
自 2016 年 YOLOv1 发布至今的十年里,YOLO 的核心版本已一路演进到了 v26——不过这其中包含了一次版本大跳跃:官方为了统一命名规范,直接跳过了 v13 到 v25。
回想起我使用 YOLO 的历程:从只会用官方的 COCO 数据集训练,到使用 MMLab 的各种训练框架,再到自己修改数据集、魔改模型结构,最后进行 TensorRT 的量化部署。一路走来,我竟没有仔细读过 YOLO 的论文,只是一味地用最新版。今天,我决定趁着这几个月集中读论文的契机,把整个 YOLO 系列论文好好读一遍。
YOLOv1 由 YOLO 之父 Joseph Redmon 在 2016 年发布,v1 到 v3 的更新也由他完成。但 2020 年他宣布退出 CV 领域,具体原因不再赘述。2020 年 4 月,YOLO 项目的一名长期开发者 Alexey Bochkovskiy 发表了 YOLOv4 论文,代码被合并到 Joseph Redmon 的官方代码库中,YOLO 就这样传承了下去。
2020 年 6 月,Ultralytics 团队发布了 YOLOv5。这个版本没有发表论文,而是更偏重工程优化:放弃了官方 DarkNet 框架,完全采用 PyTorch 实现,并提供了极易使用的训练、推理和部署方案。自此,YOLO 走向了 Ultralytics 一枝独秀、但仍百花齐放的时代。
2022 年 6 月,中国团队美团发布了 YOLOv6,主打高效工程落地。2022 年 7 月,YOLOv4 的作者 Alexey Bochkovskiy 发布了 YOLOv7。
2023 年,Ultralytics 发布了 YOLOv8,统一了多任务框架,成为应用最广泛的版本——不过依然没有论文。2024 年,YOLOv9 延续了 v4/v7 的学术风格;清华团队提出的 YOLOv10 实现了实时端到端。
同样在 2024 年,Ultralytics 在 YOLOv8 基础上发布了 YOLOv11,属于迭代升级版本,依旧没有论文。
2025 年,YOLOv12 发布,它摒弃了 CNN、拥抱 Transformer,同时尽可能保持实时性。
2026 年,Ultralytics 发布了 YOLO26,为了统一版本名称,采用了年份作为版本号——那明年就是 YOLO27 了?也不知道其他团队是否会跟进这种命名方式。
期间还有大量 YOLO 衍生版本,比如 YOLOX、YOLOR、PP-YOLO 和 FastYOLO 等,本文就不一一介绍了。
YOLOv1
之前类似 R-CNN 的方法都是先使用一个 Region Proposal Network 生成潜在 BBox,然后再对 Proposal BBox 使用分类器,需要单独训练 2 个网络。这类方法被称作 Two-Stage Method。
YOLO 则是直接回归 BBox 和类别置信度,也就是后来的 One-Stage Method。
Method
把画面分成一个 S × S 的 Grid,如果一个物体中心落在某个 Grid 中,那么就由这个 Grid 负责检测这个物体。
每个 Grid 会预测 B(B=2) 个 BBox (x, y, w, h)
- \text{x, y}:BBox 中心点相对于 Grid 左上角的坐标
- \text{w, h}:BBox 相对于整张图像的宽度和高度
以及预测 B 个置信度分数Confidence:
其中 Pr(Object) 代表当前网格中是否存在目标物体的中心:
- 有物体:值为 1,所以 confidence 的监督目标是预测框和 GT 的 IoU
- 无物体:值为 0,所以 confidence 的监督目标就是 0
\text{IOU}_\text{pred}^\text{truth} 表示BBox与真实框的交并比(IOU),范围 [0,1],衡量预测框的位置准确度。
每个 Grid 还预测出 C(C=20) 个类别条件概率 \Pr(\text{Class}_i \mid \text{Object}),条件类别概率在每个 Grid 中仅预测一组,和 B 的数值无关。
注意这个条件类别概率和 BBox 的 Confidence 是独立的两部分,Confidence 反映目标存在概率和定位质量的联合量,当前 Grid 中有目标时,退化为 IoU;条件类别概率是 Grid 中包含某个类别物体的情况下,物体属于 \text{i} 类的概率。
最终的Score分数就是:
这个 Score 同时编码了 BBox 中出现该类物体的概率 和 BBox 与 GT 的 IoU 。
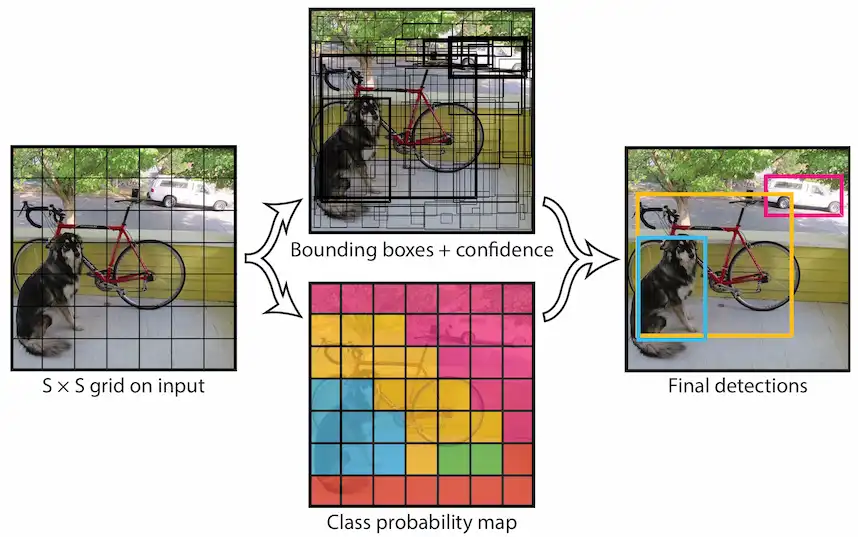
网络最终输出一个 S × S × (B × 5 + C) 维度的 Tensor,把参数带进去就是 7 × 7 × 30 的张量。
7 × 7 的维度上是最终输出特征图的维度,30 这个维度是在描述每个 Grid 中的 2 个 BBox 的 XYWH + Confidence + 20 个类别的条件概率。
输入尺寸为 448 × 448,32 倍下采样后,得到最终 7 × 7 个 Grid,每个 Grid 对应一块 64 × 64 的区域,最多检测 98 个 BBox,最多得到 49 个目标。
Network
网络设计上受GoogLeNet启发,整体结构包含 24个卷积层 + 2个全连接层。
不过论文中的模型结构省略了一部分内容,导致看起来比较费劲,我找到了一个相对正确的版本:
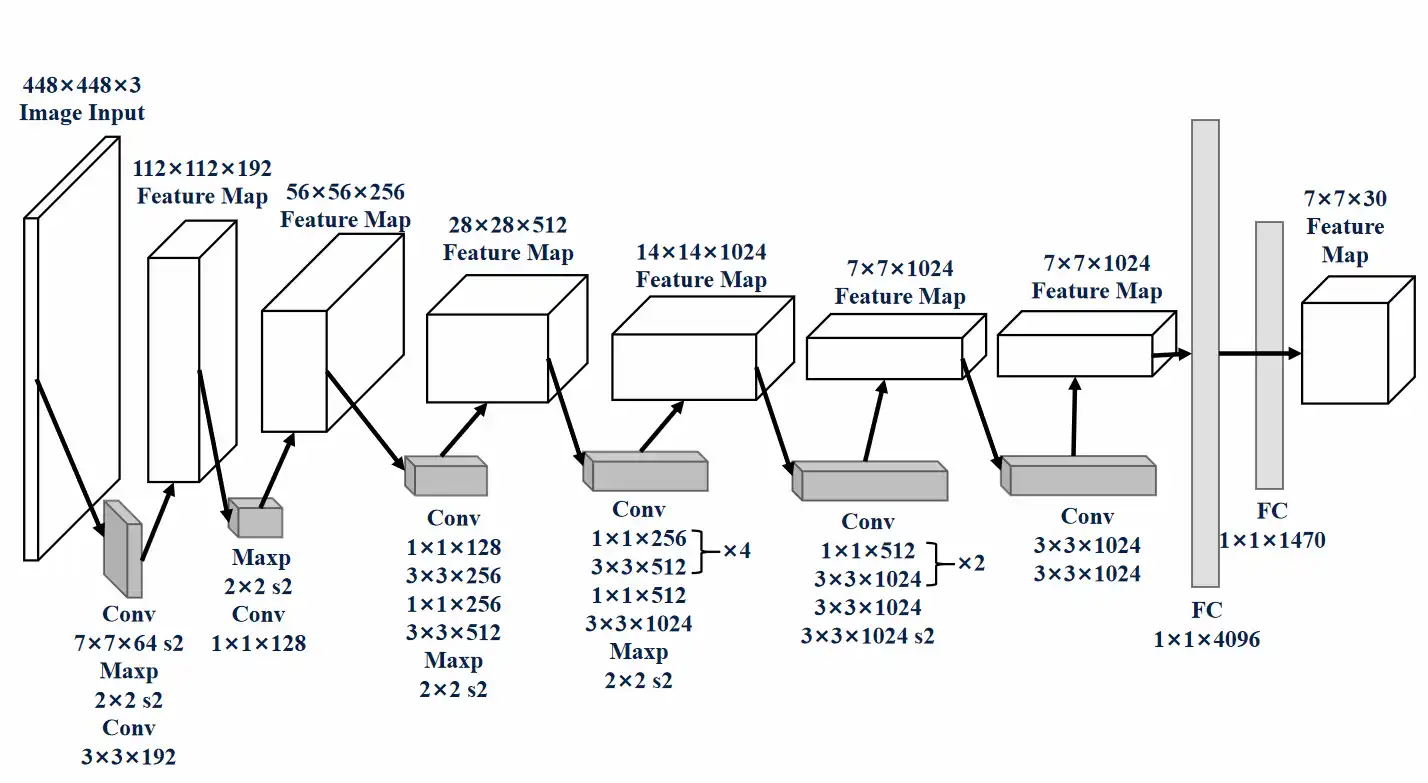
代码可以参考 darknet/cfg/yolov1/yolo.cfg at master · AlexeyAB/darknet
不过这些复现的代码都使用了Batch Normalization,实际YOLOv1并没有使用BN,BN是2015年提出的,那时候用的人不多。
此外代码中的 Pad=1 代表需要Padding,实际填充量为 \text{kernel size//2}
Loss Function
YOLOv1的损失函数可以看做由3部分组成:
位置损失: 前两项。中心点 \text{(x, y)} 使用均方误差。宽高 \text{(w, h)} 使用平方根误差,这样可以使小BBox获得更大Loss。
置信度损失: 第三四项。对包含物体的BBox,预测置信度 {\hat {C}_i} 应与真实 IOU 尽可能接近;对不包含物体的BBox,预测置信度应趋近于 0。
分类损失: 最后一项。每个Grid预测一组条件类别概率 \hat{p}_i(c),与GT标签计算MSE。
公式中出现的 1_{ij}^{obj} 是 一个指示函数,意义为:
在有物体时,损失函数1、2、3、5项参与运算;无物体时,只有第4项参与运算。有物体的另一个非负责框(同Grid中IOU较低的那个)也只有第4项参数运算。
关于权重的选择:
- \lambda_{\text{coord}} = 5 的原因在于一张图像中大多数Grid没有物体(起码当时的Pascal VOC数据集是这样的),如果不加权,网络会把位置预测的比较随意,较大的位置坐标权重有利于学习到更准确的位置信息。
- \lambda_{\text{noobj}} = 0.5 是作者通过调参得到的。在有物体时,让负责预测物体的那个框输出的置信度尽可能等于 IoU;在没有物体时,预测的置信度要尽可能趋近于 0(IoU 就是 0)。如果让每个空框的损失权重和正样本一样大,网络会只顾着把所有置信度压到 0,而不愿去学习少数有物体的框。
下面这张图[12]对 YOLOv1 的损失函数说明的很详细,可以参考:

YOLOv2
YOLOv2 的论文名是 YOLO9000……导致我起初还以为是什么要你命 3000 一类的梗……
YOLOv2 是网络结构和检测器。
YOLO9000 = YOLOv2 + 联合检测/分类训练。
使用Batch Normalization
YOLOv1 并没有使用 BN,使用 BN 的目的是提高收敛速度并减少过拟合。
分辨率提高
虽然输入分辨率从 448 降低为了 416,但是输出 Grid 尺寸从 7 变成了 13。
那为什么要缩小32的分辨率呢?
YOLOv2 的下采样倍率是 32,如果输入尺寸仍为 448,那么最终输出尺寸是 14。作者认为:画面中心更可能出现物体的中心(当时数据集和使用场景这样说没错,但是如今已不是这样了)。也就是说物体中心会出现在 4 个 Grid 的交界处;而如果输出尺寸是 13,则正好可以落在中心的网格上。
Anchor Box
YOLOv2 开始借鉴 Faster R-CNN 的 Anchor 思想。
Anchor 可以理解成网络预测 Bounding Box 时使用的先验模板(Prior Box)或参考框(Reference Box)。Anchor 基于特征图,GT 是基于图片像素。在训练过程中,通过和 GT 框的比对,把 Anchor 定义为正样本和负样本。
它本身不是最终检测结果,而是网络预测目标框时的起点。
整体流程可以理解成:
Anchor
↓
预测偏移量(Offset)
↓
修正 Anchor
↓
得到最终 Bounding Box
YOLOv1 使用的是直接回归坐标的方法,论文原文:
Predict coordinates directly
YOLOv1 中,每个 Grid Cell 直接预测:(x, y, w, h)
其中:
- (x, y):目标中心相对于当前 Grid Cell 的偏移;
- (w, h):相对于整张图像归一化后的宽高。
YOLOv2 不再直接预测目标框的宽高,而是在 Anchor 的基础上学习偏移量(offset)生成最终 Bounding Box。
论文原文:
Predicts offsets and confidences for anchor boxes
这里采用的是 Faster R-CNN 中 Bounding Box Regression 的参数化方式。
R-CNN 训练时使用如下编码公式:
其中:
- (x_a, y_a):Anchor 中心坐标
- (w_a, h_a):Anchor 宽高
- (x_{gt}, y_{gt}, w_{gt}, h_{gt}):GT 框
- (t_x, t_y, t_w, t_h):网络需要学习的偏移量。
举个例子。
假设有一个 Anchor:
中心=(100,100)
宽=80
高=120
真实框(GT):
中心=(110,95)
宽=90
高=140
根据公式计算:
因此网络真正学习的目标变成:
而不是直接学习:
可以理解成,网络不再从零生成目标框,而是学习: 如何在 Anchor 基础上进行微调。
推理阶段,需要将网络输出重新解码得到预测框:
恢复得到像素坐标系下的 Bounding Box。
不过这是 Faster R-CNN 使用的 Anchor 回归方式。
其中:
理论上没有约束,因此预测框中心理论上可能偏离 Anchor 很远。
虽然正常训练中偏移通常较小,但训练初期网络随机初始化时,输出可能不稳定,导致预测框位置波动较大。
YOLOv2 为了解决这一问题,对中心点预测重新进行了参数化。

论文称为:
Direct location prediction
这里的 Direct 并不是回到 YOLOv1 那种直接回归坐标,而是在 Anchor 的基础上,对中心位置进行重新参数化。具体公式:
其中:
- p_w,p_h:Anchor 的宽高
- c_x,c_y:当前 Grid Cell 在 Feature Map 上的整数索引(不是原图像素坐标)
- \sigma(\cdot):Sigmoid 函数
- b_x,b_y,b_w,b_h:预测 BBox 中心点的坐标(不是原图像素坐标)和宽高,通过乘下采样倍率 32 可以恢复到像素坐标系的坐标和宽高
例如输入尺寸为 416 × 416,经过 32 倍下采样后得到 13 × 13 的 Feature Map,则:
对于中心位置:
由于:
因此:
同理:
这意味着预测框中心始终位于当前 Grid Cell 内,不会漂移到其他 Grid。
对于宽高:
指数映射保证宽高始终为正数,同时允许在 Anchor 基础上自由缩放。
如果 t_w=0,则 b_w=p_w,说明预测框宽度与 Anchor 一致。
如果 t_w>0,则预测框变宽;如果 t_w<0,则预测框变窄。
可以看到,YOLOv2 对中心位置和宽高采用了不同的参数化策略:
- 中心位置:使用 Sigmoid 限制在当前 Grid 内,提高训练稳定性;
- 宽高:使用 Anchor + 指数缩放,以适应不同尺度目标。
这也是 YOLOv2 相比 YOLOv1 的核心变化之一。
最终,在输出特征图的每个 Grid 中预设 5 个 Anchor Boxes,注意 YOLOv2 的 Anchor 尺寸并非人工设计,而是通过 K-means 聚类在训练集 GT 框上自动生成,且以 IoU 为距离度量。
每个Anchor负责预测:
- 4 个偏移量 \text{t}_x, \text{t}_y, \text{t}_w, \text{t}_h
- 1 个置信度
- C 个类别概率
Network
YOLOv2 基于 Darknet-19 的 Backbone,采用全卷积结构,即去掉了全连接层。全连接层参数量大,同时会破坏特征图的空间信息。
全卷积还有一个好处,可以接受任何尺寸的输入。YOLOv1 的 1470 维 FC 和 7 × 7 × 30 的输出是严格对应的。但是如果使用 1 × 1 卷积代替 FC,则可以适配任何尺寸的输入。

用卷积层直接预测,使用 1 × 1 卷积得到 S × S × (k × (4 + 1 + 20)) 即 13 × 13 × 125 的输出。
在训练阶段,只有与 GT 框 IoU 最大的那个 Anchor 才作为正样本负责预测该目标;同个 Grid 中的其他 Anchor 仍按负样本处理。推理阶段,所有 Anchor 都会产生输出,最后靠 Score + NMS 选 BBox,解决了 YOLOv1 每个 Grid 只能检测一个目标的问题。
YOLOv2 还开始使用 Conv - BN - LeakyReLU 来替代原本的卷积层,只是这时候还没有将这三部分组合到一起作为一个模块。

DarkNet-19 输出的特征图分辨率为 13 × 13 × 1024,分辨率较低,因此 YOLOv2 还在 DarkNet 分出一个分支,抽出一个 26 × 26 × 512 维度的特征。再通过下采样得到 13 × 13 × 256 的特征图与 13 × 13 × 1024 的特征图做 Concat,以保留大小两种尺寸目标的特征。
Multi-Scale Training
因为没了FC,所以输入的尺寸就不受限制了。
YOLOv2 训练时随机改变输入尺寸,每隔几个 iteration 就更换一次。因此同一个模型对不同尺寸的输入都有很好的适应性。
YOLO9000
COCO 只有80个类别,是检测数据集;而 ImageNet 有20000+类别,是分类数据集。
作者同时对两种数据集进行联合训练。
由于检测和分类数据集的类别体系不同,作者提出了 WordTree,将 ImageNet 和 COCO 的标签融合成一棵层次化的语义树。
YOLO9000 的联合训练是统一在 WordTree 框架下进行,COCO 的 80 个类别也被整合进了这棵语义树。
YOLO9000 可以同时预测 9000 多种类别。
Loss Function
论文原文并没有重新设计新的 Loss Function,而是在 YOLOv1 的检测损失框架基础上继续使用平方误差(sum-squared error)。
整体仍可理解为:位置损失 + 置信度损失(obj | noobj)+ 分类损失。
位置损失:
只有负责预测目标的 Anchor 才参与计算。
注意这里监督的不是最终预测框坐标,而是 Anchor 空间中的偏移量:
即网络学习的是目标框相对于 Anchor 的位置偏移。
置信度损失:
对于存在目标的 Anchor:
对于不存在目标的 Anchor:
即预测框与 GT 越接近,其 confidence 越高。
分类损失:
只对存在目标的位置计算分类误差。
YOLOv3
YOLOv3 是一次 Incremental Improvement,即渐进性改进。
Network
YOLOv2 使用的 Backbone 是 Darknet-19,YOLOv3 改成了 Darknet-53。
Darknet-53 卷积层数更多,变成了53层。还借鉴了 ResNet的设计,引入了残差模块(Residual Connection),这也是其网络层数能加深到53层的原因之一。作者在论文中提到,Darknet-53 精度接近 ResNet,但计算量更低。
仍然是没有FC的全卷积网络。看网络架构图也是把CBL模块正式投入使用了。

Multi-scale Prediction
是 YOLOv3 最重要的升级,引入了 FPN(Feature Pyramid Network)。
深层特征(13×13)上采样后再与浅层特征拼接。
- 深层特征:感受野大,分辨率低,包含更多语义信息。更适合检测大目标。
- 浅层特征:感受野小,分辨率高,包含更多位置、细节信息。更适合检测小目标
| Feature Map | 感受野 | 检测对象 |
|---|---|---|
| 13×13 | 大 | 大目标 |
| 26×26 | 中 | 中目标 |
| 52×52 | 小 | 小目标 |
要注意:FPN并非 YOLOv3 首次提出,而是由论文[7]提出。
图a是图像金字塔,每张图缩放后都得走一遍 Backbone,很慢;图b是单尺度特征,传统方法;图c是网络自底向上(Backbone生成多层特征C3/C4C/5)的原始金字塔,没有跨层融合;d是正经的FPN,同时包含网络自底向上路径(同c)和特征自顶向下路径(从最高层C5开始上采样与C4融合,然后再传递到C3),这里没有特征自底向上的路径。

Anchor
YOLOv3依然是Anchor-Based,不过改进了使用方式,各个尺度不共享Anchor。
YOLOv3对3个尺度各分配了3个Anchor,总共是9个Anchor,也是通过 K-Means 得到的。
对于每个 Grid,输出变成了 3 × (4 + 1 + C),其中:
- 3:每个Grid中的Anchor数
- 4:Bounding Box的XYWH
- 1:置信度
- C:条件类别概率
对于COCO数据集,C=80。那么每个Grid的输出维度就是 3 × 85 = 255,结合3种不同尺寸的特征图,最终输出的维度是:
13×13×255
26×26×255
52×52×255
总BBox输出数量是 (13 × 13 + 26 × 26 + 52 × 52) × 3 = 10647个,然后进NMS。
这里还有一点值得讲一下,正样本,负样本,和忽略样本。
正样本:GT 中心点落在某个 Grid,那么该物体只会分配给这个 Grid。接着在 3 个尺度一共 9 个 Anchor 中,根据 Anchor 的宽高与 GT 宽高的匹配程度,选出最合适的那个 Anchor 作为正样本。也就是说,一个 GT 最终只会对应到某个尺度、某个 Grid、某个 Anchor,而不是先在所有预测框里选一个结果最好的框。
负样本:没有被分配为正样本的 Anchor 中,如果它与任意 GT 的 IoU 都小于 ignore_thresh,就作为负样本参与 objectness 的监督,目标标签为 0。
忽略样本:没有被分配为正样本,但它和某个 GT 的 IoU 又大于等于 ignore_thresh,这类 Anchor 不计入 objectness 损失,避免把和真值很像但没被选中的候选框硬压成负样本。
Loss Function
损失函数和以往一样,还是位置损失 + 置信度损失 + 分类损失。
位置损失和之前版本没区别,只计算正样本。
置信度损失有变化,开始从回归任务转向分类任务,使用 BCE(Binary Cross Entropy)交叉熵。
YOLOv2 的置信度公式为 \text {Confidence=P(obj)×IOU},把置信度当连续值来回归,有目标时接近IOU,没目标接近0。
但是YOLOv3的置信度损失函数为:
其中:
- \hat C: 真实标签GT,只有两种取值,有目标=1,无目标=0
- C:模型预测的 objectness 概率,范围在 [0,1],来自 sigmoid 输出
- L_{obj}:该 Anchor 的 objectness 损失
有目标时,\hat C = 1,带入公式只剩下 -\log C。这意味着如果模型预测的 C 趋近于1(确信有目标),那损失接近0;如果模型预测 C 趋近于0(有目标但模型预测错了),那么损失会很大
一个公式同时覆盖了YOLOv1和v2的正样本&负样本两种情况,不过YOLOv3的置信度只做了Anchor上目标存在性的置信度,就不管对BBox的质量
有目标时趋近1,无目标时趋近0。从回归变成了二分类。
分类损失,原文是:
We use independent logistic classifiers for each class instead of softmax.
YOLOv2 使用 Softmax,所有类别概率之和为 1,强调类别互斥。YOLOv3 改成了 BCE:
其中:
- C:类别数
- p_c:预测的第c的类别的概率
- y_c:GT类别(0或1)
注意这部分损失函数只有正样本Anchor才参与计算。实质上是将N分类问题转换为N个二分类问题。P(class) 没有约束,可以 dog = 0.8; cat = 0.5; person = 0.2
YOLOv4
如果 YOLOv3 = Darknet53 + FPN + 多尺度预测
那么 YOLOv4 = CSPDarknet53 + SPP + PAN + 数据增强升级

Backbone
Backbone 从 Darknet-53 升级到了 CSPDarknet53。这个 Backbone 也被后来多个版本的 YOLO 沿用。
CSP 全称 Cross-Stage-Partial-connections。CSPNet 作者认为,网络推理成本过高的问题是由于网络优化中的梯度信息重复导致的。传统的残差网络在反向传播时,存在不同层之间计算重复梯度信息的问题,残差块解决的只是网络过深时的梯度消失问题,CSP 结构解决的是冗余梯度信息的重复学习和计算问题。
思想是把特征图拆成两部分:
- 主干分支:经过 Residual Block 继续进行特征提取和计算
- 跨阶段分支:绕过 Residual Block,走 Shortcut
CSP 减少模型计算量和提高运行速度的同时,不会降低模型的精度。同时可以和 DenseNet、ResNet、DarkNet 等 Backbone 结合使用。
在 Backbone 中将激活函数从 LeakyReLU 换成了 Mish,这是 2019 年新提出的激活函数,其他模块仍使用 LeakyReLU。Conv + BN + Mish 模块被称作 CBM。
Neck
Neck 使用了 SPP 模块,以及 FPN + PAN。
SPP-Net 全称 Spatial Pyramid Pooling Network。设计初衷是解决不同尺寸特征图进入 FC 的问题。
特征进入 SPP 模块后,会并行出四条分支:
- 不做任何处理,直接跳连
- 使用 5×5 的 Max-Pooling
- 使用 9×9 的 Max-Pooling
- 使用 13×13 的 Max-Pooling
然后这四条分支的特征在通道维度 Concat 到一起。
SPP 以极低的成本扩大感受野(池化参数量小)并实现多尺度特征融合。

PAN 全称 Path Aggregation Network,在 FPN 的基础上增加了自底向上的路径,也就是又加了下采样。
在 FPN 阶段,将深层的语义特征传递给浅层特征;在 PAN 阶段,基于 FPN 融合完毕的特征,将深层语义继续向下传递。
下图能够很好地说明 PAN 的过程,红绿线代表一种设想中的特征流动方向。
左侧蓝色部分是 FPN 阶段,通过卷积得到特征 C2/C3/C4/C5 之后:
- P5 = C5
- P4 = Up(P5) + C4
- P3 = Up(P4) + C3
- P2 = Up(P3) + C2
加号在 PANet 原文是逐元素相加,YOLOv4 中是 Concat,Concat 相比逐元素相加更能无损保留信息。FPN 过程是自顶向下的,深层(高层)语义向底层(浅层)传播。
右边橙色部分是 PAN,在 FPN 得到融合的 P2/P3/P4/P5 特征之后:
- N2 = P2
- N3 = Conv(N2) + P3
- N4 = Conv(N3) + P4
- N5 = Conv(N4) + P5
加号在 YOLOv4 中也是 Concat,PAN 过程是自底向上的。

这样就形成了深层语义特征和浅层定位特征的双向流动。
数据增强
新增了 Mosaic 数据增强功能,这是 2019 年新提出的数据增强方式。采用 4 张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。
IoU 相关
说损失函数之前,先来说明各种 IoU。
IoU
交并比 IoU 的具体概念就不多说了……
传统 IoU 存在 3 个缺陷:
- 当预测 BBox 和真实 BBox 无重叠时,IoU = 0,无法提供梯度
- 无法区分不同对齐方式的 BBox
- 对 BBox 的尺度变化不敏感
GIoU (Generalized IoU)
GIoU 先找到预测框 B 和真实框 B^{gt} 的最小外接矩形 C,解决无重叠情况下梯度消失的问题。
公式中分子代表外接矩形 C 中不属于两个框并集的区域面积;分母就是 C 的面积。
完全重合时,GIoU 趋近于 1;完全不重叠时,GIoU 趋近于 -1。
GIoU 虽然解决了无重叠时梯度消失的问题,但对框的相对位置和形状差异刻画不够精细,因此收敛速度和精度不行。
DIoU (Distance IoU)
DIoU 在 GIoU 基础上引入中心点距离惩罚项,直接优化预测框与真实框的中心点距离。
其中:
- \rho^2(b, b^{gt}):预测框中心点 b 与真实框中心点 b^{gt} 的欧氏距离平方
- c^2:包围预测框与真实框的最小外接矩形的对角线距离平方
当框重叠时,DIoU 与 IoU 行为一致。但是 DIoU 收敛速度显著快于 GIoU,因为中心点距离直接反映了位置偏差。
不过由于未考虑到长宽比一致性,对框的形状差异不敏感……(有时候就佩服这些靠算法科研的,怎么想出这么多 pros & cons 的?)
CIoU (Complete IoU)
在 DIoU 基础上进一步引入长宽比一致性惩罚项。同时优化重叠面积、中心点距离和长宽比三个维度,是目前最全面的 IoU 变体。
新增的 \alpha v 中的 v 是衡量长宽比一致性的指标,计算公式为:
新增的 \alpha 则是平衡参数,用于协调 IoU 和 v 的权重,公式为:
敲公式敲累了……反正最后都是调库,这个 CIoU 精度高,收敛快,然而需要调参。
Loss Function
和 YOLOv3 相比,损失函数变化很大。
分 3 个子损失:边界框回归损失 + 置信度损失 + 分类损失。
相比 YOLOv3,边界框回归损失从 MSE 被替换成了 CIoU (Complete IoU) Loss。MSE 的缺点包括:
- MSE 将中心点坐标和宽高当作独立变量处理,但边界框的质量本质上由整体重叠度决定。一个框中心偏了但宽高刚好,与中心对了但宽高错了,MSE 可能给出相同的损失值,但实际检测效果天差地别。
- MSE 对大框的像素误差惩罚更重,小框的像素误差惩罚更轻,导致小目标定位不准。
- 检测模型的最终评估标准是 IoU / mAP,而 MSE 优化的目标与 IoU 没有直接数学关系,存在优化目标与评估目标不一致的问题。
CIoU损失公式为:
\text{respond\_bbox} 是正样本掩码,是个 0/1 开关,只有被选中的正样本位置才计算边界框损失,其余位置直接跳过。
\text{bbox\_loss\_scale} 为小目标动态加权,是针对大小目标不平衡的补偿机制,框越小,值越大。
三者连起来看就是:
置信度损失用于判断anchor中是否包含目标,使用 BCE 二值交叉熵:
分类损失用于判断目标分类准确性,同样使用 BCE 而不是 softmax:
参考文章
[1] [1506.02640] You Only Look Once: Unified, Real-Time Object Detection
[4] darknet/cfg/yolov1/yolo.cfg at master · AlexeyAB/darknet
[5] YOLOv2和YOLOv3 - laumy的学习笔记
[6] [1804.02767] YOLOv3: An Incremental Improvement
[7] [1612.03144] Feature Pyramid Networks for Object Detection
[8] YOLO-----关于正负样本、Loss、IOU、怎样去平衡正负样本的问题?_yolo模型需不需要负样本-CSDN博客
[9] [2004.10934] YOLOv4: Optimal Speed and Accuracy of Object Detection
[10] 【YOLO系列】--YOLOv4超详细解读/总结(网络结构)-CSDN博客
[12] A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS
评论