

写在前面(废话,请跳过)
本来自己的脑子里是不存在CUDA编程这个东西的,没错,就是压根儿没听说过。
之所以了解到这个东西,是因为最近开始做AVM (Around View Monitor),或者说SVS (Surrounding View System),利用4个广角相机,实现车辆周围的360°环视功能。
这里面涉及到很多的坐标转换和矩阵乘法,众所周知这些运算是非常耗费资源的,平时1-2个相机通过TensorRT做模型推理还好,大部分工作被GPU做了,留给SLAM、控制等模块的CPU算力勉强还够,但是同时处理4路相机,以我目前用的Jetson Orin AGX的8核ARM CPU来说,留给其他功能的CPU资源已经不多了...
偶然发现一个同学做的环视,使用CUDA加速竟然能达到10000FPS,虽然我用她的代码并不能跑出这么快的速度,但是花里胡哨的CUDA Kernel函数仍然给了我一个小小的震撼,以及大大的精神冲击(为啥我同学啥都会?我咋啥都不会?)。
既然自己也是做视觉感知的,那就开学捏!
并行性
对于一段代码,如果是有执行次序的,那么就必须串行执行;若没有执行次序,那么则可以并发执行。如果一个任务处理的是另一个任务的输出,即这两个任务间存在相关性。相关性是限制并行性的主要因素之一。
程序中有两种基本并行类型:
- 任务并行:多个任务或函数能独立的并行执行,重点在于多核系统对任务的分配。
- 数据并行:指能够同时处理许多数据,重点在于多核系统对数据的分配。
CUDA更适合解决数据并行计算的问题。
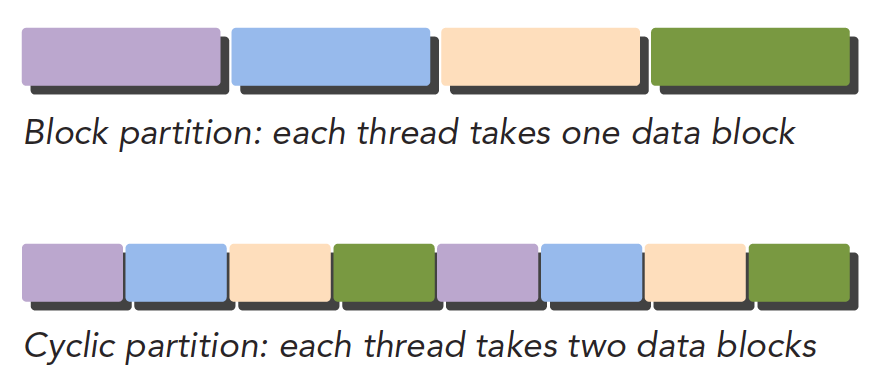
数据并行的第一步是把数据依据线程进行划分。一般使用两种方法:block partitioning 和 cyclic partitioning。
- 块划分:一组连续的数据组成一个数据块,一个线程在同一时间通常只处理一个数据块。数据块以任意次序安排给一个线程。
- 周期划分:一个数据块可能只包含一组连续数据中的一部分,数据块按周期排列,相邻线程处理相邻数据块,每个线程可以处理多个数据块。线程选择一个新块意味着要跳过和现有线程一样多的数据块。
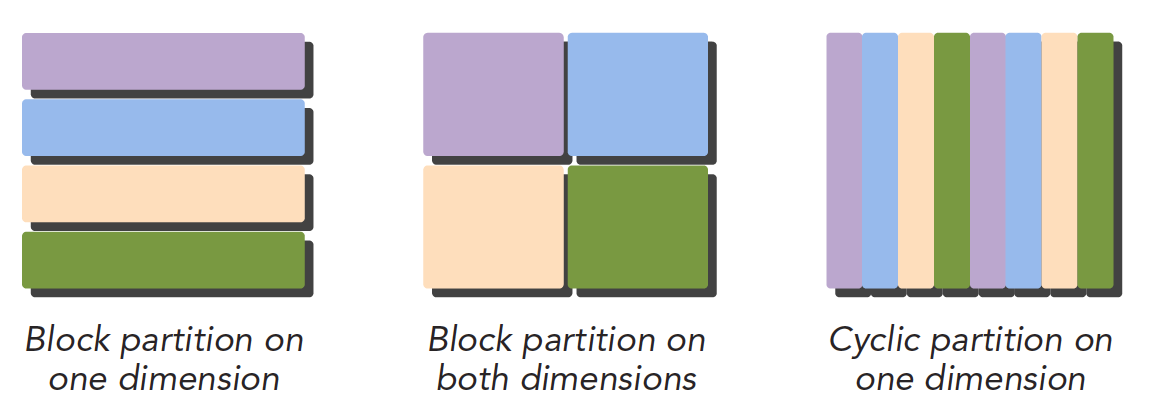
NOTE:实际上数据是在一维空间中存储的。我们熟知的H×W×C的图像,本质上也是一维数据,因此会有HWC和CHW的区别。
程序性能对块的大小比较敏感,数据的划分方式与计算机架构有关。
异构计算
在一个异构计算节点中,GPU不是一个独立运行的平台,而是CPU的协处理器。GPU必须通过PCIe总线和基于CPU的主机进行操作。因此,GPU被称为Device,CPU被称为Host。
一个异构应用程序包含两部分:
- Host 代码:在CPU上运行
- Device 代码:在GPU上运行
描述GPU容量通常用如下指标:
- CUDA Core数量:cuda core中,内部有分别处理int和单精度float的部分,这也是为什么有些GPU只有TOPS而没有TFLOPS。
- Tensor Core数量:专门为深度学习矩阵运算设计。可以单次计算多维Tensor,此外Tensor Core支持的数据类型也更多。
- 内存(显存)大小:显存在训练模型阶段,主要影响其
Batch_Size,此参数会直接决定你的训练时长。
描述GPU性能通常用如下指标:
- 峰值计算性能:注意区分TOPS, FLOPS和FLOPs。其中OPS指的是每秒处理次数,即形容速度,但通常是默认对INT8整型数的处理次数,加上FL后FLOPS指的是对FP32的处理次数。TOPS即Tera,每秒几万亿次的计算。LOPs指的是深度学习模型自身的计算量,是形容规模的。
- 内存带宽:一般单位GB/s,指从内存中读取/写入数据的速度。
此外,还有一个“计算能力”,即 computer capability,这个看起来也是描述性能的,但是实际上描述的是GPU加速器的硬件版本。
Hello World CUDA版
CUDA源文件的后缀是 .cu,使用 nvcc进行编译。当然这并不是意味着 cmake不能编译它。这个以后再说。
要注意 .cu文件的核函数内部不支持C++的 std::cout,而只能使用C语言函数 printf。另外,核函数内部的日志输出会大幅增加运行时间。因此,调试完毕后需要注释掉。
#include <stdio.h>
__global__ void helloworldFromGPU(void){
printf("Hello world from GPU! \n");
}
int main(void){
printf("Hello world from CPU! \n");
helloworldFromGPU<<<1,10>>>();
cudaDeviceSynchronize();
return 0;
}
在《Professional CUDA C Programming》一书中,使用 cudaDeviceReset()函数而非 cudaDeviceSynchronize()函数。虽然 cudaDeviceReset()也会让所有输出流在程序结束前输出,但所有CUDA上下文 context也会被摧毁,虽然其具有同步数据的功能,但是目前CUDA建议使用 cudaDeviceSynchronize()。
此外,cudaDeviceSynchronize() 可以在程序的任何需要同步的地方调用,而 cudaDeviceReset() 通常只在程序结束时调用一次。
编译命令 nvcc hello.cu -o hello,会生成名为 hello的可执行文件。运行 ./hello即可得到如下结果:
Hello world from GPU!
Hello world from GPU!
Hello world from GPU!
Hello world from GPU!
Hello world from GPU!
Hello world from GPU!
Hello world from GPU!
Hello world from GPU!
Hello world from GPU!
Hello world from GPU!
在NVIDIA官方网站 NVCC Command Options 中,有 nvcc编译选项的全部内容。
参考文章
[1] Segmentfault.com. (2024). Available at: https://segmentfault.com/a/1190000017539415 [Accessed 14 Apr. 2024].
[2] Cheng, J., Grossman, M. and McKercher, T. (2014). Professional CUDA C Programming. John Wiley & Sons.
评论