

线性回归
顾名思义,线性回归问题中,输入和输出呈线性关系。
回归被用来估计或解释一个独立变量(y)和一个or更多独立变量(x_i)之间的关系。最基础的回归-线性回归-基于一个线性方程。
假设这个方程为:
此处 y 是一个独立变量,\theta_0 和 \theta_1 是模型的参数,x 是另一个独立变量,也被称为特征。我们的目标就是找到参数 \theta_1 和 \theta_0 的一组值,这组值能最好的拟合训练的数据集。
损失函数 Loss Function
机器学习一般先设计损失函数。损失函数是由真实标签和预测标签的误差来计算损失的值,通过最小化损失函数来训练模型。
其中:
- N为输入数量
- x_1...x_n为输入数据
- y_i为真实标签
- f_\theta(x_i)为预测标签
- \mathcal{L}(y_i,f_\theta(x_i))为单个样本损失函数,用来衡量真实标签和预测标签之间的距离。
单个样本损失函数:
在真实标签与预测标签差距较小的情况下,平方运算可以让损失也保持得较小;当标签差距变大,损失也会被更快得放大。这种损失函数可以让模型忽略已经比较精准得数据,重点关注不准确得数据。
单个样本损失函数带入整体损失函数可以得到均方差MSE(Mean Square Error)的形式:
进一步得到优化目标:
如何找到最优参数 \theta
穷举搜索
测试 \theta 的所有值,找到让误差最小的那组值,如果特征维度较高,计算量爆炸,太费时间。
正规方程 Normal Equation
可以直接计算结果,适用于比较简单的场景。直接求损失函数 J(\theta) 偏导为0的方程组,即 \nabla_{\theta}J(\theta)=0,直接解出 \theta 的值。
换个方式写y = \theta_1 x+ \theta_0:
在这里,h_\theta(X) 是个假设函数,\hat{y} 是估计的目标值。\theta 是模型的参数向量,包括偏差(bias)\theta_0 和特征权重(feature weight)\theta_1 到 \theta_N,X是特征的向量(不是特征向量,是特征的向量)。
经过推导,就能得到Normal Equation:
推导过程网络上很多,比如 机器学习(2)——线性回归(Linear Regression) - 知乎 (zhihu.com)
在Normal Equation中,X为特征的向量,y为实际目标值从 y_1 到 y_m,m 是点的数量。\hat{\theta} 就是可以令cost function最小的那组值。
正规方程法是确定性算法,不需要设置学习率,不需要反复迭代,只需要矩阵运算就可直接求出 \theta。
梯度下降 Gradient Descent
梯度下降法是一种迭代优化算法。梯度的方向就是函数值上升最快的方向,梯度的反方向就是函数值下降最快的方向,所以梯度的正反方向其实是等价的。
梯度下降算法使用预测值和实际值之间的差异来决定下行步骤的速度,差距越大,下行速度越快。当预测值和实际值之间差异消失,cost也就最小,此时的 \theta 也就成为了全局最优解。
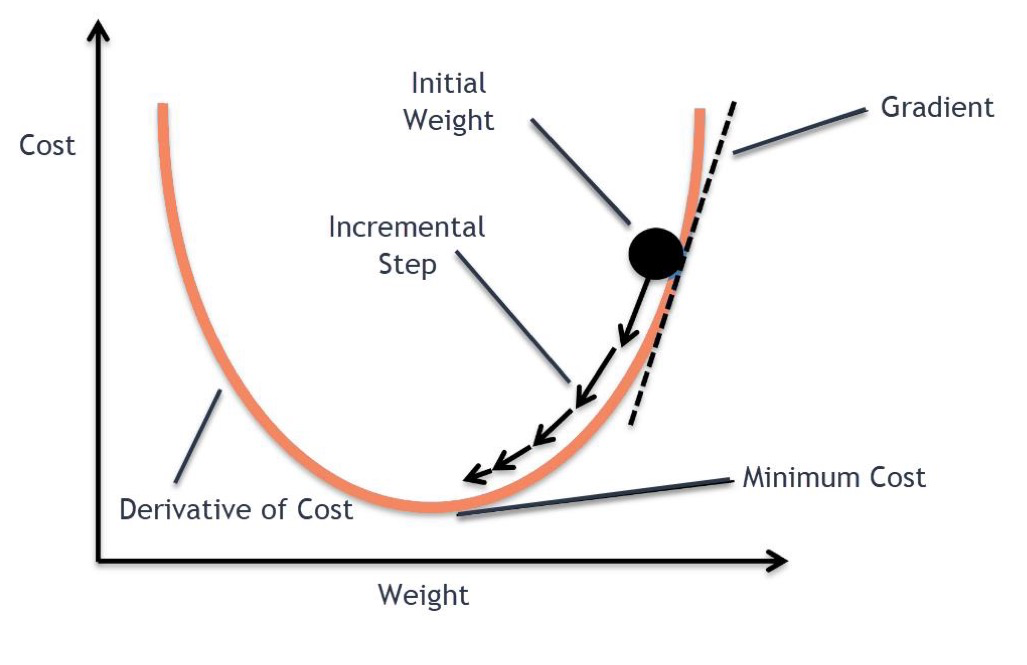
梯度下降的方程为:
\theta根据上述方程更新,\theta的初始值一般是随机的。
\nabla_\theta J(\theta) 代表变化率最大的方向,符号代表是沿梯度的反方向(注意本节开头梯度的定义)移动。\eta 代表学习率,代表在该方向的变化率。通过这两个值来寻找cost function的局部最小值。
学习率是一个超参数(hyperparameter),所谓调参调参,调的就是这些参。。。
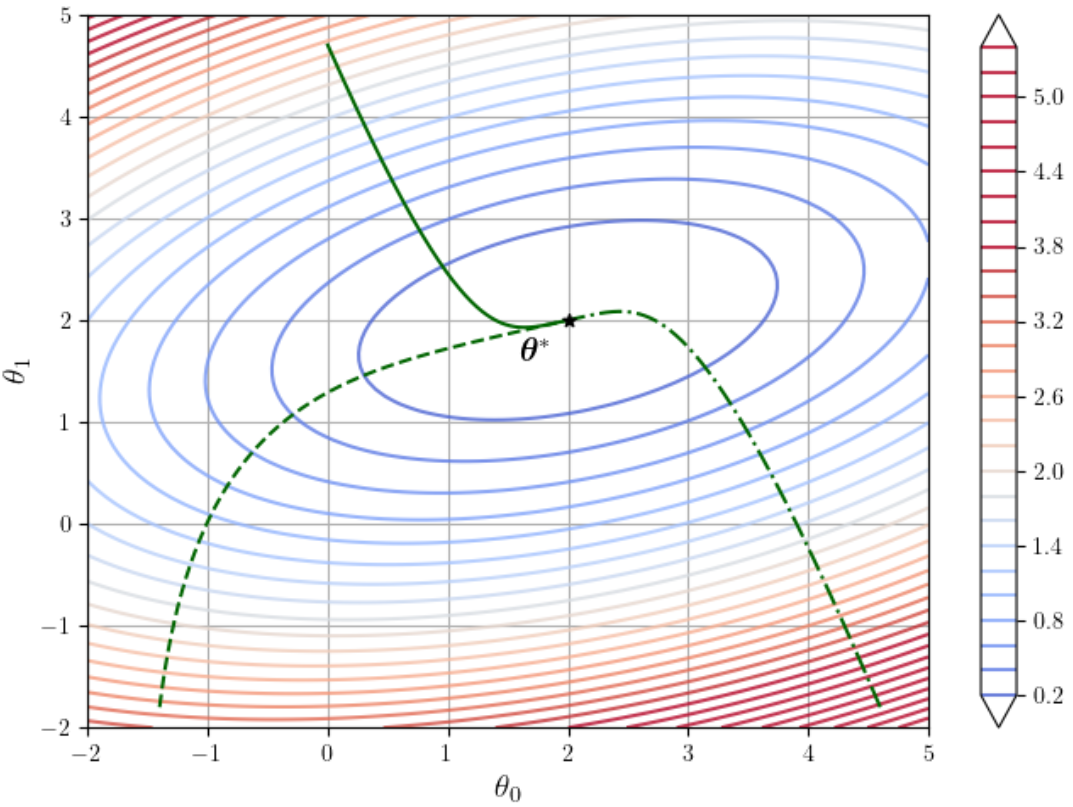
上图是一个梯度下降迭代过程中的损失函数的等值线。估计很多人初学机器学习的时候看不懂这张图。
在这张图中,颜色代表loss大小,颜色越深,loss越小。三条绿线分别代表代表3个不同初值进行梯度下降的过程,最终都收敛到损失函数最小点\theta^*。
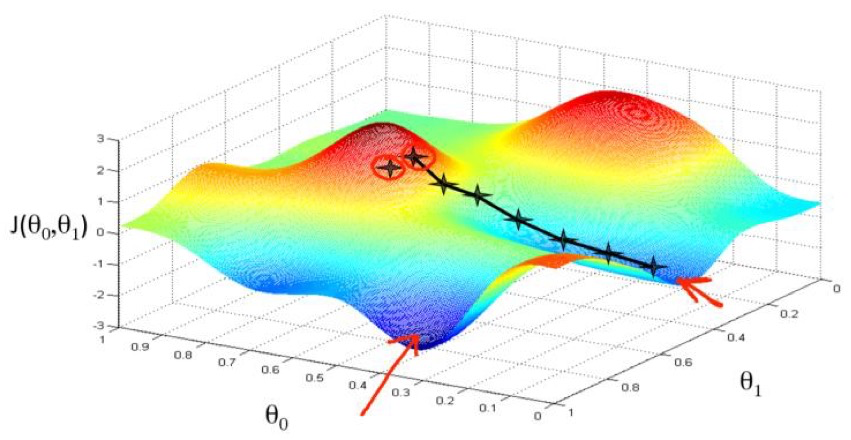
从上面这正三维的图像也可以看出,高维数据的梯度下降也是循着表面的斜率下降的方向一直走,直到找到一个valley。
凸函数
是一类梯度为零时就可以推出极值点的函数。下面公式为凸函数的定义:
最小化凸函数f(x)和最大化凸函数-f(x)是等价的。凸函数在优化问题上一般有简单且理论严格的解法,非凸函数优化则是非常困难的一个研究方向。
因此,在机器学习中,都尽可能找到某种形式的凸函数作为优化问题的目标。
梯度下降的方法
Batch Gradient Descent
会使用数据集中的所有数据N计算MSE和对应梯度。
Batch Size = N
每个epoch进行一次参数 \theta 的更新。
epoch指的是遍历一次所有训练数据
step指的是一次参数更新,如进行一次梯度下降
Stochastic Gradient Descent
相比BGD,这个方法会随机采样单个样本来计算,更适用于超大规模数据集。
Batch Size = 1
每个样本进行一次参数 \theta 的更新。
- Pros: 速度快,内存占用少
- Cons: 收敛波动大,容易绕远
Mini Batch Gradient Descent
Batch Size = Customized
每个mini-batch进行一次参数 \theta 的更新。
可以看出当MBGD的Batch Size=1时,就退化为SGD;当Batch Size = N 就退化为BGD算法。
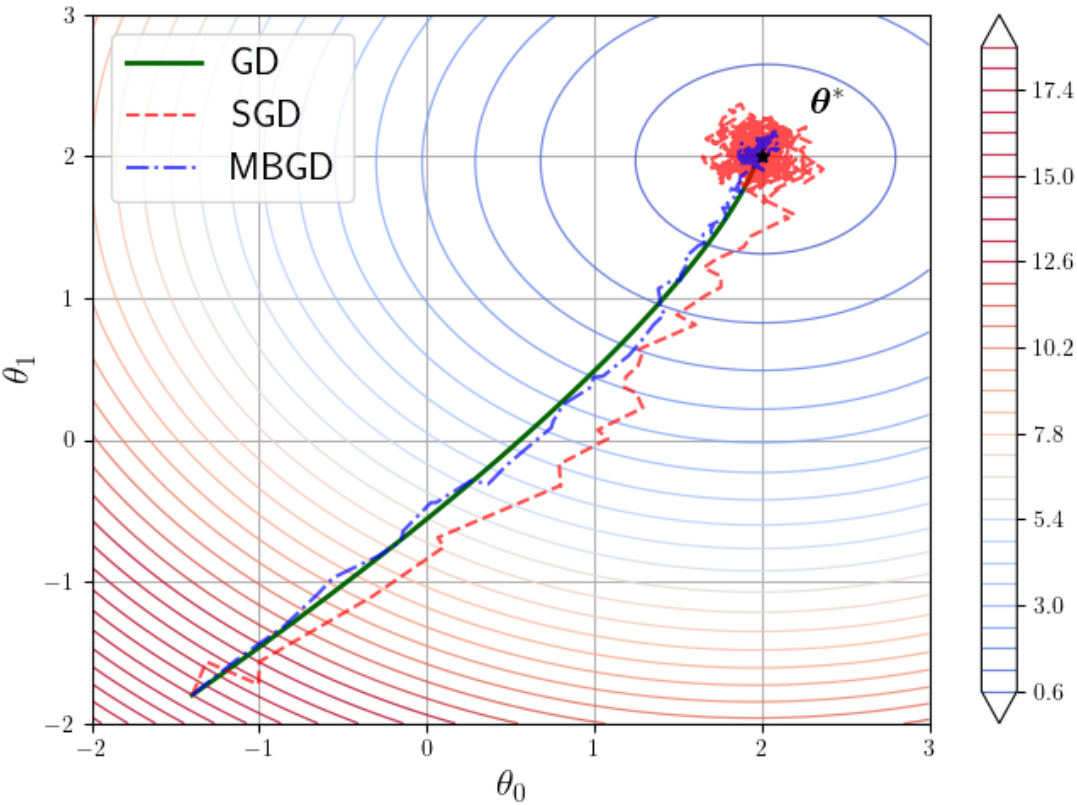
上图可以看出,全样本的BGD每次都能计算出精确的梯度值;MGBD轨迹存在一定震荡,但成功收敛到最优解;SGD震荡更大,在最优解附近疯狂震荡,难以收敛。
因此,虽然算法原理存在差异,但是在现代深度学习中,SDG算法库中使用的实际上就是MBGD。
学习率的影响
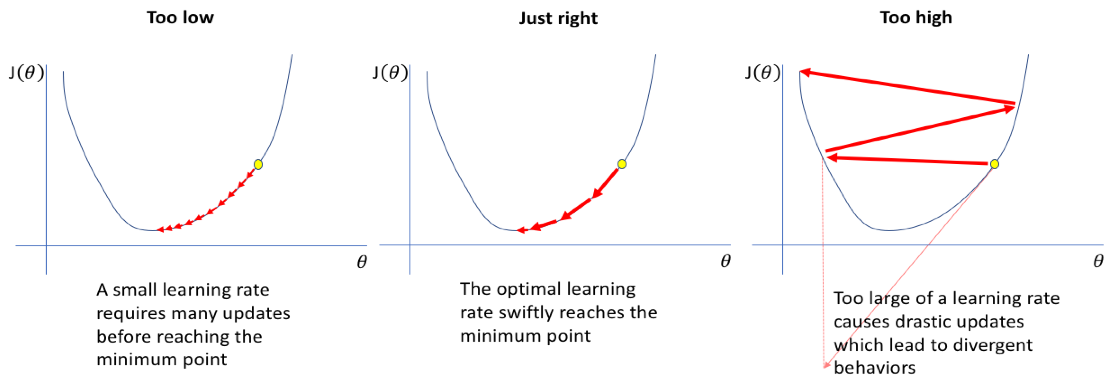
从图5可以看出,如果学习率设定的太小,那么就需要更多次的迭代来到达最小点,如果太大,虽然算法的收敛速度变快,但是可能根本不会收敛。
更高维度的回归
也可以把模型假设为更高阶的模型:
Y是被预测的独立变量,\theta是梯度系数,x_n是n维的特征。
对于2阶和3阶的MSE:
如果在建模时选择的数据维度n太小,可能会导致 underfitting,不能代表整个数据集。
反之,n太大会导致 overfitting。
正规方程法只适用于线性回归,而梯度下降法适用于更高维度的回归。
更多过拟合和欠拟合的知识会在后面的文章中介绍。
Logistic回归
通常来说,回归问题的输出是连续的;而分类问题的输出的是离散的。
Logistic回归就是使用Sigmoid函数,将线性回归的结果归一化至 [0,1] 区间,让输出拥有概率的意义。
Sigmoid 函数并非是一个函数,而是一类S型函数。S型函数有界且可微的实函数,导数恒非负。
Logistic函数
就是一种常见的Sigmoid函数。实践中若不指明,那Sigmoid函数一般默认使用Logistic函数。
Logistic的优化目标
对于概率分布问题,使用最大似然估计(maximum likelihood estimation,MLE)来优化模型。
这种思想是寻找最优参数 \theta 使得预测出正确标签的概率最大。
样本两两独立时,模型将所有样本的分类都预测正确的概率为:
其中:
- L(\theta):似然函数
- x_i:第i个样本的特征向量
- y_i:第i个样本的真实标签
- f_{\boldsymbol{\theta}}(\boldsymbol{x}_i):表示在参数\theta下,模型对第i个样本的预测值,即x_i属于positive的概率
目标就是寻找使 L(\theta) 最大的参数 \theta ,一般将似然取对数,以优化计算速度和简化求导:
那么优化目标就可以变成:
对 l(\theta) 求梯度:
最终可以得到完整的优化目标和迭代公式:
完整推理过程见:逻辑斯谛回归 - 动手学机器学习。此外,模型还加入了一个正则项约束,正则项内容在机器学习 - 正则化和优化器(Regularisation and Optimisers) - FunnyWii's Zone 有介绍。
注意Logistic仅适用于二分类,对于多分类问题,映射函数需要由Logistic函数变为Softmax函数:
其中:
- K代表类别总数,共有K个类别
- 分子z_i代表第i类的原始的得分,加入指数函数后,保证得分值为正,避免原始得分为负导致的负概率问题
- 分母为所有K个类别的指数得分之和
共有K种类别,z 每个维度的取值代表第 j 类的概率。
可以把Softmax理解为Logistic函数在二分类下的一个特例,当 K=2 时,Softmax退化为Logistic函数。
评论