

写在前面
YOLOv8 是 Ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本,目前支持目标检测,目标分割,物体分类和姿态估计。
很多YOLO介绍blog会附上下面的结构图,虽然99%的人不会去看,而且我也是那99%的其中一员,不过为显专业(啊这该死的虚荣心),我也附上。。。
相比之前的模型,YOLOv8引入了一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。
模型的训练 - Ultralytics
最开始我是使用这个框架训练,因为此框架非常简单,不过他输出的Binding我实在是看不明白...因此介绍完这种方法,我会介绍一下mmyolo框架下的模型训练,并且使用C++部署也会使用mmyolo训练的模型,在此十分感谢清华孙博士提供的帮助(虽然他100%看不到这篇blog。
已训练好的模型可以从 https://github.com/ultralytics/assets/releases 处下载。
YOLOv8的训练非常简单,首先新建一个conda环境,Python>=3.8。激活环境后运行
pip install ultralytics
会安装好ultralytics,其中包含了YOLOv8所有相关依赖。
之后clone ultralytics的仓库(可选),里面包含了一些yaml文件可能会用到:https://github.com/ultralytics/ultralytics
你的数据集
如果想要根据自己需求训练数据集,想必你已经采集好了数据集并做好了相应标注。
我的模型任务,是检测道路上的红绿灯,截至目前已经采集了800+照片,最终的数据集规模大概在3000+。为了提高模型泛化能力,在多个场景下采集红绿灯图像,包含白天晴天、白天阴天、白天雨天、白天雾天、夜间晴天、夜间雨天、夜间雾天和凌晨等,不过因为对场景要求太多((;´༎ຶД༎ຶ)对不起!我的实习生朋友们),数据还没有采集完,不过这不影响我先训着...
首先将已有数据集划分为训练集和测试集,按7:3或者8:2的比例划分。文件夹的结构如下:
.
├── images
│ ├── train
│ │ ├── Image100.jpg
│ └── val
│ ├── Image601.jpg
└── labels
├── train
│ ├── Image100.txt
├── val
│ ├── Image601.txt
数据集路径和具体分类任务信息,需要写入一个 .yaml文件:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /home/funnywii/Documents/tsariDataset # dataset root dir
train: images/train # train images (relative to 'path')
val: images/val # val images (relative to 'path')
test: # test images (optional)
# Classes
nc: 10 # number of classes
names:
0: green straight
1: red straight
2: yellow straight
3: green left
4: red left
5: yellow left
6: green right
7: red right
8: yellow right
9: unknown
之后即可开始训练,Python代码如下,train函数中,更多的 hyperparameters 和 configurations 可以在 https://docs.ultralytics.com/usage/cfg/#train 中找到。
from ultralytics import YOLO
# Load a model
model = YOLO('../models/yolov8x.pt') # load a pretrained model (recommended for training)
# Train the model
model.train(data='../test.yaml', epochs=100, imgsz=640,batch=4)
# Evaluate the model's performance on the validation set
model.val() # It'll automatically evaluate the data you trained.
报错
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 48.00 MiB (GPU 0; 7.75 GiB total capacity; 6.70 GiB already allocated; 40.06 MiB free; 6.77 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
原因在于你滴模型太大辣,而你滴显存太小辣,可以看到我使用的pretrained模型是v8x,也就是最大那一个,这时候设置 batch = 4一般能解决。
C++部署
本部署基于mmyolo训练得到的模型,模型格式为 .engine。具体转换参考之前的文章。
首先新建一个 detector.h和 detector.cpp文件。
在头文件中,我们先声明一个关于Bounding Box的结构体,用于存放BBox相关的内容:
typedef struct Bbox
{
int x1;
int y1;
int x2;
int y2;
float score;
int label;
}Bbox;
根据由mmyolo得到的模型,使用NETRON查看可以看出模型binding输出4个内容,包括类别、目标数量、bbox 和 置信度:
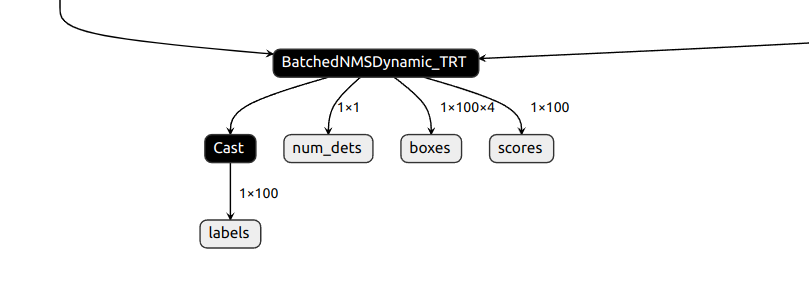
一般来说,TensorRT推理模型的流程为:
- 使用TensorRT的Builder API来创建和优化模型引擎。
- 序列化优化后的模型引擎到磁盘,或者从磁盘加载模型引擎到内存中。
- 创建TensorRT运行时对象(IRuntime)。
- 使用TensorRT运行时对象创建执行上下文(IExecutionContext)。
- 为模型输入和输出分配内存。
- 执行推理。
在检测相关的 Class Detector中,要新建几个变量来保存Engine模型的输出。
class Detector{
private:
// build engine
static const int INPUT_C = 3; // Channels
static const int INPUT_H = 640; // Height
static const int INPUT_W = 640; // Width
static const int OUTPUT_LABEL_SIZE = 100; // Output tensor - max label num
static const int OUTPUT_SCORE_SIZE = 100; //
static const int OUTPUT_BOX_SIZE = 100 * 4; //
static const int OUTPUT_NUM_SIZE = 1; //
const char* INPUT_BLOB_NAME = "images"; // The input name of Engine, can be seen in NETRON
const char* OUTPUT_SCORE_BLOB_NAME = "scores"; // The output name 1-4
const char* OUTPUT_LABEL_BLOB_NAME = "labels";
const char* OUTPUT_BOX_BLOB_NAME = "boxes";
const char* OUTPUT_NUM_BLOB_NAME = "num_dets";
Logger gLogger; // An instance of the Logger class, which is used for logging messages during building and inferencing of the TensorRT engine.
string engineFile = "../models/best0713.engine"; // Engine Path
// inference
vector<float> processedImg = vector<float> (INPUT_C * INPUT_H * INPUT_W);
// Ptr of below Class. This ptr can touch & modify the var and fun.
IRuntime *runtime; // 创建、管理和执行TensorRT的推理引擎
ICudaEngine *engine; // TensorRT优化后的模型Engine from Builder API
IExecutionContext *context; // TensorRT模型Engine的执行上下文, 推理之前,需要先创建一个执行上下文,并将输入和输出的内存分配给这个上下文
cudaStream_t stream; // 并行执行CUDA操作的CUDA流 - 它允许在GPU上并行执行多个任务,从而实现异步执行
int inputIndex, outputIndex_box, outputIndex_score, outputIndex_label, outputIndex_num;
void *buffers[5]; // Void arr ptr, hold the I&O tensor during infer
float data[BATCH_SIZE * INPUT_C * INPUT_H * INPUT_W]; // Input IMG
float boxes[BATCH_SIZE * OUTPUT_BOX_SIZE]; // Output BBox
float scores[BATCH_SIZE * OUTPUT_SCORE_SIZE]; // Score
int labels[BATCH_SIZE * OUTPUT_LABEL_SIZE]; // Label(Class)
int num_det[BATCH_SIZE * OUTPUT_NUM_SIZE]; // Num of Det Obj
vector<Bbox> bboxes;
// post process
float thresh = 0.3; // Threshold for Confidence
float iou_thresh = 0.5; // Threshold for NMS IoU
// Visualization IMG size
int VIS_H = 720;
int VIS_W = 1280;
// PALETTE for Traffic Light - Same color with Light
vector<cv::Scalar> PALETTE = {
cv::Scalar (0, 250, 148),
cv::Scalar (255, 48, 48),
cv::Scalar (255, 255, 000),
cv::Scalar (0, 250, 148),
cv::Scalar (255, 48, 48),
cv::Scalar (255, 255, 000),
cv::Scalar (0, 250, 148),
cv::Scalar (255, 48, 48),
cv::Scalar (255, 255, 000),
cv::Scalar (000, 000, 255),
};
// Class names
vector<string> NAMES = {
"green straight", "red straight", "yellow straight", "green left", "red left",
"yellow left", "green right", "red right", "yellow right", "unknown"
};
// Cam calbration
cv::String calibFile = "../src/calib.yaml";
cv::Mat map_x, map_y; // Used in remap fun
// count
Counter counter;
代码中的BLOB(Binary Large Objects)用来表示一个张量(Tensor)或是一组Tensor Data。具体来说,在 Caffe 框架中,BLOB 常用于表示输入数据或神经网络中的中间数据。
对应的在 detector.cpp中,首先初始化了TensorRT的 Logger插件,随后使用 DEVICE=0也就是机器上唯一一张可怜的显卡,来创建了CUDA推理引擎并使用 binary的方式来读取对应的Engine文件(因为Engine是二进制格式文件,读取方式和其他文件有差异)。之后则会根据模型Size开辟一块内存,其指针为 trtModelStream。
然后创建一个 runtime对象,并反序列化(deserialize)引擎。模型从 pt到 engine格式,是一个序列化(serialize)的过程,而使用这个Engine推理则是反过来。
Detector::Detector()
{
cout << "Starting initializing model" << endl;
// Init the TensorRT Plugins
initLibNvInferPlugins(&gLogger, "");
//build tensorrt engine
cudaSetDevice(DEVICE);
char *trtModelStream{nullptr};
size_t size{0};
// Binary mode reading Engine
// Engine is Binary file
std::ifstream file(engineFile, std::ios::binary);
if (file.good())
{
file.seekg(0, file.end); // locate the file tail
size = file.tellg(); // Size(Byte) of Engine
file.seekg(0, file.beg); // locate the file head
trtModelStream = new char[size]; // Allocate RAM = size (Dynamic) space; trtModelStream is the ptr
assert(trtModelStream); // Check the trtModelStream !=nullptr
file.read(trtModelStream, size); // Read the Engine to trtModelStream
file.close(); // release res
}
runtime = createInferRuntime(gLogger); // Create runtime obj
assert(runtime != nullptr);
engine = runtime->deserializeCudaEngine(trtModelStream, size); // de-serialize TensorRT Engine
assert(engine != nullptr);
context = engine->createExecutionContext(); // Create exe context for infer
assert(context != nullptr);
std::cout << engine->getNbBindings() << std::endl; // Obtain Tensor index of I & O
for(int i = 1;i <engine->getNbBindings();i++){
Dims dims = engine->getBindingDimensions(i);
DataType dtype = engine->getBindingDataType(i);
std::string name = engine->getBindingName(i);
if(engine->bindingIsInput(i)){
std::cout <<"Input " << i << name << std::endl;
}
else{
std::cout <<"Output " << i << name <<std::endl;
}
}
assert(engine->getNbBindings() == 5);
inputIndex = engine->getBindingIndex(INPUT_BLOB_NAME);
outputIndex_box = engine->getBindingIndex(OUTPUT_BOX_BLOB_NAME);
outputIndex_score = engine->getBindingIndex(OUTPUT_SCORE_BLOB_NAME);
outputIndex_label = engine->getBindingIndex(OUTPUT_LABEL_BLOB_NAME);
outputIndex_num = engine->getBindingIndex(OUTPUT_NUM_BLOB_NAME);
delete[] trtModelStream;
// Create GPU buffers on device
// cudaMalloc function: allocate RAM on GPU to create buffer for I & O Tensor
CHECK(cudaMalloc(&buffers[inputIndex], BATCH_SIZE * INPUT_C * INPUT_H * INPUT_W * sizeof(float)));
CHECK(cudaMalloc(&buffers[outputIndex_box], BATCH_SIZE * OUTPUT_BOX_SIZE * sizeof(float)));
CHECK(cudaMalloc(&buffers[outputIndex_score], BATCH_SIZE * OUTPUT_SCORE_SIZE * sizeof(float)));
CHECK(cudaMalloc(&buffers[outputIndex_label], BATCH_SIZE * OUTPUT_LABEL_SIZE * sizeof(int)));
CHECK(cudaMalloc(&buffers[outputIndex_num], BATCH_SIZE * OUTPUT_NUM_SIZE * sizeof(int)));
// init calibration
cv::FileStorage fs(calibFile, cv::FileStorage::READ); // The calib yaml
cv::Mat camMatrix, distCoeffs; // intrinsic Mat & Distortion coefficients
cv::Mat R = cv::Mat::eye(3, 3, CV_64F); // 3x3 Identity Mat(float64), here, notes the extrinsic Mat
// read calib yaml
int height, width;
fs["CameraMatrix"] >> camMatrix;
fs["DistortionCoeffs"] >> distCoeffs;
fs["Resolution width"] >> width;
fs["Resolution height"] >> height;
cv::Size sz(width, height); // Output Img size = 1920x1080
}
评论