

没想到 YOLOv1 到 YOLOv4 就已经写了快 20000 字……
编辑页面卡的不行,我不得不分几篇写完。YOLOv1 到 YOLO 26一共 12 篇,正好分上中下三篇。
YOLOv5
重量级来了,Ultralytics 闪亮登场了。第一个没有论文的 YOLO 正式版本,但它成为了工业界的事实标准。
YOLOv5 的一大变化就是提供了多种模型尺寸:n/s/m/l/x,通过统一的的 depth_multiple(深度倍数)和 width_multiple(宽度倍数)参数缩放。基准模型也就是没有缩放的版本是 l 。
其中 depth_multiple 参数实际上控制的是可重复模块(如 C3、BottleneckCSP)的堆叠次数。width_multiple 控制的则是卷积层的通道数,
Pytorch
YOLOv4 仍然基于 DarkNet 框架,没有使用 PyTorch,底层用 C 语言实现,网络结构通过 cfg 文件定义,而非 yaml 文件或者 python 代码,训练和二次开发门槛高,部署也很麻烦。
YOLOv5 完全使用 PyTorch 框架实现,原生支持 Onnx/TensorRT 等部署导出,十分方便。
俺寻思,后来 Pytorch 一统天下, YOLOv5 功不可没。
网络设计上,延续 YOLO 经典结构: Input --> Backbone(特征提取) --> Neck(特征融合) --> Head(检测头)。
Input
YOLOv4 引入了 Mosaic,v5 则是直接集成 Mosaic 到默认训练流程。
YOLOv5 加入了 AutoAnchor,K - means 之后用遗传算法优化得到最佳 Anchor,每次训练开始之前,会根据数据集自适应计算 Anchor。在此之前 Anchor 需要手动调整。
Focus
Focus 模块位于网络最前端,紧接输入,作用是将空间维度上的信息聚焦到通道维度,实现2倍下采样,但是不丢失任何信息。
假设输入一个 640 × 640 × 3 的图像,空间维度上拆分成 2 × 2 的Grid,就是 4 块区域,注意这里不是从整体上切分,看下图:
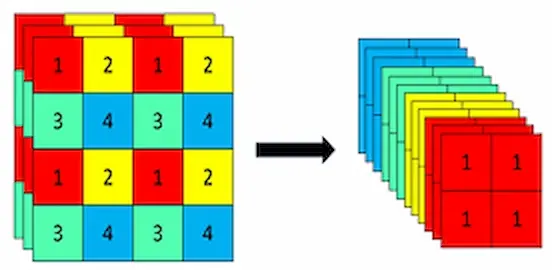
然后就得到了 4 张 320 × 320 × 3的特征图,然后在通道维度上做拼接得到 12 通道的 320 × 320 特征图,最后用 1 × 1 卷积映射到目标通道数。
后来这个模块被一个 Conv(6, 2) 即 k=6, s=2 的卷积层给替代了。主要是考虑到内存连续访问和推理引擎原生优化的问题。
CSP + C3
也就是从这时候开始,YOLO 开始出现很多网络结构(初看会感觉意义不明)的缩写,罪大恶极。你叫 CBL 我能理解为 Conv + BN + LeakyReLU,可这 C3 是个什么玩意儿?
先说一下 BottleNeck,这个在前面没有提到,是一种先压缩、再提取、再恢复信息的残差模块。举个简单的例子:
输入:H × W × 256
通道投影(1×1 Conv):
→ H × W × 64
空间特征提取(3×3 Conv,stride=1,padding=1):
→ H × W × 64
通道映射恢复(1×1 Conv):
→ H × W × 256
类似瓶颈,先宽后窄再宽,降维之后再用 3 × 3 卷积可以有效降低计算量。这里的降维类似一次通道投影,可以朝PCA那个方向去理解,降维之后得到的是比较有价值的特征,而不是白白损失掉了。
还可以接残差 shortcut,把网络堆的更深。在 Backbone 一般用带残差的,缓解深层网络梯度消失的问题。 Neck 一般用不带残差的,因为 Neck 用于特征融合,本来就浅。
C3 就是多个 BottleNeck 融合 CSP 思想的产物。
那我们复习一下 CSP 是啥呢……感觉距离看完上篇文章已经过了5分钟了捏……
CSP 就是把特征从通道维度拆分,一部分通道继续向深处走,另一部分直接走捷径,最后再融合;和ResNet的区别是,ResNet需要全部通道参与运算。
YOLOv5 的 C3 结构可以理解成 n 个 BottleNeck串联又 加了3个卷积层。具体结构可以参考下图的 CSPLayer,其中的 ConvModule 是 CBS。
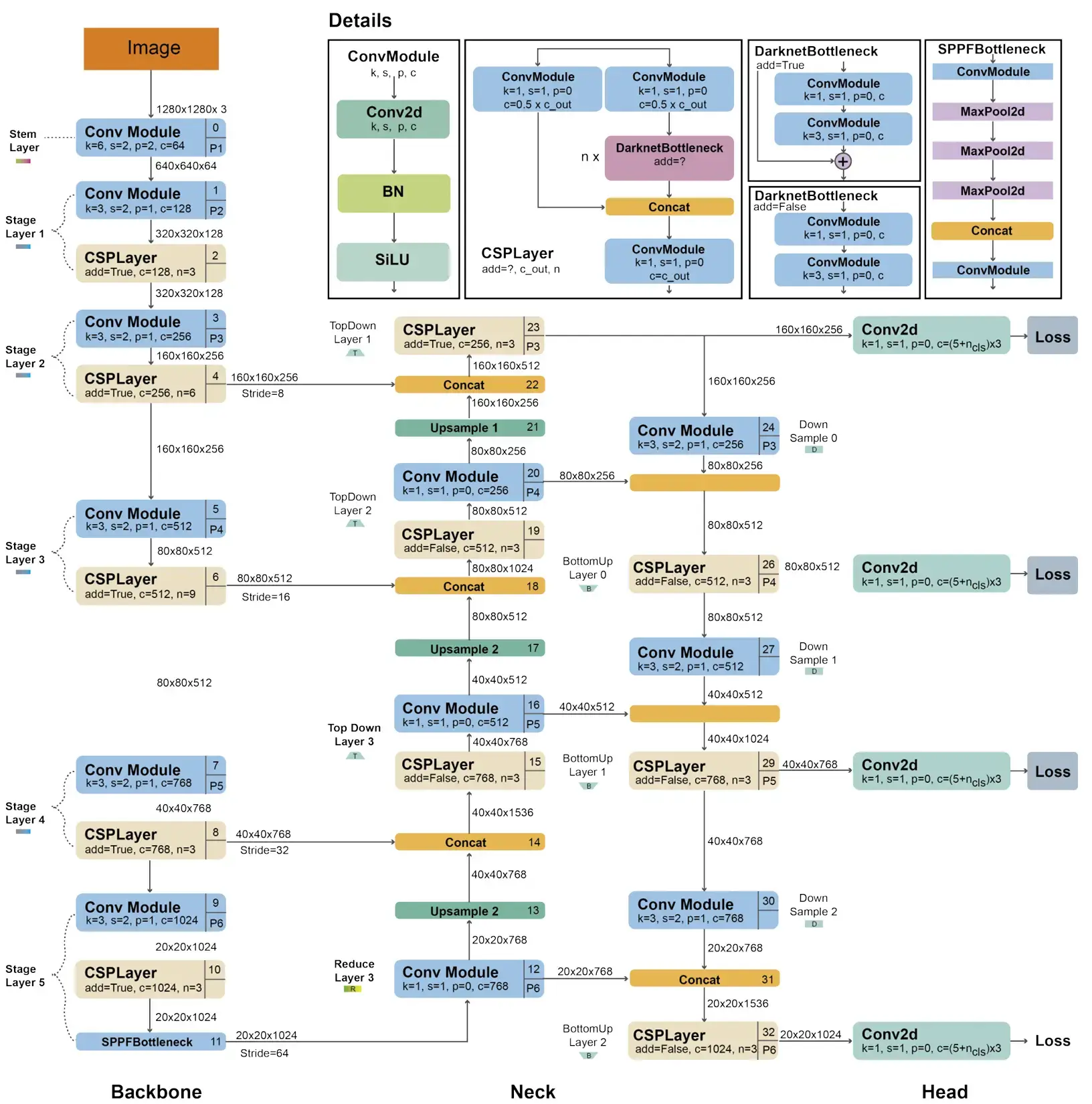
C3 替代的是 YOLOv4 中的 BottleneckCSP;而 BottleneckCSP 替代的是原始 Darknet53 中的 Residual Block。
SPPF
Faster 的 SPP,YOLOv5 的重要工程优化,速度更快,但是精度上……YOLOv5没论文,没消融实验,俺不知道……
为啥串行反而 Fast 了呢?不是并行更快么?
SPPF 是用串行 5 × 5 的 MaxPooling 来取代并行的 5/9/13 的 SSP,上图对 SPPF 的绘制有误,实际上是跳连后才 Concat 的。
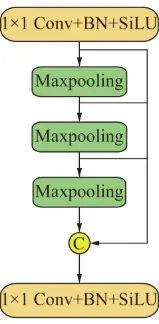
SPP 的计算量:
5×5 池化:O(25 \times H \times W \times C)
9×9 池化:O(81 \times H \times W \times C)
13×13 池化:O(169 \times H \times W \times C)
总计算量:O((25 + 81 + 169) \times H \times W \times C) = O(275 \times H \times W \times C)
SPPF 的计算量:
3 次 5×5 池化:O(3 \times 25 \times H \times W \times C) = O(75 \times H \times W \times C)
计算量小了不少。但是 SPPF 和 SPP 功能上完全相同。
YOLOv6
美团视觉智能部提出的。其实在 YOLOv5 之后,我对 Ultralytics 以外的团队突出的 YOLO 就不是很感兴趣了……
YOLOv6 也是针对工程部署做的优化,更关注:高FPS + 高精度 + 易于部署。也是第一次训练时支持 INT8 量化,其他模型都是 PTQ 训练后用 TensorRT 之类的做 INT8 量化。
Backbone
引入(chong)重参数化 Reparameterization 的思想,重参数化就是:即让模型在训练时和推理时拥有两种不同的结构。
Backbone 采用 RepVGG 风格设计。RepVGG 和 ResNet 一样都是图像分类网络。
训练阶段:每个基本模块包含三条并行分支——3×3 卷积、1×1 卷积和恒等映射(Identity),并分别接入 BatchNorm。这种多分支结构类似于 ResNet 的残差连接,能够提供丰富的梯度流和特征表示能力。
推理阶段:通过结构重参数化技术,将三条分支的权重和偏置通过代数变换融合为一个等价的 3×3 卷积层。最终推理网络退化为纯粹的 VGG 风格——仅由 3×3 卷积和 ReLU 顺序堆叠而成,没有任何跳跃连接、分支或复杂的拓扑结构。[4]
Neck
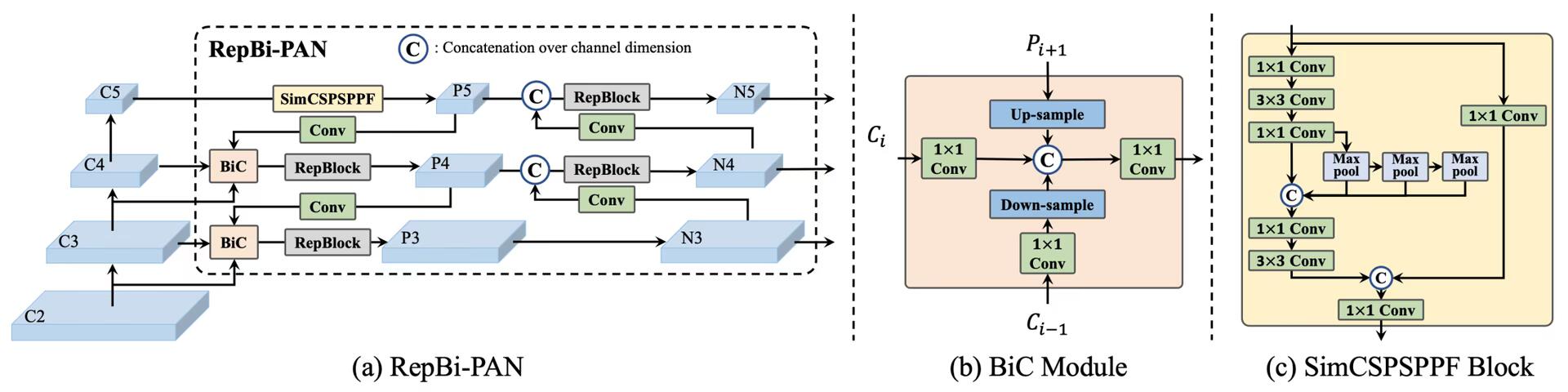
使用 Rep-PAN + CSPStackRep。
Rep-PAN 就是 PAN + 重参数化模块替换。
CSPStackRep 就是 CSP 分流结构 + RepBlock 重参数化。
BiC (Bi-directional Concatenation)
Head
Anchor-Free 解耦头,把分类和回归在一个输出分支里面拆开,让它们做各自的事。
Anchor 这玩意儿是犯什么罪了吗一会用一会不用的……我感觉一开始 v1 没用 Anchor 是因为没想到,v2 之后借鉴了 R-CNN 的 Anchor,效果有提升,就沿用了下去,但是后面随着 DL 的发展,发现 Anchor 缺点也多,毕竟是个超参数,调不好会对精度有影响,从 YOLOX 之后就引入了 Anchor-Free + 解耦头,证明无需 Anchor 也能达到 Anchor-Based 的效果。
YOLOv5之前 输出 [ x, y, w, h, obj, cls... ] 格式的结果,位置(回归)和语义(分类)信息是掺和在一起的。
参考文章
[1] ultralytics/yolov5: Ultralytics YOLOv5 in PyTorch > ONNX > CoreML > TFLite
[2] A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS
[3] YOLOv11 改进 - 基础知识 为什么SPPF比SPP更快?深入解析YOLO中多尺度特征提取的效率优化与代码实现 - 魔改工程师 - 博客园
[4] 2101.03697v1
[5] [2209.02976] YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
评论