CUDA编程结构
在GPU上执行的函数称为CUDA核函数(Kernel Function),核函数会被GPU上多个线程执行。典型的CUDA程序遵循如下模式:
- 把数据从CPU内存(HOST)拷贝至GPU内存(DEVICE)
- 调用该Kernel函数,对DEVICE中的数据进行操作
- 将数据从DEVICE传送至HOST
CUDA内存管理
- GPU内存分配:
cudaMalloc
cudaError_t cudaMalloc (void** devPtr, size_t size)
函数返回一个devPtr,指向所分配的内存。
- HOST<->DEVICE数据传输:
cudaMemcpy
cudaError_t cudaMemcpy ( void* dst, const void* src, size_t count, cudaMemcpyKind kind )
函数将src指向的数据,传输至dst,复制方向由kind制定,包含如下4种:
cudaMemcpyHostToHost = 0
Host -> Host
cudaMemcpyHostToDevice = 1
Host -> Device
cudaMemcpyDeviceToHost = 2
Device -> Host
cudaMemcpyDeviceToDevice = 3
Device -> Device
需要注意的是,这个函数是以同步的方式执行,即cudaMemcpy完成操作并返回值前,程序是阻塞的。
此外,除了Kernel启动外的CUDA函数调用均会返回一个错误枚举类型cudaError_t,若GPU内存分配成功返回cudaSuccess,否则返回cudaErrorMemoryAllocation,可以通过cudaGetErrorString(cudaError_t error)得到可读的错误消息。
简单的数据传输示例
nvcc中封装了多种编译工具
#include <stdlib.h>
#include <string.h>
#include <time.h>
// A、B、C都是数组,其本质是指向数组首元素的指针。
// 对于一个数组A,A[i] 等价于 *(A + i) 。
__global__ void sumArrayGPU(float *A, float *B, float *C, const int N){
for(int i = 0;i < N; i++){
C[i] = A[i] + B[i];
}
}
void sumArrayCPU(float *A, float *B, float *C, const int N){
for(int i = 0;i < N; i++){
C[i] = A[i] + B[i];
}
}
void initData(float *ip, int size){
time_t t;
srand((unsigned int) time(&t));
for(int i = 0;i < size;i++){
ip[i] = (float) (rand() &0xFF) / 10.0f;
}
}
int main(int argc, char** argv){
const int N = 1024;
auto memSize = N * sizeof(float);
float *h_A, *h_B, *h_C;
h_A = (float *)malloc(memSize);
h_B = (float *)malloc(memSize);
h_C = (float *)malloc(memSize);
initData(h_A, N);
initData(h_B, N);
sumArrayCPU(h_A, h_B, h_C, N);
float *d_A, *d_B, *d_C;
cudaMalloc((void**) &d_A, memSize);
cudaMalloc((void**) &d_B, memSize);
cudaMalloc((void**) &d_C, memSize);
cudaMemcpy(d_A, h_A, memSize, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, memSize, cudaMemcpyHostToDevice);
sumArrayGPU<<<16,16>>>(d_A, d_B, d_C, N);
cudaMemcpy(h_C, d_C, memSize, cudaMemcpyDeviceToHost);
free(h_A);
free(h_B);
free(h_C);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
return 0;
}
线程管理
由一个Kernel启动所产生的所有线程统称为一个Grid,此Grid中所有线程共享全局内存。
一个Grid中包含多个Block,一个Block又包含多个Thread。不同Block内的Thread不能协作。
不同Thread使用blockIdx和threadIdx来互相区分,这两个变量是CUDA的内置变量,为unit3类型,即包含3个uint的结构,可以使用x y z三个字段进行指定。比如blockIdx.x 、threadIdx.y
Grid和Block的维度依靠dim3类型的gridDim和blockDim来指定,这种类型的数据也可以通过x y z来获得。
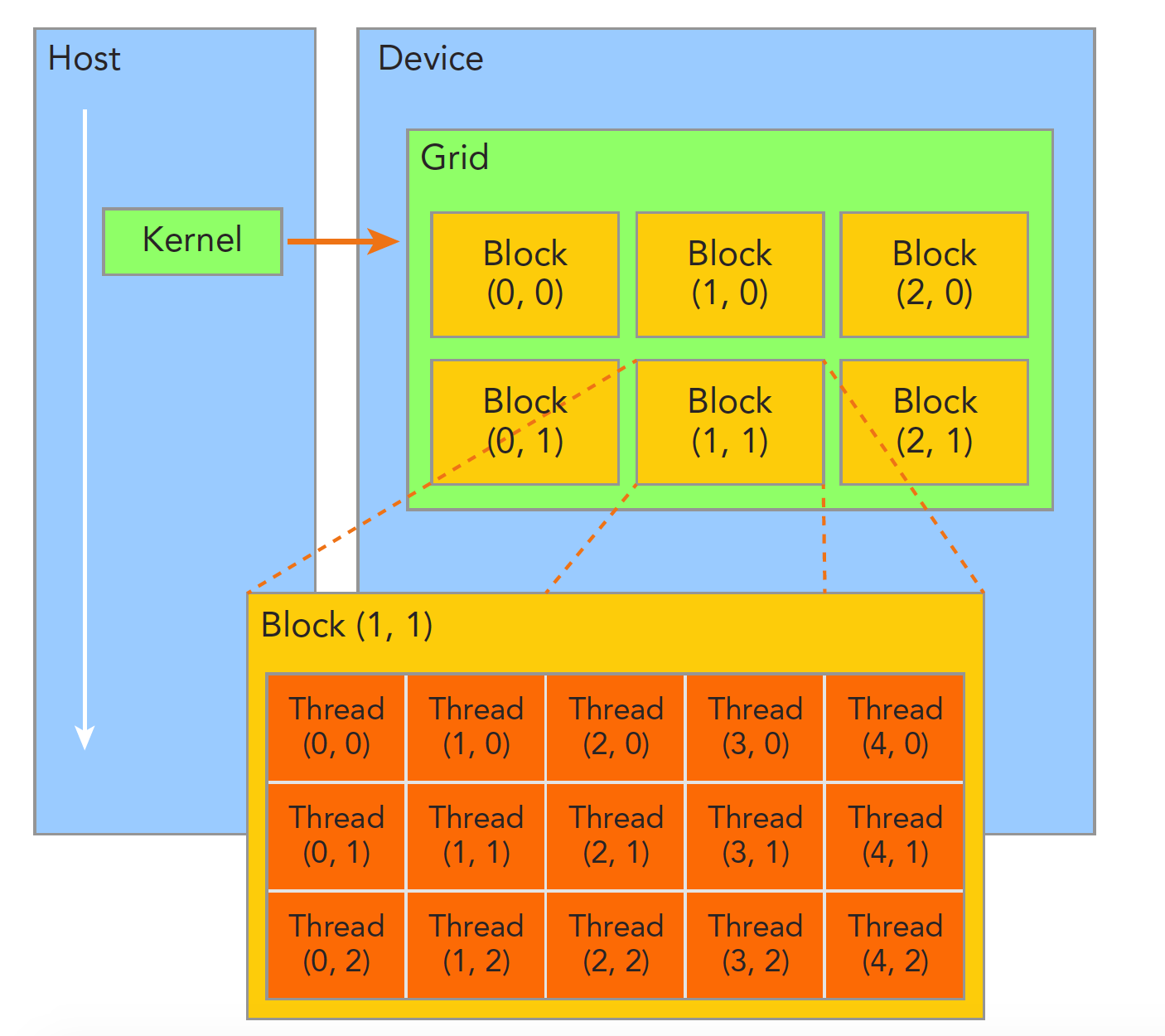
在一段.cu程序中,会定义两组这种变量。一个是在Host中定义的dim3类型的Grid和Block,该变量仅在Host中可见。另一个是在Kernel函数中定义的uint3类型,尽在Device端可见。下面代码中会看到这两种变量定义位置的区别。
#include <cuda_runtime.h>
#include <stdio.h>
__global__ void checkDim(){
//内置的预初始化Thread和Grid变量,仅在Device访问
printf("threadIdx:(%d,%d,%d) blockIdx:(%d,%d,%d) blockDim:(%d,%d,%d)"
"gridDim:(%d,%d,%d) \n" ,threadIdx.x, threadIdx.y, threadIdx.z, blockIdx.x, blockIdx.y, blockIdx.z,
blockDim.x ,blockDim.y, blockDim.z, gridDim.x, gridDim.y, gridDim.z);
}
int main(int argc, char** argv){
const int nElem = 6;
//手动定义的dim3类型的Grid和Block Size,仅在Host访问
dim3 block(3);
dim3 grid((nElem + block.x -1) / block.x);
printf("grid.x %d grid.y %d grid.z %d \n" ,grid.x, grid.y , grid.z);
printf("block.x %d block.y %d block.z %d \n" ,block.x, block.y , block.z);
checkDim<<<grid,block>>>();
cudaDeviceSynchronize();
return 0;
}
在 dim3 grid((nElem + block.x -1) / block.x);处, +block.x -1的原因很多人可能不懂,这是为了避免最后一个块不能完全包含一个Block。比如当nElem=10,block.x=3,若不这样处理,6/3 = 3,3个Block,每个Block包含3个Thread,这样一共处理9个任务,相比10,少了1个;通过 +block.x -1,(10+3-1)/3 = 4,多出1个Block来处理第10个任务。简单来说,就是向上取整。
调用Kernel函数
Kernel_Function<<<grid,block>>>(argument list);
<<<grid,block>>>中便是kernel函数的执行配置。
假设有4个block,每个block中又有8个thread,那么核函数为Kernel_Function<<<4,8>>>(argument list);

由上图也能看出,数据在全局内存中是线性存储的,所以可以通过blockIdx和threadIdx获取一个线程的唯一ID,同时建立线程和数据元素间的映射关系。一般情况下,可以通过1维Grid和Block来计算全局数据访问的唯一索引:int i = blockIdx.x * blockDim.x + threadIdx.x
Kernel函数的调用与Host的线程是异步的,需要调用下面函数来强制Host等待所有kernel函数执行结束:
cudaError_t cudaDeviceSynchronize(void);
此外,cudaMemcpy()隐式地包含同步功能,当调用cudaMemcpy在Host和Device进行拷贝时,Host线程将等待cudaMemcpy操作执行完毕才会继续执行程序。
Kernel函数限定符
先提一嘴,Kernel函数必须是void返回类型。
有三种限定符:
__global__Host调用,Device执行__device__Device调用,Device执行__host__Host调用,Host执行(可省略)
当__device__ 和 __host__ 一起使用时,函数可以同时在Host和Device上编译。
Kernel函数和C函数的区别
__global__ void sumArrayGPU(float *A, float *B, float *C, const int N){
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
从上面这段代码可以看出,for循环消失了。因为内置的thread坐标替代了原本的数组索引。
错误处理宏
#define CHECK(call)
{
const cudaError_t error = call;
if (error != cudaSuccess)
{
printf("Error: %s:%d, ", __FILE__, __LINE__);
printf("code:%d, reason: %s\n", error, cudaGetErrorString(error));
exit(1);
}
}
CHECK(cudaMemcpy(d_A, h_A, memSize, cudaMemcpyHostToDevice));如果产生错误会报告一个错误代码,并通过cudaGetErrorString(error)输出可读信息。
并行线程
由于矩阵用行优先的方式在全局内存中进行存储,对一个给定的线程,可以通过Thread和Block索引映射到矩阵坐标上:
ix = threadIdx.x + blockIdx.x * blockDim.x
iy = threadIdx.y +blockIdx.y * blockDim.y
然后将矩阵坐标映射到全局内存的索引上:
idx = iy * nx +ix
矩阵求和 - 2D Grid & 2D Block
使用2D Grid 和 2D Block 计算矩阵加法的代码如下:
#include "common.h"
void SumMatCPU(float *A, float *B, float *C, const int nx, const int ny){
float *ia = A;
float *ib = B;
float *ic = C;
for(int iy = 0; iy < ny; iy++){
for(int ix = 0; ix < nx; ix++){
ic[ix] = ia[ix] + ib[ix];
}
ia += nx;
ib += nx;
ic += nx;
}
}
__global__ void SumMatGPU2D(float *matA, float *matB, float * matC, int nx, int ny){
unsigned int ix = threadIdx.x + blockDim.x * blockIdx.x;
unsigned int iy = threadIdx.y + blockDim.y * blockIdx.y;
unsigned int idx = ix + iy * nx;
if(ix < nx && iy < ny){
matC[idx] = matA[idx] + matB[idx];
}
}
int main(int argv, char** argc){
int dev = 0;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp,dev));
printf("Using Device %d : %s \n" , dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
int nx = 1<<14; // 1<<14 16384; 1<<16 65535
int ny = 1<<14;
int nxy = nx * ny;
int memSize = nxy * sizeof(float);
printf("Matrix size : %d, %d\n", nx ,ny);
//Malloc host mem
float *h_A, *h_B, *hostRef , * gpuRef;
h_A = (float *)malloc(memSize);
h_B = (float *)malloc(memSize);
hostRef = (float *)malloc(memSize);
gpuRef = (float *)malloc(memSize);
double start = seconds();
initData(h_A, nxy);
initData(h_B, nxy);
double epls = seconds() - start;
printf("Init Data eplased time: %f \n", epls);
memset(hostRef,0,memSize);
memset(gpuRef,0,memSize);
start = seconds();
SumMatCPU(h_A, h_B, hostRef, nx, ny);
epls = seconds() - start;
printf("Sum Mat on CPU cost : %f \n", epls);
float *d_MatA, *d_MatB, *d_MatC;
CHECK(cudaMalloc((void**)&d_MatA,memSize));
CHECK(cudaMalloc((void**)&d_MatB,memSize));
CHECK(cudaMalloc((void**)&d_MatC,memSize));
cudaMemcpy(d_MatA, h_A, memSize, cudaMemcpyHostToDevice);
cudaMemcpy(d_MatB, h_B, memSize, cudaMemcpyHostToDevice);
int dimX = 32;
int dimY = 32;
dim3 block (dimX, dimY);
dim3 grid ((nx + block.x -1) / block.x , (ny + block.y -1) / block.y);
start = seconds();
SumMatGPU2D<<<grid, block>>>(d_MatA, d_MatB, d_MatC, nx, ny);
cudaDeviceSynchronize();
epls = seconds() - start;
printf("SumMatGPU2D cost time : %f \n", epls);
CHECK(cudaGetLastError());
CHECK(cudaMemcpy(gpuRef, d_MatC, memSize, cudaMemcpyDeviceToHost));
checkResult(hostRef, gpuRef, nxy);
cudaFree(d_MatA);
cudaFree(d_MatB);
cudaFree(d_MatC);
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
cudaDeviceReset();
return 0;
}
矩阵求和 - 1D Grid & 1D Block
对于一个Size为(nx,ny)的矩阵,使用1维的Grid和1维的Block意味着每个Thread要处理ny个数据,相比上面2D Grid和2D Block的情况,全局索引映射会有很大不同。由于只有threadIdx.x有用,因此还需要一个for循环来处理每个线程中ny元素:
__global__ void sumMatrixOnGPU1D(float *MatA, float *MatB, float *MatC, int nx, int ny){
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
if (ix < nx ){
for (int iy = 0; iy < ny; iy++){
int idx = iy * nx + ix;
MatC[idx] = MatA[idx] + MatB[idx];
}
}
}
矩阵求和 - 2D Grid & 1D Block
在这种情况下,可知threadIdx.y = 0即数据都在第0行,且blockDim.y = 1即1维Block,因此Kernel函数可写为:
// grid 2D block 1D
__global__ void sumMatrixOnGPUMix(float *MatA, float *MatB, float *MatC, int nx, int ny){
unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;
unsigned int iy = blockIdx.y;
unsigned int idx = iy * nx + ix;
if (ix < nx && iy < ny)
MatC[idx] = MatA[idx] + MatB[idx];
}
参考文章
[1] NVIDIA 技术博客. (2022). CUDA 编程手册系列第二章: CUDA 编程模型概述. [online] Available at: https://developer.nvidia.com/zh-cn/blog/cuda-model-intro-cn/ [Accessed 14 Apr. 2024].
[2]docs.nvidia.com. (n.d.). CUDA Runtime API :: CUDA Toolkit Documentation. [online] Available at: https://docs.nvidia.com/cuda/cuda-runtime-api [Accessed 14 Apr. 2024].