

点云数据体素化后,有90%+的Voxel是空的,如果像VoxelNet那样直接使用3D Conv,计算量太大。
左图是稀疏的2D Tensor,深灰色像素都是0,浅灰色是non-zero点。
右图是稀疏的3D Tensor,只有红色的体素才是non-zero。
因此提出了3D稀疏卷积——3D Sparse Convolution。传统的3D卷积则被称为稠密卷积——Dense Convolution。
核心机制
Dense Conv处理的是矩阵。
Sparse Conv处理的是表。
Sparse Conv使用类似于哈希表的结构,只记录坐标和特征向量。
做卷积时,算法会提前计算好,当卷积核在有数据的地方滑动时,哪些输入点会和卷积核的哪个权重相乘。这个过程是在构建Rulebook。
计算时直接根据Rule把对应的数据拿出来算一下就行,不需要遍历整个空间。
既然是表结构,那么2D和3D稀疏卷积其实没有什么本质区别。那就以2D为例,2D Dense Convolution输入的是的矩阵;Sparse Convolution输入的则是2套列表:
Data List:只存non-zero点的值,我们称之为活跃点Active Sites。
Index List:保存non-zero点的坐标位置。
稀疏卷积流程
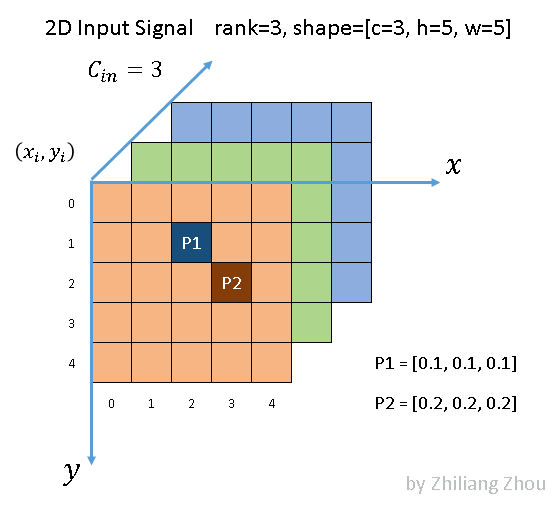
定义输入
我们先定义一个输入,这部分内容除了Focal Sparse Convolutional以外,均参考《How does sparse convolution work?》[1]。
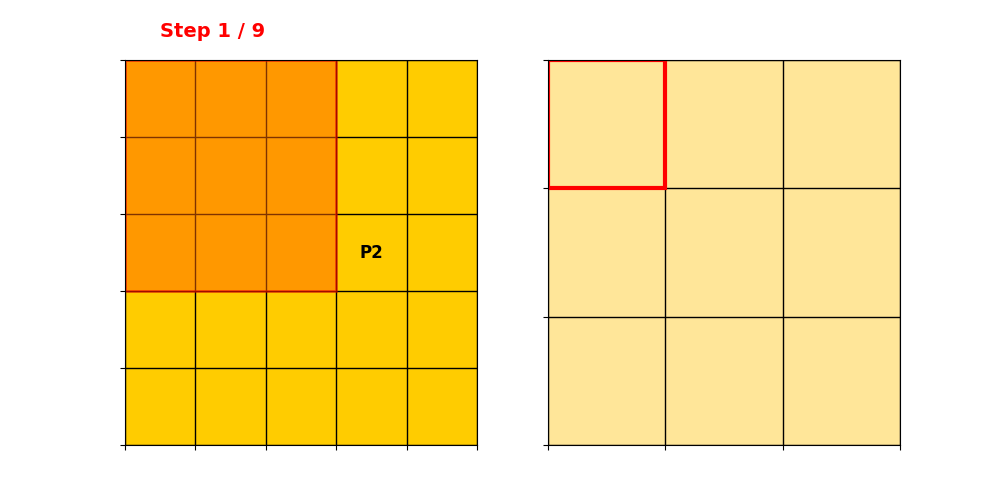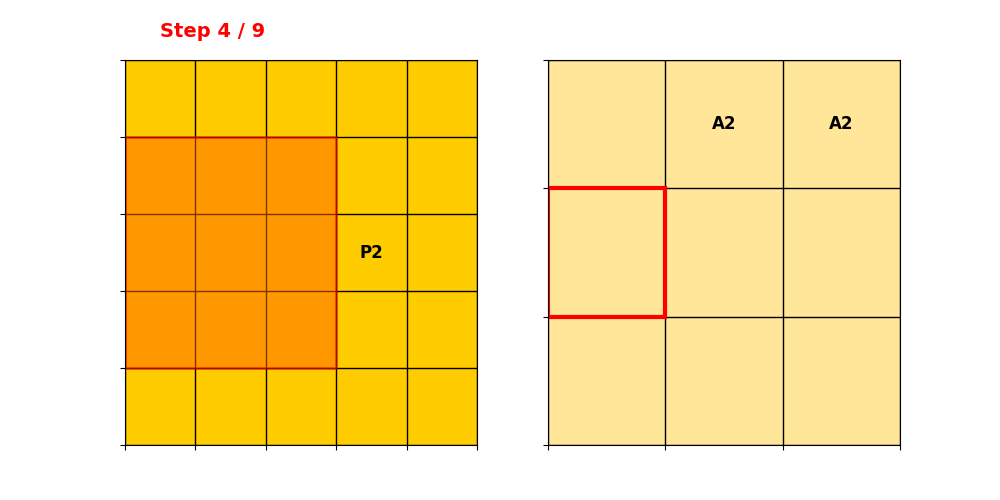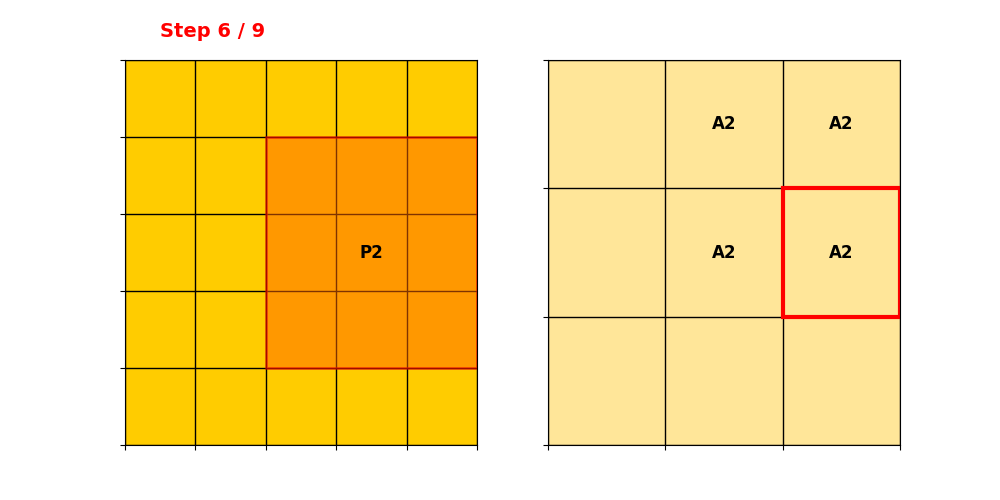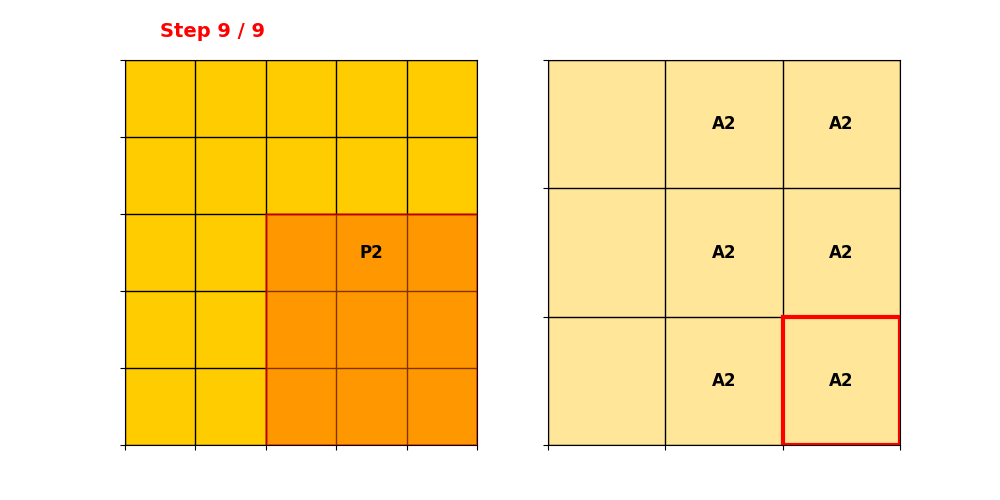
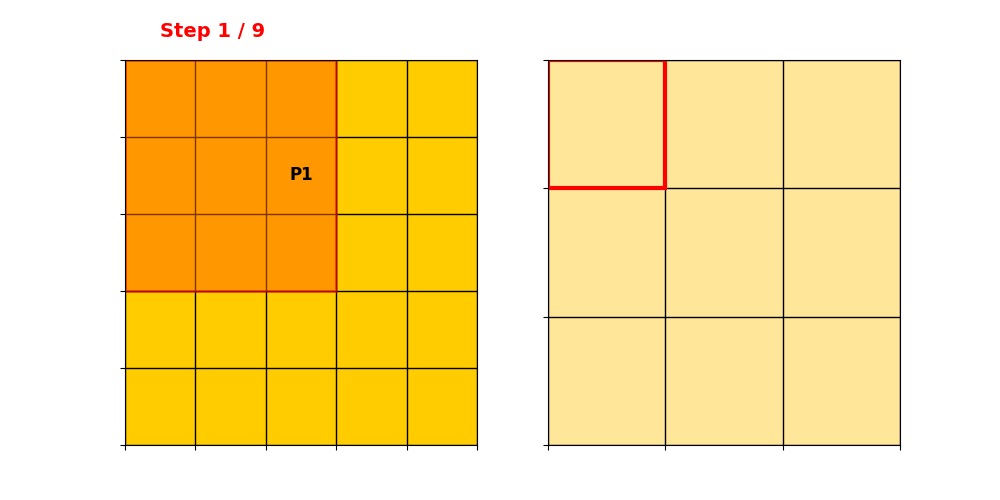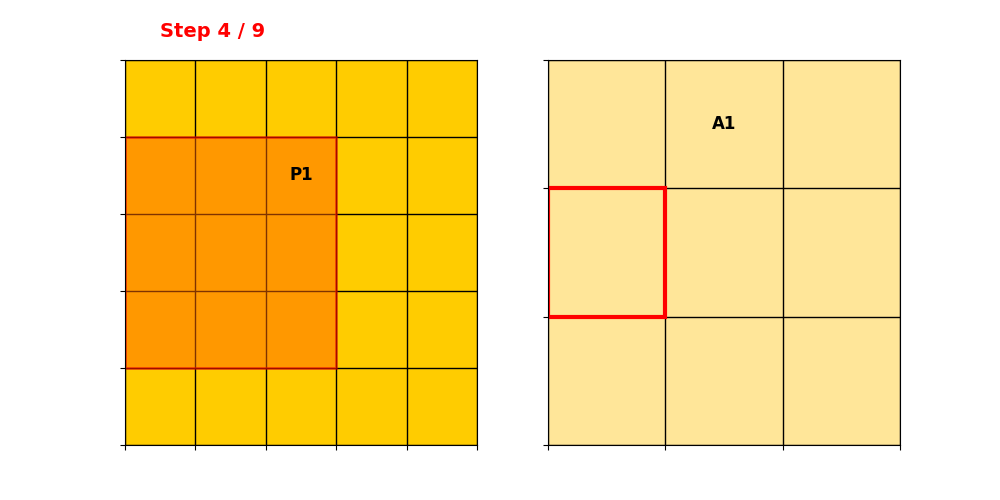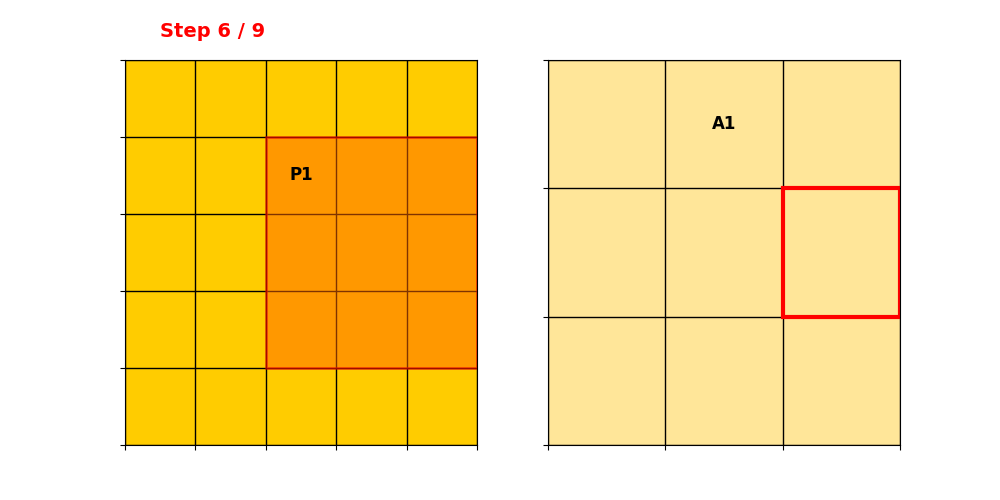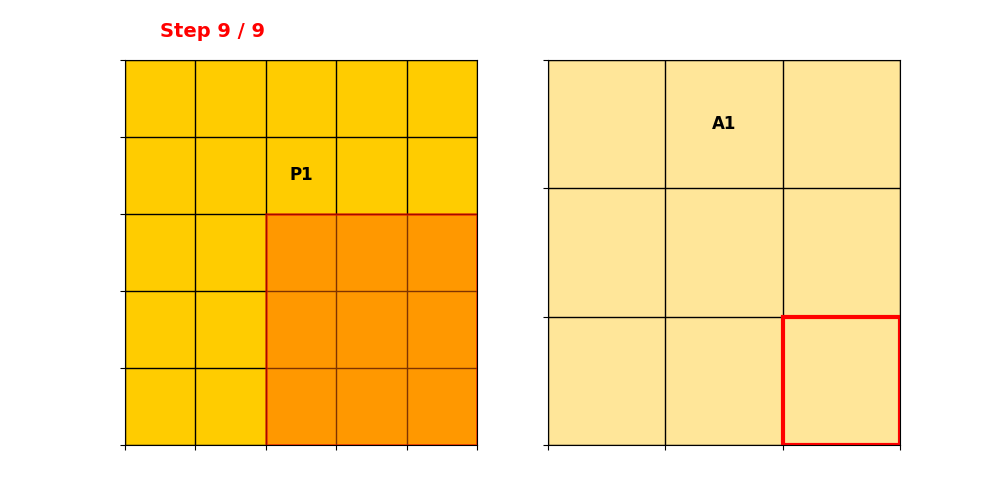
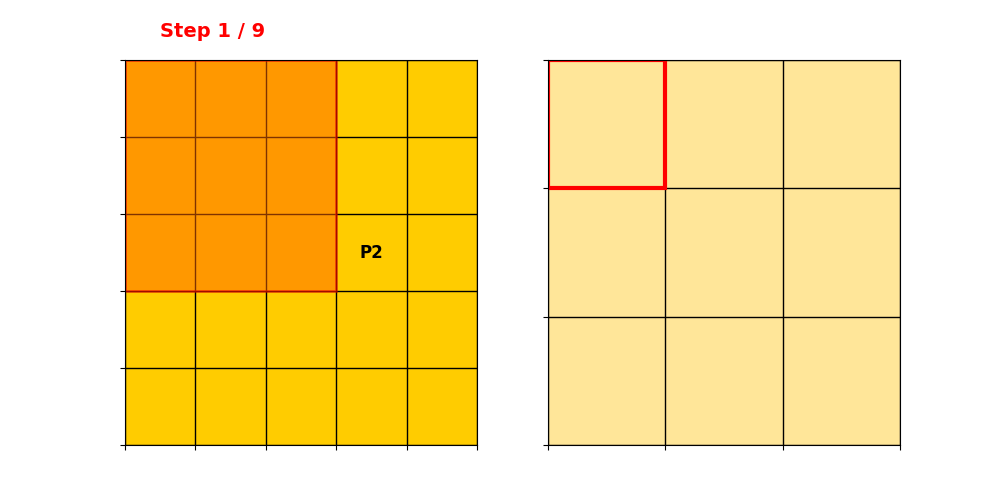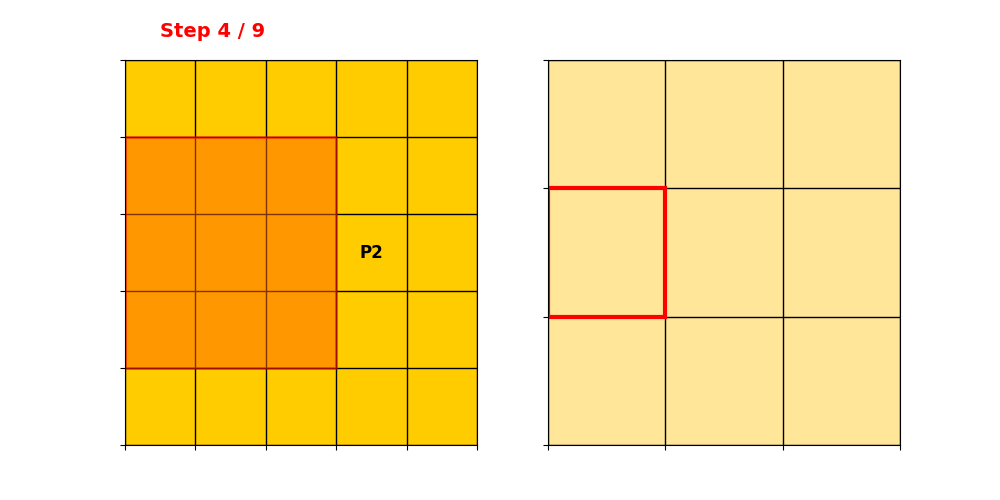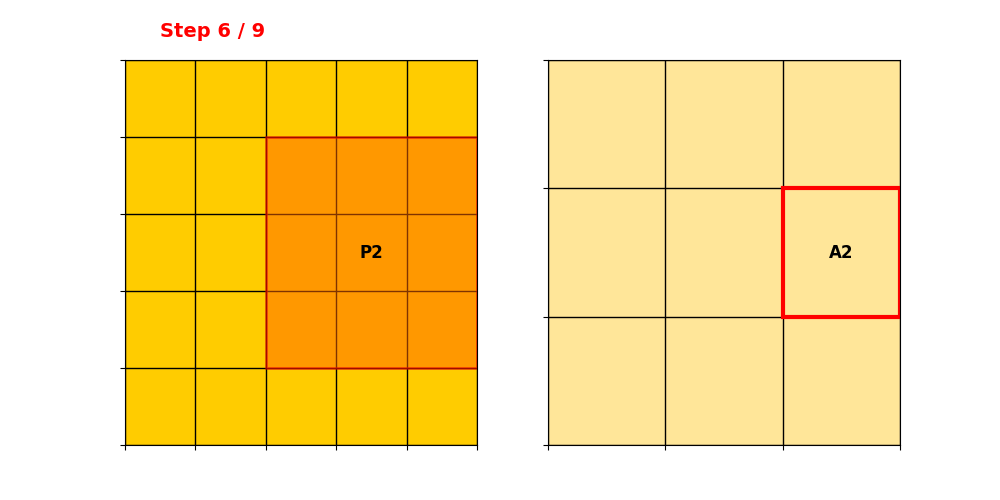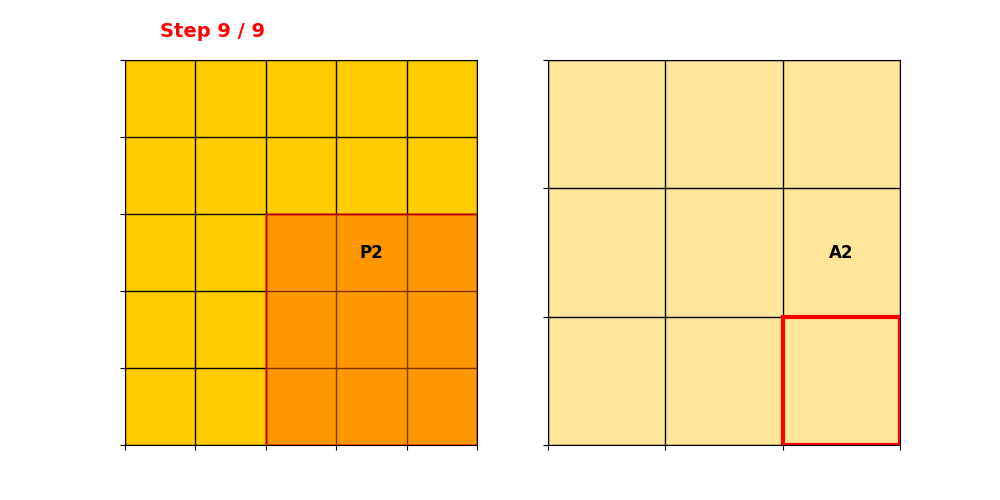
输入维度。只有P1和P2位置non-zero,取值分别为和。
卷积核为,stride=1,padding=0。深浅代表两个输出通道。
得到稀疏表示:
Data:
Index:,注意这里是列/行索引。
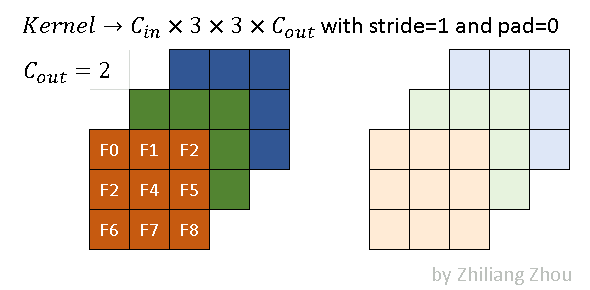
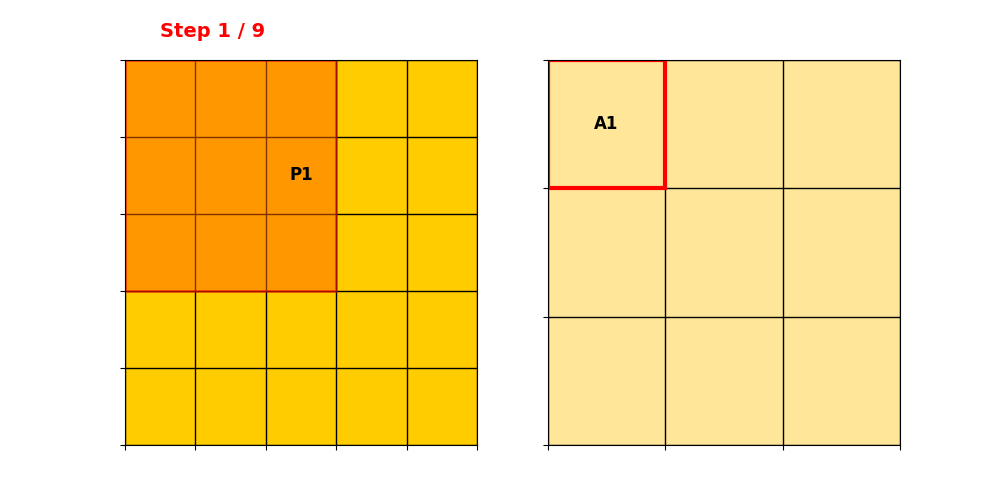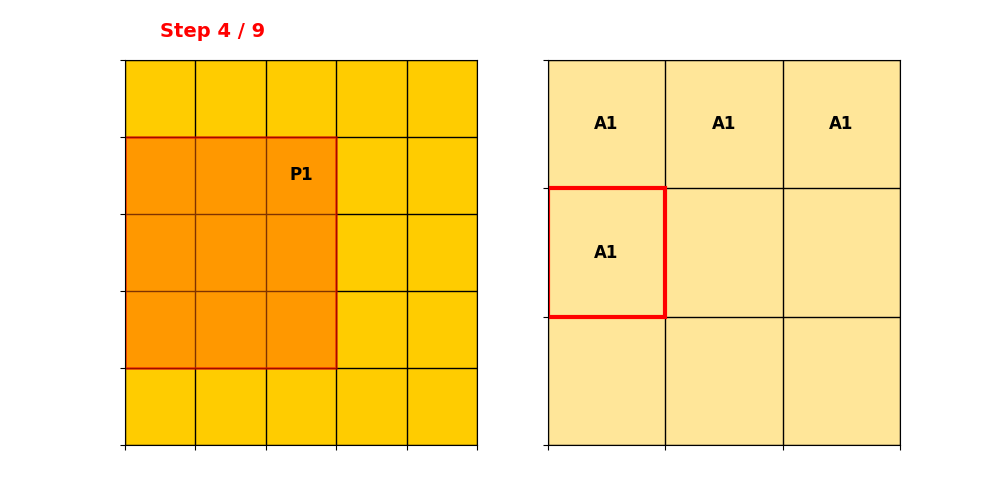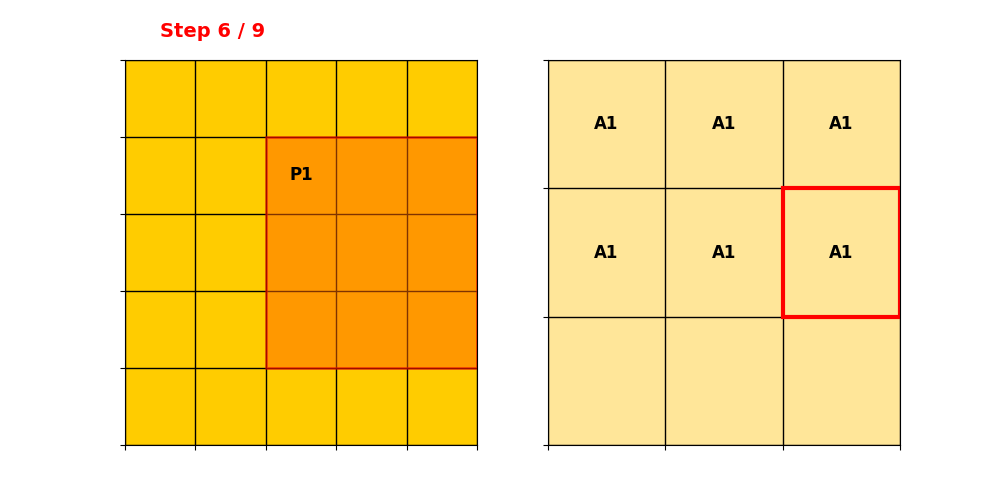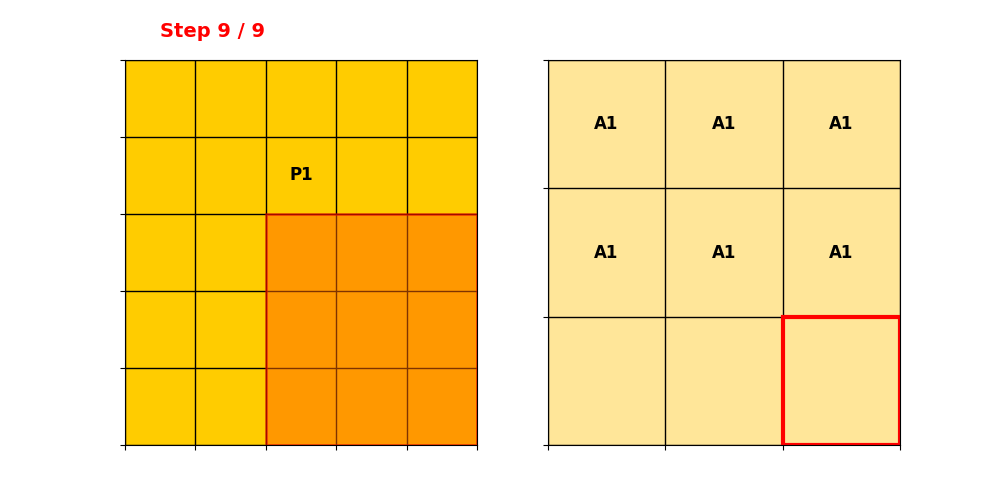
构建Hash Table
Input Hash Table储存所有Active Sites,根据示例的P1和P2,那就是保存2个。
:
:
然后构建Ouput Hash Table,先操作P1:
P2对准过程同理。然后记录卷积后Active Sites元素的位置。P1和P2输出对应的索引为:
把重复的部分合并,得到输出的位置表,即Output Hash Table。
输入&输出的Hash Table构建完整过程如下图:

构建Rulebook
构建Rulebook的目的和im2col算法类似,将卷积从数学形式变为高效的可编程形式。
im2col核心是空间块→列的维度重组,相当于用空间换时间,完全不关注原子操作或Kernel Elements的独立性,即使输入稀疏,im2col仍会完整展开所有窗口,包含大量无效零值计算。
和im2col不同的是,Rulebook的核心是收集原子操作,按Kernel Elements分组。
收集原子操作:只有输入中non-zero的点参与卷积乘法加法,跳过所有zero值,每个原子操作会记录:
输入的non-zero的Index:
对应的Kernel Element(weight & offset)
输出的Index:
乘法加法次数
按Kernel Element关联操作,将所有原子操作按Kernel Element分组(如 F0 组、F1 组…F8 组),每组内的操作共享同一 Kernel偏移与权重,可并行执行。
下图是构建Rulebook的示例,图中中的并没有被直接体现出来,而且作者没详细解释Query Kernel的过程,所以让人困惑。的意义应该是给定输入点和输出点的位置,计算卷积核(Kernel)上对应的权重位置偏移量。
以P1点为例,就是当卷积核滑动到以输出点对应的输入位置为中心的位置时,输入点 相对于这个卷积核几何中心的偏移量。最直白版:输入点P1在当前卷积核内部的相对位置(不能更直白乐)。
所以公式应该可以重写为:
其中是卷积核的Kernel Size,这里就是3,除后是1。
我们快速回顾一下到这里都做了什么(For P1 Pixel):
获取了像素点P1在2D Tensor中的位置信息,以及索引(编号),以此构造Input Hash Tabel
获取了像素点P1在Conv操作后,也就是在输出特征图中的每个输出的位置信息,以及对应索引(编号),以此构造Output Hash Table
获取了像素点P1在Kernel中的相对位置(offset偏移量),这决定P1的Value和Conv Kernel中的哪个Weight执行运算,并得到Rulebook
建立了完整的Input Pixel -> Conv Kernel × Input -> Output Feature的完整索引、空间位置映射链路
所以,Rulebook本质是在做的映射。
稠密卷积对每个输出点,必须遍历K×K个输入点,无论是否为zero;但是稀疏卷积对每个non-zero输入,只需要遍历它能产生结果的输出点。

程序运行模式
[1]作者做的这个图非常牛逼(Rulebook多了几行,要是没错误就更牛逼了),红线(红框)和黑线(黑框)是卷积核两个channel的操作。存在多少个offset,就启动多少个Block,然后每个Block内的Thread数量和原子操作数量相同。
在实际写代码的时候,所有原子操作也是按照offset进行分组的。同一组内的操作使用同一个Conv Kernel Weight。整个过程没有任何矩阵乘法,没有任何滑动窗口,没有任何分支判断,就是单纯的乘法和加法操作,所以很快。
然后说明红色原子操作的过程,原子操作在这里可以定义为:
其中:
:初值为0,相同的会在不同的线程的原子操作中累加,原子操作线程安全
:输入,0.1
:对应offset位置的权重,F0
计算得到。
然后计算黑色原子操作过程,因为两者的相同所以会累加,其中
:已经是
:0.2
:F4
计算得到,最终结果为。
然后你们看吼,Output Sparse Tensor是2列,其中一列保存的是索引,另一列保存的是特征值即上面的计算结果。

稀疏卷积分类
Regular Sparse Convolution(RSC)
只要卷积核覆盖到任意一个输入活跃点 → 该位置就算输出。

输出点变多,稀疏性下降。
Submanifold Sparse Convolution(SSC)
只有卷积核中心落在输入活跃点上 → 才计算输出。
输出活跃点数量 = 输入活跃点数量,稀疏性完全保留。
Focal Sparse Convolutional(FSC)
FSC 的核心创新是使特征稀疏性可学习,通过位置级别的重要性预测动态决定卷积的输出位置和感受野大小,而不是像传统稀疏卷积那样使用固定的输出模式 。
FSC 一个额外的轻量级分支,为每个输入特征预测一个立方体重要性图,然后根据这个重要性图动态选择哪些输入特征需要进行邻域扩张,以及扩张到哪些位置 。
FSC 可以认为是 SSC 和 RSC 的动态组合:
当所有位置都被预测为不重要时,FSC 退化为 SSC。
当所有位置都被预测为重要且所有邻域位置都超过阈值时,FSC 退化为 RSC。
这几种稀疏卷积方案,并没有绝对优劣之分,应该按照场景需要选择不同的稀疏卷积方式。
参考文章
[1] How does sparse convolution work? | Towards Data Science
[3] [2204.12463] Focal Sparse Convolutional Networks for 3D Object Detection
[4] [1711.10275] 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks
[5] [1505.02890] Sparse 3D convolutional neural networ
[6] Im2Col算法介绍 - 知乎
评论