

PointNet
直接以 的Raw PointCloud作为输入,每个点使用表示。可以选择在后面接等特征
证明了卷积神经网络直接处理点云的可行性。
作者认为,卷积网络处理Raw PointCloud时,必须考虑到点云数据的3个特性:
点云的无序性:点云数据是无序集合,因此网络必须对于场景中的个点的种输入方式,都保持相同的输出。
点间关联:相邻点的局部结构,是有意义的。
平移旋转不变性:全局的点云旋转/平移,不应该改变局部点云的语义。
网络结构
论文中的3个关键结构,分别处理上述点云3个特性:
Max Pooling作为对称方程。公式中表示点数量,表示MLP网络,表示第个点经由MLP网络输出的特征。表示对称方程,也就是Max Pooling操作,取Max操作确保输出于顺序无关,同时输出最显著的特征。作者通过试验确定在这里Max Pooing比Ave Pooing更优。
局部和全局信息的整合模块:所有点云Max Pooing之后为全局特征,把全局特征和之前的局部特征做拼接,以整合局部和全局信息。
T-Net分别对齐输入点云和特征:T-Net用于学习Affine Transformation正交矩阵,第一个T-Net对齐原始点云数据,第二个T-Net对齐64维特征。

VoxelNet
将点云数据用Voxel体素来表征。VoxelNet分成3个部分:
Feature Learning Network
Convulitional Layer
Region Proposal Network
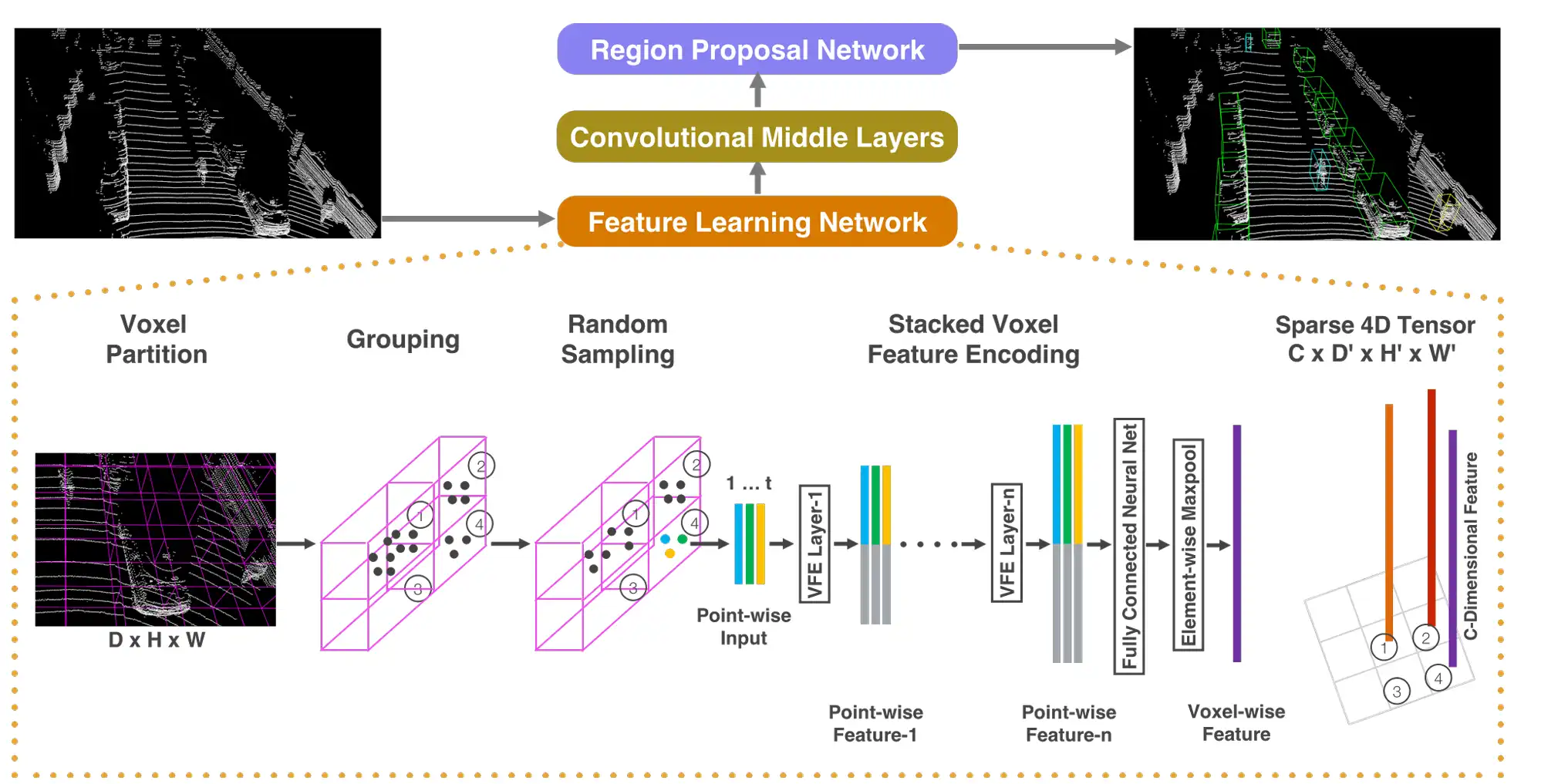
Feature Learning Network

体素分组:在3D空间,按固定尺寸均分,得到规则的Voxel网格,对点云进行分组,分组依据是Voxel的归属。
随机采样:每个Voxel最多T个点,超出则随机采样。
堆叠VFE:堆叠Voxel Feature Encoder,将Voxel内的点转换为统一表征。上图中4号Voxel中有3个点云,使用一个FCN(全连接)提取特征后,得到3个Point-Wise的特征,这里的操作是逐点运算的,属于Local Feature。然后经过一个Max Pooling,得到Local Aggregated Feature即局部聚合特征。两种特征被拼接在一起,目的同时获得点和它周边的特征。
每个体素内的特征包括原始点云的,并计算Voxel所有点的质心。
最终特征被编码为,Dims=7。
VFE输入维度为,其中为点云数量。
Feature表征:经过堆叠VFE,最终Feature被表征为4D的Tensor,,其中为特征维度,为Voxel的数量。
由于LiDAR点云数据分布不规则,超过90%的Voxel是空的,very sparse,但是GPU主要针对Dense Tensor做优化。因此大规模稀疏卷积计算在当时十分费劲。因此在FLN阶段,论文提出了一个Efficient Impl加速策略。
对每个Point计算落在哪个Voxel,得到坐标
构建Hash Table将空间坐标映射到内存中连续的Index。得到的buffer,其中为最大Voxel数,是Voxel中最大点数阈值,7是特征维度。注意这里已经是稠密Tensor了。
K个并行VFE对维的特征进行处理,使用Max Pooling,得到维特征。
根据Hash Table,将特征映射回,最终得到4D Tensor。
这个属于当时的过渡方案,后来出现了PointPillars和Sparse Convolution,就很少被直接使用了。
Convolutional Layer
输入为特征,连续使用3D Conv + BN + ReLU,目的是扩大感受野并聚合Voxel的空间上下文。
最终输出2D Feature Map。
Region Proposal Network

输入为2D Feature,连续4次下采样后,用一个类型FPN的结构,与之前的层拼接在一起。
最后分别用2个1x1的卷积层得到置信度图和回归图。
PointPillars
论文的核心创新点为基于Pillar的快速点云编码器,Pillar就是无限高度的Voxel,相当于简化了Z轴,少了一个维度的特征。
模型的3个主要结构包括:
Pillar Feature Net,借鉴了PointNet。
Backbone,借鉴了VoxelNet。
Head,使用SSD。

Pillar Feature Network
输入是Raw PointCloud,根据XYZ坐标将点云分配到Piilars。特征装饰器最终输出Dims=9的特征。,其中为该点到(所有点而非Pillar)质心的距离,为点到Pillar中心点的offset。
然后得到维度为的特征,其中
D:每个Point的9维特征
P:最大非空Pillar数量
N:每个Pillar中最大Point数量,超阈值随机下采样,不足Zero-Padding
然后借鉴PointNet思想,逐点MLP+MaxPooing,特征升维到,再使用Max Pooling,沿着N轴拍扁得到维度的特征。
由于每个Pillar自带网格HW坐标,转换回去得到了维度的特征,和图像表征方式一致,因此也被叫做伪图像Pseudo image。
Backbone
因为特征已经是的伪图像特征,所以可以使用2D卷积,速度比3D卷积快得多。
使用2D卷积层连续下采样,得到不同分辨率的特征图。不同分辨率的特征图进行不同大小目标的检测,大分辨率的特征图感受野更小,适合捕捉小目标。
然后Deconv上采样,仍然利用类似FPN的结构将特征concat。
小结
可以看出,早期的点云深度学习网络的范式,经历了Point-Based,Voxel-Based,Pillar-Based三个阶段。
PointNet现在已经成为了一种数据特征提取范式。和ResNet相似,不过ResNet用于提取图像特征,PointNet用于提取点云特征。
VoxelNet是体素方法3D目标检测End2End模型的先驱,不过仍然在使用3D卷积,实时性仍然不达标。
PointPillars开创了Pillar级降维的新范式,通过放弃在Z轴上做切分,而是直接将3D空间在X-Y平面做划分,得到的2D伪图像特征,使用2D卷积,速度极快,精度媲美SOTA。至今Pillar-Based范式仍是点云深度网络落地最广的范式。
参考文章
[1] [1612.00593] PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
[2] [1711.06396] VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection
[3] [1812.05784] PointPillars: Fast Encoders for Object Detection from Point Clouds
评论