

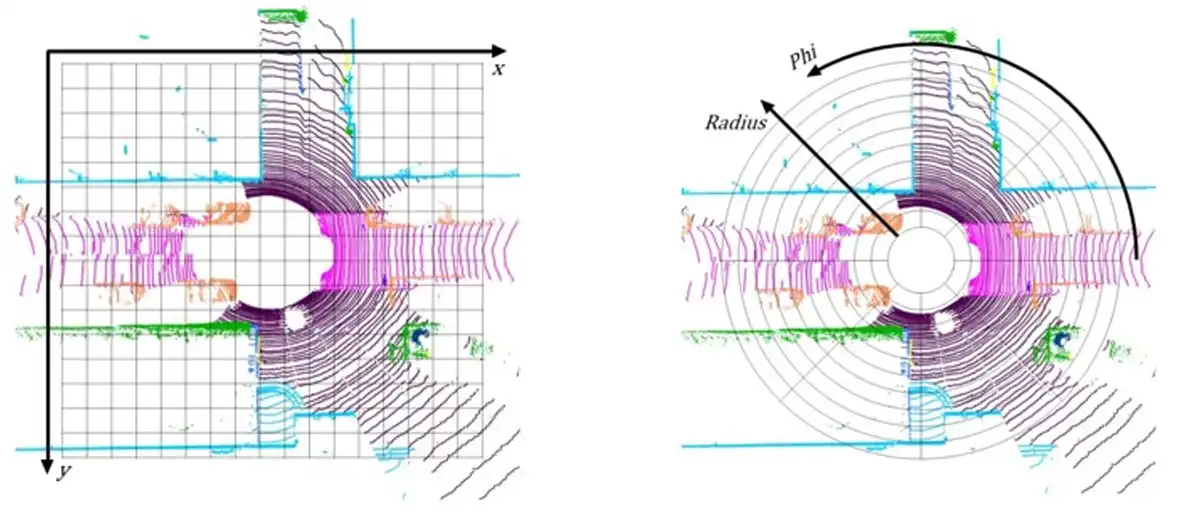
极坐标BEV的表示方法:在BEV空间按照角度和半径两个维度进行划分,而非笛卡尔坐标系下的均匀矩形网格。自车近处高分辨率,远处低分辨率,契合相机近大远小的成像特点。
核心优势
非均匀网格划分&分辨率优化
极坐标BEV以ego为中心,角度方向采用固定步长划分,径向长尾分布不均匀划分。
角度划分:θ ∈ [-π, π),以固定步长Δθ划分为N = 2π/Δθ个扇区
径向划分:ρ ∈ [0, ρ_max),采用非均匀间隔Δρ_i,i=1,...,M
高度估计替代深度估计
特征表示与相机成像特性匹配
相机的成像特性有:相同角度不同距离的物体在图像中具有相似外形但不同尺度,相同距离不同角度的物体在图像中具有相似尺度但不同外形。
极坐标网格划分使得同一角度不同距离的物体特征在BEV中具有更好的连续性。减少了特征提取过程中的信息损失,提高了BEV特征的表达能力。
特别是LiDAR数据,极坐标划分能有效减少远距离区域的计算冗余。
PolarNet
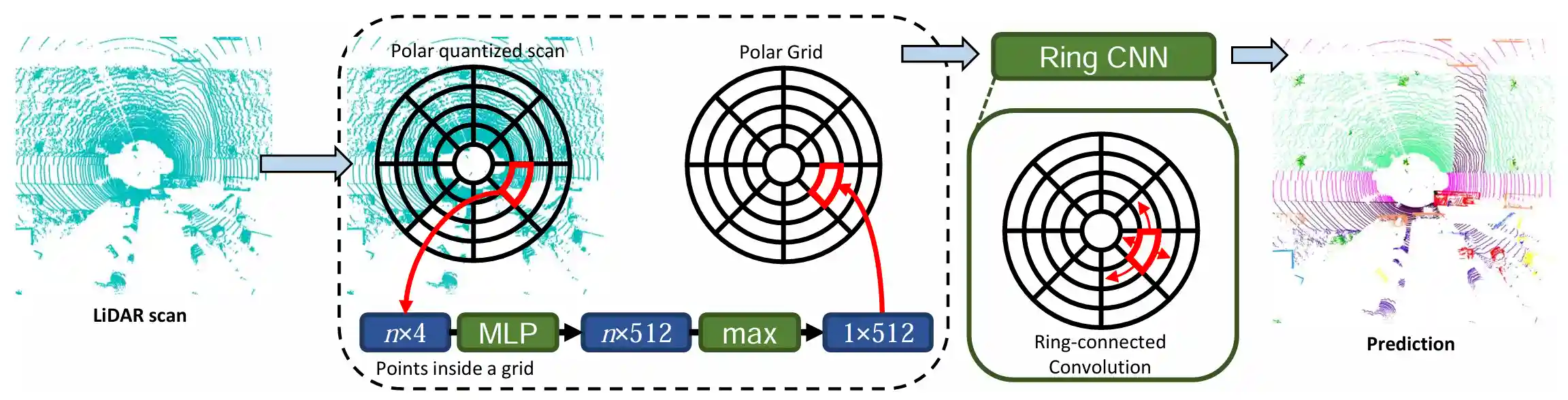
极坐标BEV早期方法,使用单模态LiDAR数据进行语义分割任务。
核心创新点包括以下三点:
极坐标点云投影和特征提取
将3D点云在BEV视角投影到极坐标系,形成环形网格。由于极坐标网格的面积随着半径增加而增大,正好抵消并对齐了LiDAR点云近密远疏的密度变化,使得每个网格内的点数更加均匀。
同时论文通过实验发现,同一个网格里的点属于同一种语义类别的概率,比直角坐标网格更高。这一点从激光雷达的原理也能相通,因为雷达的光打出去就是射线,Polar的网格边界和射线天然贴合。再转念一想,和相机的原理也相同,图像上的每个像素也对应一条射线。/
# 笛卡尔坐标 → 极坐标变换
def cart2polar(input_xyz):
rho = np.sqrt(input_xyz[:,0]**2 + input_xyz[:,1]**2) # 距离
phi = np.arctan2(input_xyz[:,1], input_xyz[:,0]) # 角度
return np.stack((rho, phi, input_xyz[:,2]), axis=1)
# 在 spherical_dataset 中:
xyz_pol = cart2polar(xyz) # 转换为极坐标
grid_ind = (np.floor((np.clip(xyz_pol, min_bound, max_bound) - min_bound) / intervals)).astype(np.int)代码描述了普通BEV也就是笛卡尔坐标系下的特征到极坐标的转换过程。输入input_xyz 为N×3的点云数据。
先通过input_xyz[:,0]和input_xyz[:,1]坐标计算点在平面上到中心的距离,即半径。
再通过上述2个坐标的arctan计算,得到夹角。
Grid 结构 [distance, angle, height (pc.z)] 。
使用Simplified PointNet网络提取每个网格单元的特征。很多Point-Level的点云算法,都得用KNN来构建局部特征。PolarNet使用简化PointNet极大提高点云序列化的速度。
环卷积(Ring Convolution)
2D卷积起初在边界采用Zero-Padding,对2D特征这样做毫无问题,但是极坐标下0°和360°在物理空间上是连续的。
为应对极坐标网格中角度维度的周期性连续的特性,在角度轴的两端进行Circular Padding(循环填充),消除边界的截断效应。
代码如下:
class double_conv_circular(nn.Module):
'''(conv => BN => ReLU) * 2'''
def __init__(self, in_ch, out_ch, group_conv, dilation=1):
super(double_conv_circular, self).__init__()
# ... 初始化代码
def forward(self, x):
# 添加循环填充(环形填充)
x = F.pad(x, (1,1,0,0), mode='circular') # 左右方向循环填充
x = self.conv1(x)
x = F.pad(x, (1,1,0,0), mode='circular') # 再次循环填充
x = self.conv2(x)
return x虽然图像中是一个圆形区域,但是特征最终还是会被抻成矩形再进行卷积。
对于一个2D特征,也可以说是4D Tensor: [Batch, Channel, Height, Width] 而言,pad函数的(1,1,0,0)参数可以理解为:
# F.pad(x, (left, right, top, bottom, front, back, ...))
# (最后维 最后维 倒数2维 倒数2维 倒数3维 倒数3维)
F.pad(x, (1, 1, 0, 0), mode='circular')
│ │ │ │
│ │ │ └── Height 下方填充 0 行
│ │ └───── Height 上方填充 0 行
│ └──────── Width 右侧填充 1 列 ← 角度维度
└─────────── Width 左侧填充 1 列← 角度维度给个形象一点的示例,特征被抻成矩形后,在-π和+π两个位置循环pad1列:
原始 8 列(角度从左到右):
Col: 0 1 2 3 4 5 6 7
[A][B][C][D][E][F][G][H] ← φ∈[-π, π]
循环填充后:
Col: -1 0 1 2 3 4 5 6 7 8
[H][A][B][C][D][E][F][G][H][A]
└右端 └─────────────────┘ └左端
环绕到左 原始 8 列数据 环绕到右
含义:
- 左侧填充 [H] ← 这是原来最右边的值(φ=π),在角度上与φ=-π相邻
- 右侧填充 [A] ← 这是原来最左边的值(φ=-π),在角度上与φ=π相邻然后径向方向正常Zero-padding即可,因为这个方向不存在连续性。
Ring Convolution本身就是普通卷积Kernel,只是在Padding的方式比较特殊。
经过U-Net处理后,对每个极坐标网格进行类别预测。正如之前提到的,Polar的网格划分方式,让一个网格内的属于同一语义的概率大大提高,因此可以在避免Point-Level上采样解码的情况下保证分割精度。
PolarBEV
地平线提出的范式。单模态的相机数据作为输入。
虽然数据模态变成了图像,但是在极坐标系中表征仍然有优势,图像近大远小透视原理可以让Polar Grid在近距离获取到更多的特征,ego为中心的射线和Polar Grid的边界天然贴合等内容在本文PolarNet中介绍过了,不过多赘述。
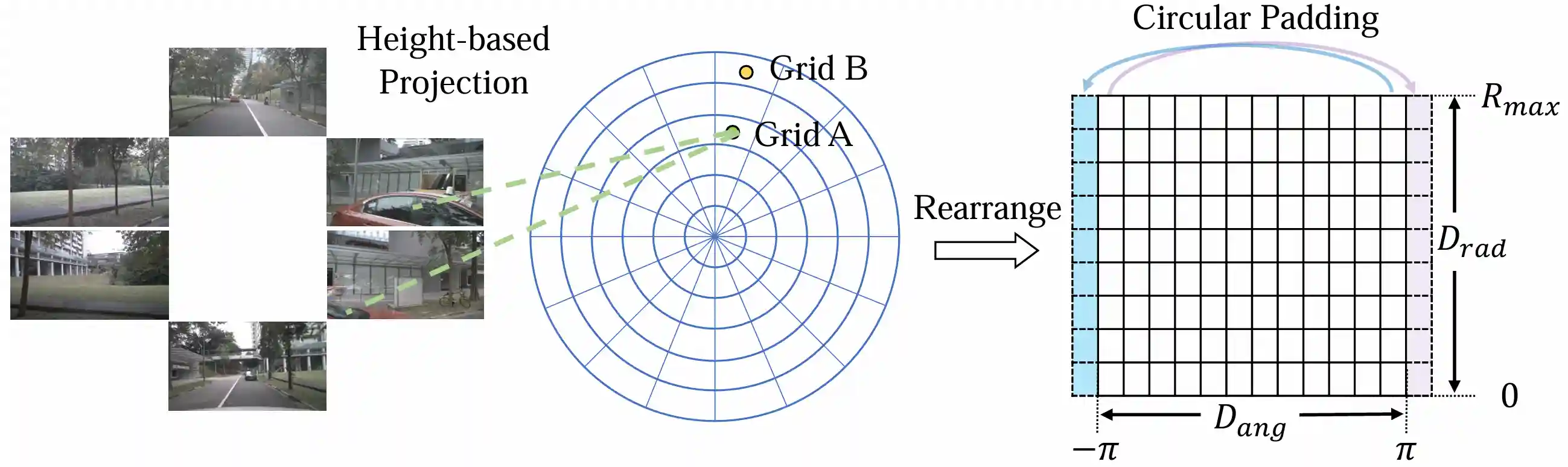
Rearrangement
首先是将BEV空间沿角度和半径方向栅格化,其中角度方向均匀划分,径向不等分。
然后通过Ring Conv & Circular Padding处理角度周期性连接问题,将栅格化的特征重组成矩形特征图,方面后面直接用2D卷积核。
看起来与PolarNet别无二致,但是由于数据模态不同,LiDAR自带的3D坐标可以直接被分配到Polar BEV Grid中,但是相机2D图像的特征需要先进行Lift操作才可以被分配到Polar BEV Grid中。
Polar Embedding Decomposition
极坐标表示存在两个关键特性:
径向特性:相同距离的极坐标网格对应相同的尺度
这意味着在径向上,距离相同的点具有相似的视觉尺度
例如:距离传感器10米处的所有点,无论角度如何,都具有相同的相对大小
角度特性:相同角度的网格对应相同的相机视角
这意味着在角度上,相同方向的所有点共享相同的视角特性
例如:正前方的所有点,无论远近,都来自同一视角方向
因此论文对每个Polar Grid,预定义一个可学习的查询嵌入(Learnable Query Embedding)。然后将这个嵌入分解(Decompose)成2个部分:
:半径特定查询
:角度特定查询
最终这个可学习的查询嵌入被整合并定义为:
通过对查询的分解和整合,网络能学习到不同距离下的尺度变化和空间网格之间的关联,增强 BEV 特征表达能力。
Iterative Surface Estimation
Lift的过程并未使用类似 LSS 的路线,而是采用基于几何对齐的逆向映射方法。具体实现机制为迭代表面估计(Iterative Surface Estimation)。
初始化假设平面 Hypothetical Plane,先假设车辆周围是一个绝对平坦的地面,对于 Polar BEV Grid 中的每个网格,初始高度为0。Grid 的结构和 PolarNet 是一样的。
因为外部地面肯定不平坦,Net利用公式来迭代更新网格的高度,目的是通过查询嵌入引导高度更新,使BEV表面更符合真实场景几何结构:
:当前迭代网格的高度
:MLP
:上一次迭代的查询嵌入
:上一次迭代的高度值
这是一个残差更新过程,模型预测的是高度变化量,而非直接预测高度,将高度变化量加到上一次迭代的高度上,得到当前迭代网格的高度。
然后进行高度归一化:
然后从极坐标转到笛卡尔坐标系:
然后构建齐次坐标并求解像素坐标:
其中⊕为concatenate操作,相当于构造了一个的4维向量,也就是相机坐标系中常说的齐次坐标。
然后将投影到图像平面:
其中和分别是第n个视角相机的内、外参。为网格在第n个视角上的投影点。
然后进行特征转换,公式实际上是特征聚合过程,隐去了特征采样的操作。
此时CNN早就从6个视角的相机中提取完了2D特征,然后用即像素坐标从相应位置的图像特征图中提取特征,得到
:BEV视角下第个网格的特征,如果一个3D点同时落在2个相机视角中,那就把他们特征加起来。
:二进制掩码,因为一个3D点不可能被所有相机同时看到,这里用二进制掩码的0/1判断3D点的可见性。
:投影点对应的图像特征。
Head
基于FIERY《FIERY: Future Instance Prediction in Bird's-Eye View from Surround Monocular Cameras》论文中的头,Loss Function也相同。
使用一个Encoder-Decoder网络来细化BEV特征,接3个分支:
Seg Score:分割类别的概率图
Offset:为每个像素指出从当前位置指向其实例中心的Offset
Centerness:预测每个像素是其所属实例中心的概率
self.segmentation_head = nn.Sequential(
nn.Conv2d(shared_out_channels, shared_out_channels, kernel_size=3, padding=(0, 1), bias=False),
nn.BatchNorm2d(shared_out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(shared_out_channels, n_classes, kernel_size=1, padding=0),
)
self.instance_offset_head = nn.Sequential(
nn.Conv2d(shared_out_channels, shared_out_channels, kernel_size=3, padding=(0, 1), bias=False),
nn.BatchNorm2d(shared_out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(shared_out_channels, 2, kernel_size=1, padding=0),
)
self.instance_center_head = nn.Sequential(
nn.Conv2d(shared_out_channels, shared_out_channels, kernel_size=3, padding=(0, 1), bias=False),
nn.BatchNorm2d(shared_out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(shared_out_channels, 1, kernel_size=1, padding=0),
nn.Sigmoid(),
)
self.instance_future_head = nn.Sequential(
nn.Conv2d(shared_out_channels, shared_out_channels, kernel_size=3, padding=(0, 1), bias=False),
nn.BatchNorm2d(shared_out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(shared_out_channels, 2, kernel_size=1, padding=0),
)PolarFormer
将极坐标BEV和Transformer结合的3D目标检测算法(排列组合了属于是)。也是单模态的相机图像作为输入,执行3D检测任务。
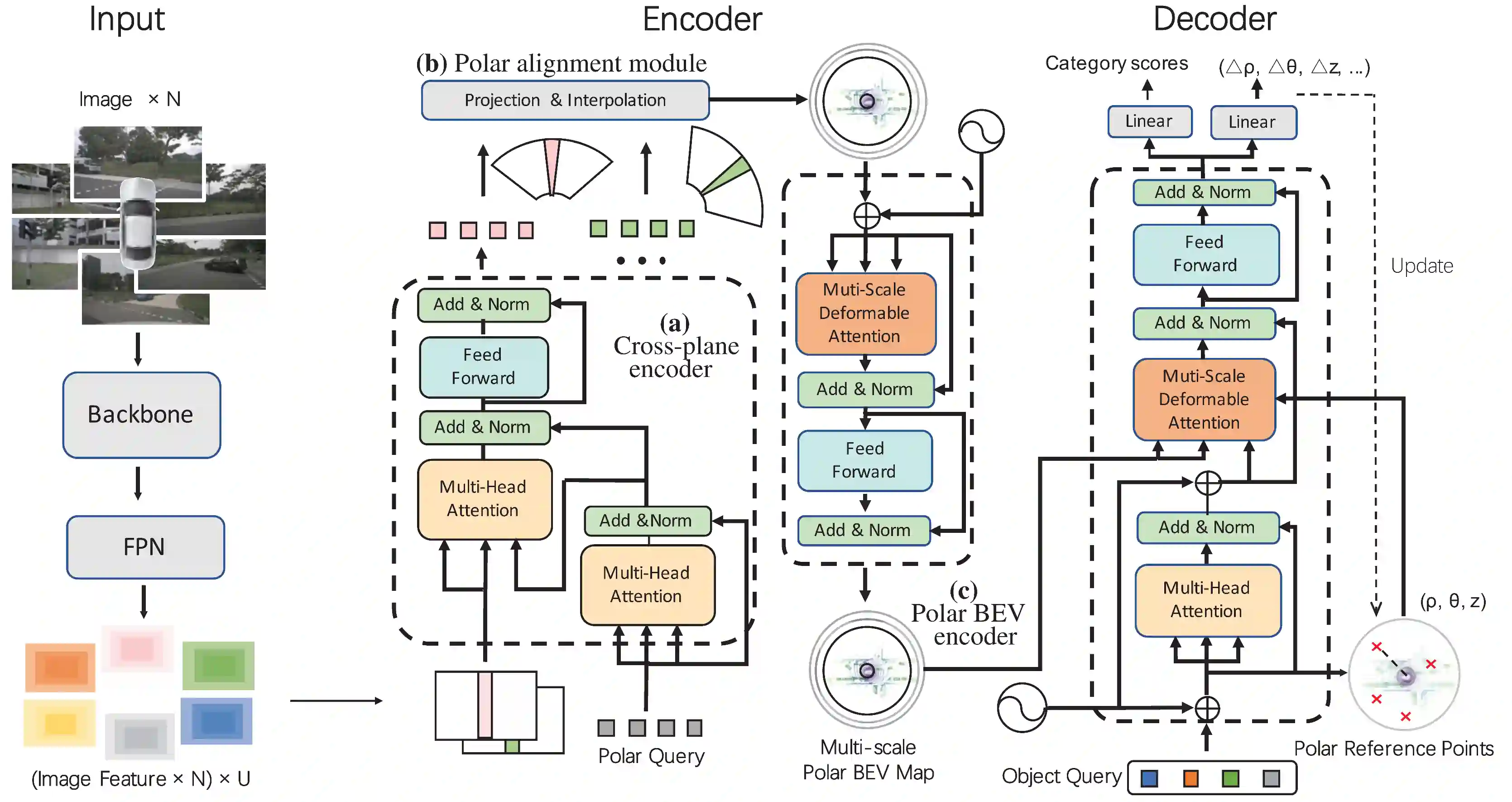
Polar Cross-Attention
几何对齐:因为极坐标的定义(射线和距离)天然与相机的透视成像(视锥体)一致。模型利用相机的内/外参,3D到2D几何投影,计算出每个 Polar Query 在 2D 图像上对应的像素区域。
Sequence-to-Sequence聚合:Polar Query 作为 Transformer 中的 Query,对应的 2D 图像特征作为 Key 和值 Value。通过交叉注意力机制,每个极坐标 Query 只关注并吸收图像上属于自己那片区域的视觉特征。
Multi-scale Polar FPN
在极坐标网格中,靠近相机的网格物理面积非常小,而远离相机的网格物理面积非常大。同样一辆汽车,在近处可能占据几十个网格,在远处可能只占一个网格。为了解决近大远小造成的特征不均衡(Polar BEV 的优势不就是近处特征更多吗?),PolarFormer 设计了一个类似FPN的结构:
在不同的分辨率层级对极坐标特征进行处理。
浅层高分辨率网格负责捕捉远处的微小目标。
深层低分辨率网格负责捕捉近处的大型目标。
Polar Head
极坐标BEV特征构建完成后,用一个Head来预测3D BBox类别,位置(r, p)和WHL和θ。
然后通过最基础的三角函数将3D框从极坐标系转换回笛卡尔坐标系。
参考文章
[4] SuperZ-Liu/PolarBEV: The offical code of PolarBEV (CoRL2022).
[5] [2206.15398] PolarFormer: Multi-camera 3D Object Detection with Polar Transformer
评论