
YOLOv9
和 YOLOv4/v7 一脉相承的作品,但是 Anchor-Free。
PGI 可编程梯度信息
全称 Programmable Gradient Information,这是一个辅助监督框架,目的是解决深度网络逐层传播的信息损失问题。
PGI 包含 3 个主要组件:主分支,辅助可逆分支,多级辅助信息。在推理过程中只用到主分支,无需额外推理成本。
辅助可逆分支,确保在计算目标函数时保留完整的输入信息,从而生成可靠的梯度来更新网络权重。
多级辅助信息用于处理深度监督造成的错误累积问题。
GELAN 广义高效层聚合网络
专为配合 PGI 而设计的 Backbone 网络结构,仅只用标准卷积算子。
类 ELAN 结构的设计核心是优化最短梯度路径,而不是增加网络深度,
作者将 CSP 和 ELAN 思想结合起来,还支持 ResNet 和 DarkNet 的灵活替换,这个模块的设计目的是在不增加计算复杂度的情况下提升特征提取能力,如何不增加计算复杂度?答曰:增加更多跳连。
YOLOv10
这篇论文彻底消除推理时对 NMS 的依赖,因此号称第一代端到端 YOLO。无 NMS 在工程上的最大意义是:少了 CPU 上的 NMS 后处理,整个推理流程完全在 GPU 上完成、
很多网络都号称自己是端到端,这词是不是被滥用了?并非如此,并没有规定端到端必须是哪两端,图像都是输入端,这没有问题。我输出端可以是 2D BBox,3D BBox,Action,只要我不经后处理可以直接得到这些结果,那我就可以说自己是端到端。
Consistent Dual Assignments
检测头的 CDA 双标签分配是实现 NMS-Free 的关键。
在训练阶段,分成 2 个阶段,One-to-Many 和 One-to-One 共同训练。如果只有一个O2O的话,监督信号会很弱,训练精度不会太高且难以收敛。
在推理阶段,仅保留 One-to-One,不再需要NMS。
这不是两个独立的检测器,大部分参数是共享的。
One-to-Many Assignment 负责通过密集梯度信息提升训练效果,和之前的 YOLO 方式一致,会产生重复框。
One-to-One Assignment 借鉴了 DETR 的思想,负责提供唯一输出,一个 GT 只匹配一个预测,其余的都是负样本。

上图(b)展示了当 O2O 和 O2M 使用相同度量公式时,两个分支对正样本的判断高度一致。橙色是使用相同打分公式,蓝色使用不同打分公式。
两个 Head 的输出根据打分排序,打分公式是:
其中:
- s:空间先验,确定 Anchor 是否在 GT 中心区域
- p:classification score
- IoU:定位质量
- \alpha,\beta:权重
权重相同时,可以认为是 Consistent;权重不同时,为 Inconsistent。
Holistic Efficiency-Accuracy Design
整体效率重设计,主要是做了一些结构性创新
Spatial–Channel Decoupled Downsampling 将之前的 k3s2 的卷积层拆成通道调整和空间压缩两部分以减少冗余计算。
此前的 YOLO 的 Backbone 和 Neck 使用大量重复模块的堆叠来构建,Rank-Guided Block Design 通过计算每个 Layer 的内在秩(Intrinsic Rank),分析发现深层的 Rank 明显低,从信息论的角度出发,低秩意味着信息冗余度更高。具体方法是将每个阶段基本块中的最后一个卷积层的权重做 SVD 分解,统计大于阈值的奇异值的个数。LoRA[3] 的产生也是基于这个思路。
最终这些低秩的 Layer 会被替换为 CIB(BiC:你谁?)
Large-Kernel Convolution 用更大卷积核扩大感受野,但是在目标检测网络中,大卷积核不能乱用,主要是参数量会爆炸,所以一般采用小卷积核串联的方式。YOLOv10 将 7 × 7 的卷积核放在了深层的 CIB 模块中,开销相对可控,也避免直接大核模糊掉浅层的细粒度特征。
作者认为:分类任务比定位任务更容易,因此分类分支可以进一步轻量化,提出了 Lightweight Classification Head 进一步轻量化分类的 Head。
Loss Function
继承了 YOLOv8 的损失,只不过 O2O 和 O2M 俩头分别计算损失。
分类损失使用上面的打分公式生成软标签
YOLOv11
Ultralytics 又一无论文《力作》……
官网并未找到架构图,图摘自 CSDN [5]。

C3K2
继承自 YOLOv8 的 C2f,但在内部新增了 C3K 模式,可用 k 指定卷积核大小。
模块将输入特征分成两部分,一部分通过普通卷积操作直接传递,另一部分走 C3K 或 BottleNeck,最后将两部分特征 Concatenate。

C2PSA
Partial Self-Attention 局部自注意力模块。在 C2 内部嵌入,在整体结构上,C2PSA 被嵌入在 Backbone 最后一个 C3K2之后。
PSABlock 引入通道自注意力,对特征图一部分通道做 Self-Attention,另一部分走 Shortcut。

DWConv
DepthWise Convolution 深度卷积,是轻量化 CNN 的核心算子。
具体做法是逐通道卷积,每个通道由对应的卷积核处理。
| 特性 | Standard Convolution | DepthWise Convolution |
|---|---|---|
| 卷积核形状 | (C_{out}, C_{in}, K, K) | (C_{in}, 1, K, K) |
| 跨通道操作 | 是,每个输出通道融合所有输入通道 | 否,每个通道独立处理 |
| 输出通道数 | C_{out} | C_{in} |
| 参数量 | C_{in} \cdot K^2 \cdot C_{out} | C_{in} \cdot K^2 |
不能单独使用DWConv,因为它没有办法跨通道融合信息,因此必须在后面接一个 1 × 1 逐点卷积 PointWise Conv (PWConv) 配合使用。DWConv + PWConv 俩合在一起叫深度可分离卷积。



YOLOv12
YOLOv11 是局部轻量化的引入了 Attention。
YOLOv12 是将 Attention 变成了核心机制。
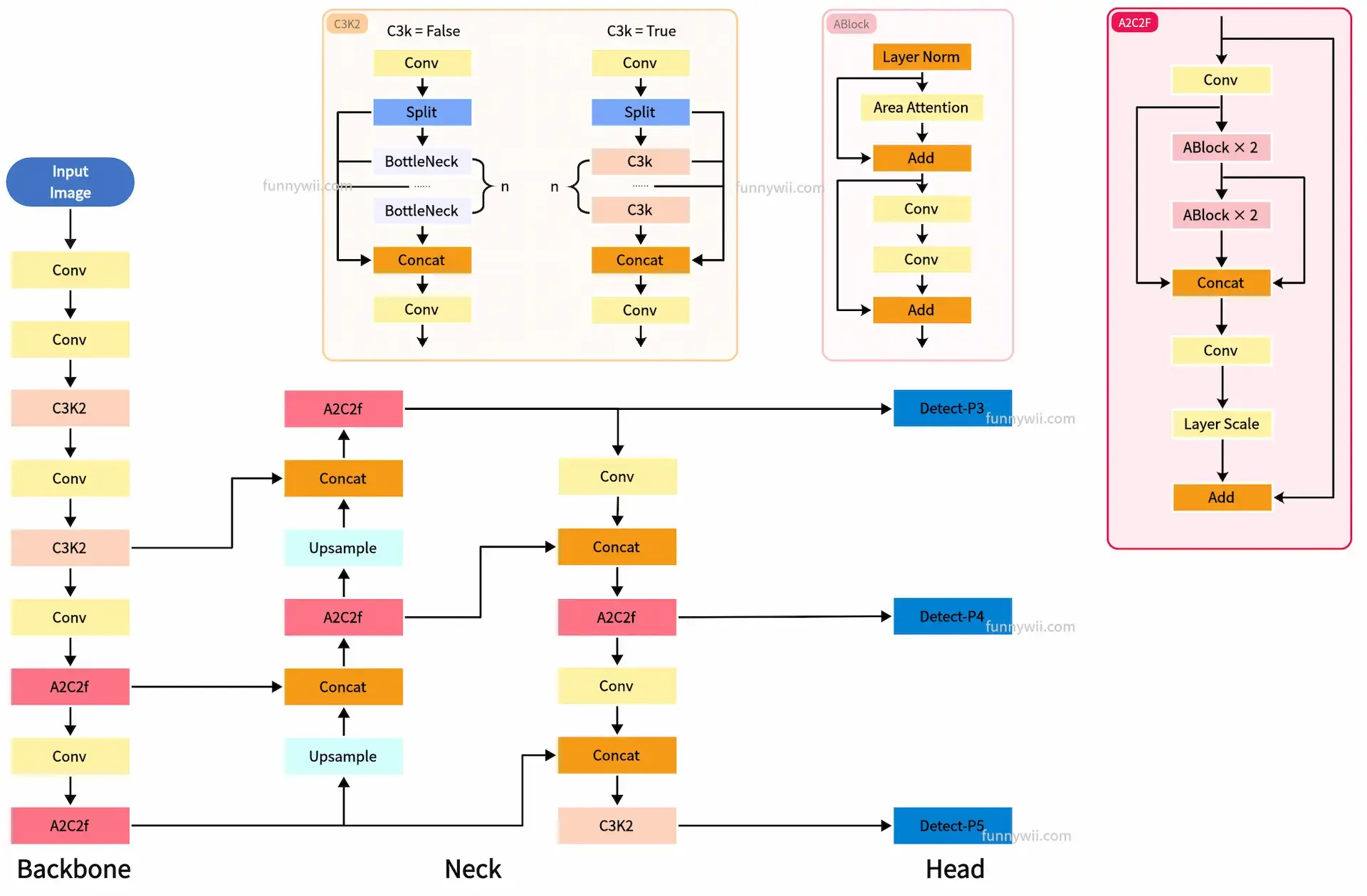
Area Attention

上述四种注意力机制的核心差异在每个查询点 Query 能关注到的感受野和实现方式上:
- Criss-cross Attention(十字交叉注意力):关注查询点所在的整行 + 整列。
- Window Attention(窗口注意力):关注查询点周围的一个局部窗口(e.g. 7 × 7),在 SwinT 论文中提出。
- Axial Attention(轴向注意力):查询所在点的整行/整列。将 2D 注意力解耦成 2 个 1D 注意力。
- Area Attention(区域注意力):将特征图划分为几个大的非重叠区域,查询点可以关注区域内的全部像素
这些方案的目的都是解决 Attention 计算复杂度高的问题。
Area Attention 的思路是不让所有 Token 两两交互,而是先划分区域,再在区域内建模。每个区域内只看自己,不会看其他区域。
比如 \text {N = H × W} 的区域,直接做 QK 运算,每个位置要和所有位置计算注意力,需要 \text {N × N} 次运算。
如果划分成 \text A 个小块,每个区域 \text M 个 Token,独立计算 Attention,原来的 \text N^2 就变成了 \text A × \text M^2,\text {N = A × M},时间复杂度就变成了 \text {O(NM)}。
那远距离建模咋解决呢?Area Attention 不是单层独立存在,而是逐层堆叠。而且 Area Attention 是 CNN-Transformer 混合架构,不断地卷积下采样可以让感受野变得更大。
Residual - ELAN
R-ELAN 在 ELAN 的基础上增加 Block-Level 的残差连接和缩放系数。

乍一看 YOLO 系列里面已经塞满了各种残差,这个 R-ELAN 有啥特别的呢?
从网络结构的角度来说,残差位置不同,解决的问题不同。
普通的 Residual 一般用于模块内部,解决模块内部的梯度传播问题。
R-ELAN 的尺度更大,跨越了多个 Block 堆叠,作用范围更加宏观。
其实在 CNN-YOLO 时代,以前的残差模式是够用的,但是在大量引入 Attention 模块之后,之前的那种残差连接就不够用了。
Flash Attention
YOLO 26
也实现了 NMS-Free,方式与 YOLOv10 相同。
新增了关闭 DFL 的接口,关闭后精度并未明显下降,但是推理效率大幅提升。
MuSGD (Muon + SGD) 混合优化器。Muon 是 LLM 领域的一种优化器,收敛速度快;SGD 在视觉任务上表现更好。MuSGD 结合两者优势,实现更快的收敛速度、更稳定的训练动态、对超参数更低的敏感度。
引入了 ProgLoss (Progressive Loss Balancing),在训练过程中动态调整 O2O 和 O2M 连个头对总损失的权重。训练开始时 O2M 权重更高以稳定学习;训练后期权重向 O2O 的头偏移,确保训练和推理行为一致。
引入了 STAL (Small-Target-Aware Label),专门为小目标引入,在标签分配阶段主动偏向小目标和部分遮挡目标。
DETR
DEtection TRansformer。
参考文章
[1] [2402.13616] YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
[2] YOLOv10: Real-Time End-to-End Object Detection
[3] [2106.09685] LoRA: Low-Rank Adaptation of Large Language Models
[4] Ultralytics YOLO11 | Ultralytics
[5] YOLOv11 | 一文带你深入理解ultralytics最新作品yolov11的创新 | 训练、推理、验证、导出 (附网络结构图)-CSDN博客
[6] [2502.12524] YOLOv12: Attention-Centric Real-Time Object Detectors
评论