

机器学习的建模流程
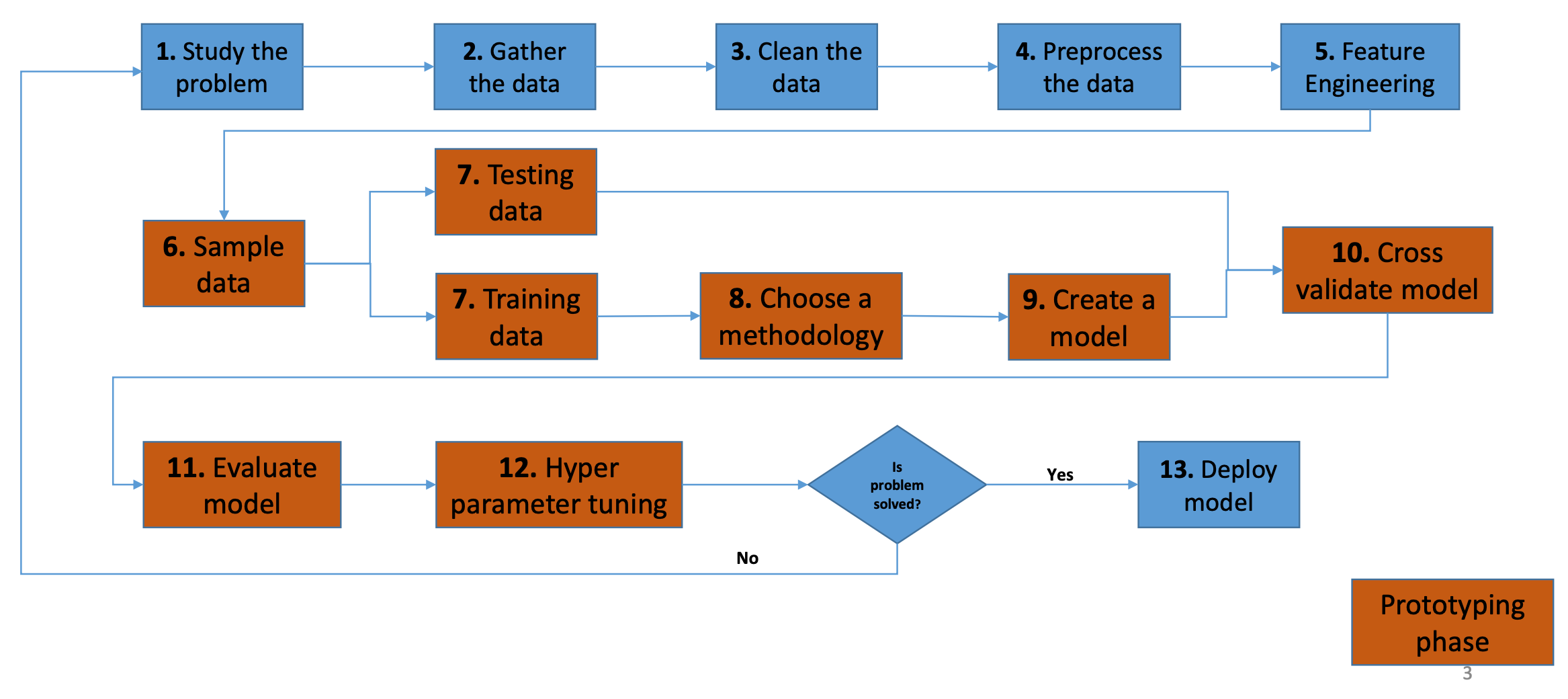
研究问题
采集数据
数据清洗
在采集到的数据中,可能有丢失的,比如NaN或者null,这种数据是不能直接拿来用的。为了解决这个问题,这部分数据会被imputed,具体impute的方法要根据数据的类型来决定。
比如,把缺失的数据替换为某个数值,这个数值可以是平均值,随机值,中值或者是众数。
再比如,有时候把整行或者整列删掉,因为它们会影响模型的预测结果。
预处理数据
不同模型,应用不同算法,需要不同的预处理方式。
比如,SVM和回归,要求数据标准化(均值0,方差1)。
再比如,决策树需要清理掉NaN和null值。
还比如,有些算法可以把数据缩放到0-1的区间(归一化),但是即便归一化了,也要关注离群点。
特征工程
为啥要进行特征工程呢?如果特征太少,那模型就没什么可学的;反之特征太多,就可能存在很多冗余的信息。
特征工程可能把两个或多个特征合并为一个新特征,或者使用某个函数(比如log transform)将特征转换为另一个值。
标签编码
大部分模型要求数据为数字格式,整型或者浮点型。
像日期或字符串,需要被转换为数字类型,此过程被称为标签编码。
One-Hot encoding
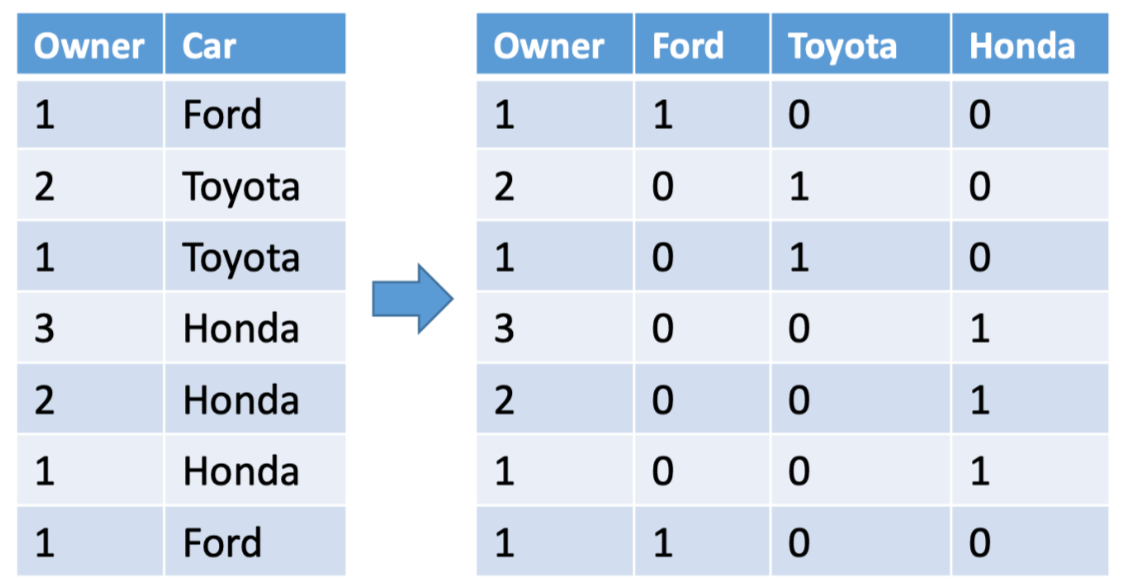
这种方法将一列中的数值分散到多个状态位中,并给它们分配0或1。这些二进制值表达了分组和编码的列之间的关系。
Dummy encoding
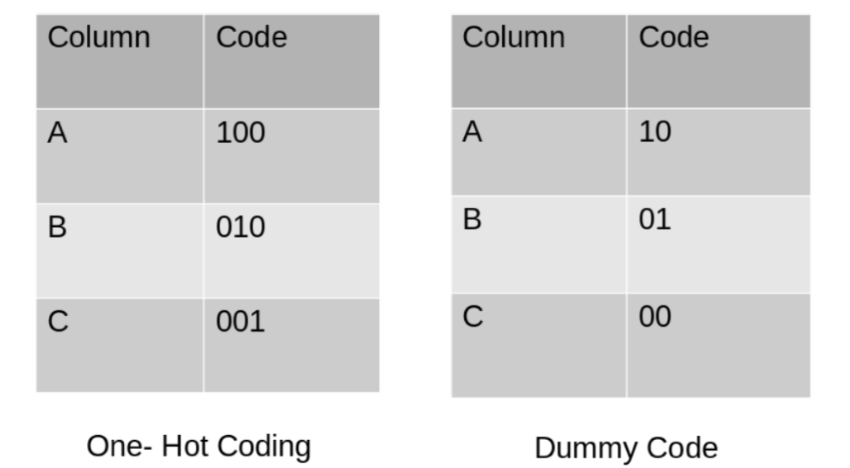
基于数据集的某一特征的N个状态值,用N-1位编码来作区别,Dummy encoding和One-Hot encoding很相似,区别在于最后一个状态位。如果前几位都是0,那么默认最后一位为1。
log变换
如果数据分布是偏斜的,log变换可以让数据更加接近于正态分布,同时,离群值或异常值的影响会变小,模型会更robust。
但是,必须确认模型的数据是正的。
相关性 correlation
当模型的变量之间相互关联时,就会出现多重共线性。但是理想情况下,变量之间应该是独立的,如果变量间的相关性太高,在模型拟合时就会出现问题。
如何解决变量间的高相关性
- 删除一些高度相关的自变量。
- 线性组合自变量,比如把它们加在一起。
- 执行为高度相关的变量设计的分析,如主成分分析(PCA)或偏最小二乘回归。
- LASSO和Ridge回归是回归分析的高级形式,可以处理多共线性。
数据采样
涉及到把数据集分为 训练集和测试集。
- 训练集:用于训练一个机器学习模型
- 测试集:是用来测试和交叉验证训练的机器学习模型
一般两个数据集的比例是7:3或者8:2。
评论