硬件上的加速效果会有差异。
- 自动:Tensor 的 dtype 类型会根据上下文自动变化,框架按需调整 tensor 的 dtype。当然,有些地方仍然需要手动干预。
- 混合精度:训练过程中不只使用一种精度,例如同时使用
torch.FloatTensor和torch.HalfTensor。
大多数深度学习框架默认采用 32 位浮点数(FP32)进行训练。NVIDIA 使用的方法,是在训练网络时将单精度(FP32)与半精度(FP16)结合起来,在节省显存和提升速度的同时,尽量保持与 FP32 接近的精度。
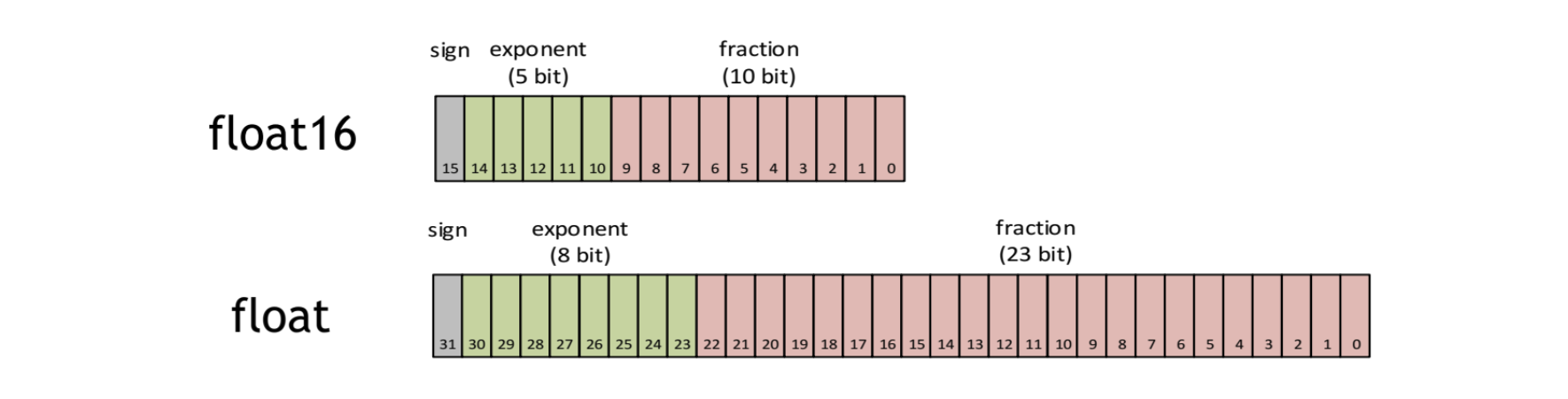
FP16 的优势主要有三个:
- 减少显存占用。
- 加快训练和推断计算。
- 随着 Tensor Core 普及,低精度计算会越来越常见。
FP16 也存在缺陷:
- 溢出错误。由于 FP16 的表示范围比 FP32 小很多,计算时容易出现上溢出和下溢出,也就是 NaN 问题。激活函数梯度通常比权重梯度小,更容易出现下溢出。
- 舍入误差。当梯度过小,小于当前数值区间内的最小间隔时,该次梯度更新可能会失败。
因此,混合精度训练通常用 FP16 / BF16 做部分计算以加速和节省显存,同时保留 FP32 master weights 或在关键步骤使用 FP32 累加,并配合 loss scaling 降低溢出和下溢风险。
冻结指定网络层权重
一些概念
先理解 Backbone、Neck 和 Head 的概念。
- Backbone:骨干网络,主要用于特征提取,通常是在大型数据集(例如 ImageNet、COCO 等)上完成预训练并拥有预训练参数的卷积神经网络,例如 ResNet-50、Darknet53、VGG-16、ResNeXt-101 等。
- Neck:位于 Backbone 和 Head 之间的网络层,用于混合和组合图像特征,并将图像特征传递到预测层。常见结构包括 Path-aggregation blocks 和 Additional blocks。
- Path-aggregation blocks:FPN(Feature Pyramid Network)、PANet(Path Aggregation Network)、NAS-FPN、Fully-connected FPN、BiFPN、ASFF、SFAM 等。
- Additional blocks:SPP、ASPP、RFB、SAM 等。
- Head:检测头,用于预测目标位置和类别,输出 Bounding Box(BBox)。可以分为 Dense Prediction 和 Sparse Prediction。
- Dense Prediction:RPN、YOLO、SSD(Single Shot MultiBox Detector)、RetinaNet、FCOS 等。
- Sparse Prediction:Faster R-CNN、R-FCN、Mask R-CNN 等。
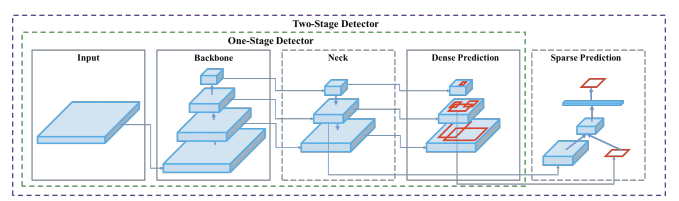
深度学习目标检测模型的一般结构是:
Input -> Backbone -> Neck -> Head -> Output
Backbone 提取基础特征,Neck 融合更复杂、更深层的特征,Head 继续完成目标分类和位置预测。
以 YOLOv4 为例:
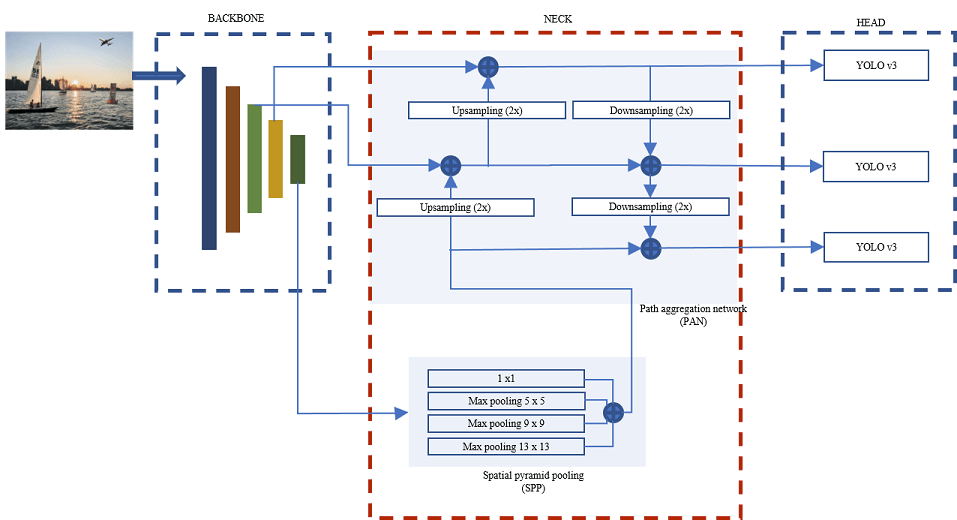
Backbone:CSPDarknet53。
Neck:SPP + PAN。
Head:YOLOv3。
冻结网络层
对于数据集本身很小(几千张图片)的情况,从头开始训练具有几千万参数的大型神经网络并不现实。模型越大,对数据量的要求越高,过拟合也越难避免。这时候如果还想用上大型神经网络的特征提取能力,一般需要对预训练模型进行微调。
对于图片来说,网络前几层学习到的通常是低级特征,例如点、线、边缘、纹理等。这些低级特征在不同视觉任务中比较通用,因此常见做法是冻结前几层通用低级特征,只微调后几层更任务相关的高级特征。例如,这些点、线、面组合起来之后,代表的是圆、椭圆、正方形,还是更具体的目标类别,这些更接近目标任务语义。
对于语音或其他任务来说,是否冻结低层、微调高层,并没有绝对结论。迁移学习中冻结哪一层、微调哪一层,取决于源任务和目标任务的差异、数据量大小、模型结构以及训练成本。不能简单类比为所有任务都只微调低级特征或高级特征。
在视觉领域,Fine-tuning 常见做法是固定前几层参数,只对最后几层进行微调。也可以保留预训练模型作为初始化,然后 Fine-tuning 整个网络。这种方式计算量更大,但能让模型整体适应新数据集。目前我是这样做的。
被冻结的层仍然可以参与正向传播和反向传播,但这些层的参数不再更新;未冻结的层正常更新。
随机种子
在同一开发环境中,随机数种子 seed 确定时,模型训练结果通常会更稳定、更容易复现。
不过,这不等于训练结果一定完全一致。CUDA / cuDNN 的非确定性算子、数据加载顺序、多卡通信、不同驱动版本和不同硬件环境,都可能带来细微差异。如果需要严格复现,还需要额外设置确定性算法、固定数据加载随机性,并记录完整环境。
注意力机制
Context Block
Non-local Networks
Test-Time Augmentation(TTA,测试时数据增强)
数据增强是一种在模型训练期间使用的方法。它通过对训练数据集中已有样本进行修改,生成更多训练样本,从而扩展训练集。图像任务中常见的数据增强包括缩放、翻转、平移、裁剪、颜色扰动等。
TTA 则发生在测试或推理阶段。它会对同一张输入图像做多种增强变换,分别送入模型推理,再把多个预测结果融合起来。这样通常能提升精度,但会增加推理耗时。
MMYOLO 框架的应用
数据集
MMYOLO 框架支持多种格式的数据集,包括 COCO、VOC 等。目前我用的是 VOC 格式的数据集,标注为 XML 格式。
使用下面的命令可以下载 VOC2012 数据集:
python tools/misc/download_dataset.py --dataset-name voc2012
需要注意,VOC2012 和 VOC2007 是无交集的两个数据集。之后将数据集划分为训练集和测试集。我的数据集比较少,所以没有单独划分验证集。
不过,一般更推荐至少划分出 train / val,或者进一步划分 train / val / test。否则训练过程中很难及时判断模型是否过拟合,也不方便比较不同配置的效果。
配置文件的命名
接下来是配置文件,例如 yolov8_x_syncbn_fast_8xb16-500e_psvoc.py。MMYOLO 官方命名规则大致遵循:
{algorithm name}_{model component names [component1]_[component2]_[...]}-[version id]_[norm setting]_[data preprocessor type]_{training settings}_{training dataset information}_{testing dataset information}.py
文件名分为 8 个部分,其中 4 个必填、4 个可选。每个部分用 _ 连接,每个部分内的单词应该用 - 连接。{} 表示必填部分,[] 表示选填部分。
- {algorithm name}:算法名称,可以是检测器名称,例如 YOLOv5、YOLOv6、YOLOX 等。
- {component names}:算法中使用的组件名称,例如 backbone、neck 等。
- [version_id](可选):由于 YOLO 系列算法迭代速度远快于传统目标检测算法,因此使用 version id 区分不同子版本之间的差异。
- [norm_setting](可选):
bn表示 Batch Normalization,syncbn表示 Synchronized Batch Normalization。 - [data preprocessor type](可选):数据预处理类型。
- {training settings}:训练设置,例如 batch 大小、数据增强、损失函数、参数调度方式和训练最大 epoch / iteration。
- {gpu x batch_per_gpu}:GPU 数和每个 GPU 的样本数。
bN表示每个 GPU 上的 batch 大小为N。例如4x4b是 4 个 GPU、每个 GPU 4 张图的缩写。如果没有注明,默认为 8 卡每卡 2 张图。 - {schedule}:训练方案,MMYOLO 中默认是 300 个 epoch。
- {training dataset information}:训练数据集,例如 COCO、Cityscapes、VOC-0712、WIDER FACE、balloon。
- [testing dataset information](可选):测试数据集,用于训练和测试在不同数据集上的模型配置。如果没有注明,则表示训练和测试的数据集类型相同。
配置文件内容
MMYOLO 采用模块化设计,所有功能模块都可以通过配置文件进行配置。
大部分配置文件的内容可以在 MMYOLO 官方配置教程中找到,里面有详细注释:
https://github.com/open-mmlab/mmyolo/blob/main/docs/zh_cn/tutorials/config.md
我用得更多的是配置文件继承。
配置文件继承
官方指南挂掉力,悲:
https://mmengine.readthedocs.io/zh_CN/latest/tutorials/config.html
那我没地方复制粘贴力,根据自己的理解说一点。
在 config/_base_ 文件夹中,有 default_runtime.py 运行时默认配置和 det_p5_tta.py TTA 默认配置,这些是原始配置。在同一个文件夹,比如 configs/yolov8 中,官方建议只有一个对应的原始配置文件,以确保最大继承深度为 3。
大部分情况下,可以直接继承现有方法。例如 yolov8_s_syncbn_fast_8xb16-500e_coco.py 就是最基本的现有配置,你会发现 m、l、x 等模型配置都是继承于上一个配置。模型 size 的变化也主要基于 deepen_factor 和 widen_factor 的变化。因此,只需要指定 _base_ = yolov8_s_syncbn_fast_8xb16-500e_coco.py,继承基础结构后再修改必要的网络参数,就可以实现自定义或修改网络的功能。
如果要忽略基础配置文件中的某些内容,可以设置:
_delete_ = True
参考文章
[1] 卷积神经网络中的 Backbone、Neck 和 Head
[4] Getting Started with YOLO v4
[5] Fine-tuning
[6] GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
[9] MMYOLO 配置文件教程
评论