
先看论文题目
Multi-Camera:多相机纯视觉方案,Camera-based的mAP天然比LiDAR-based和Fusion-based的要低
Spatiotemporal:时间空间
Transformer:用到了Transformer架构以及Attention机制
创新点
论文摆脱了之前LSS那种基于手动设计的Depth先验,而是直接学习BEV特征。
BEVFormer的创新点如下:
网格BEV Query
空间交叉注意力(SCA)
时间自注意力(TSA)
多任务统一框架
Attention Mechanisim
全局注意力:全部像素都参与计算
窗口注意力:解决全局自注意力在高分辨率下计算量爆炸的问题
可形变注意力:不再盯着全图和固定窗口,让网络去找关键采样点
Self-Attention VS Cross-Attention
自注意力:Query (Q)、Key (K)、Value (V) 全部来自同一个序列。寻找输入序列内部的联系。
交叉注意力:Query 来自一个序列,而 Key 和 Value 来自另一个序列。建立两个不同序列之间的联系。
注意力机制自从被提出以后,发展出很多分支,一时难以详细说明。

Structure
BEVFormer有 6 个Encoder。
每个Encoder都遵循Transformer的结构。
多视角的图像特征,也就是Backbone部分,用ResNet-101。
有检测和分割两个Head。

输入数据的格式是6维Tensor:
B: Batch Size
queeu: 连续Frame长度
cam: 相机数量,为6
C/H/W: 图像C/H/W
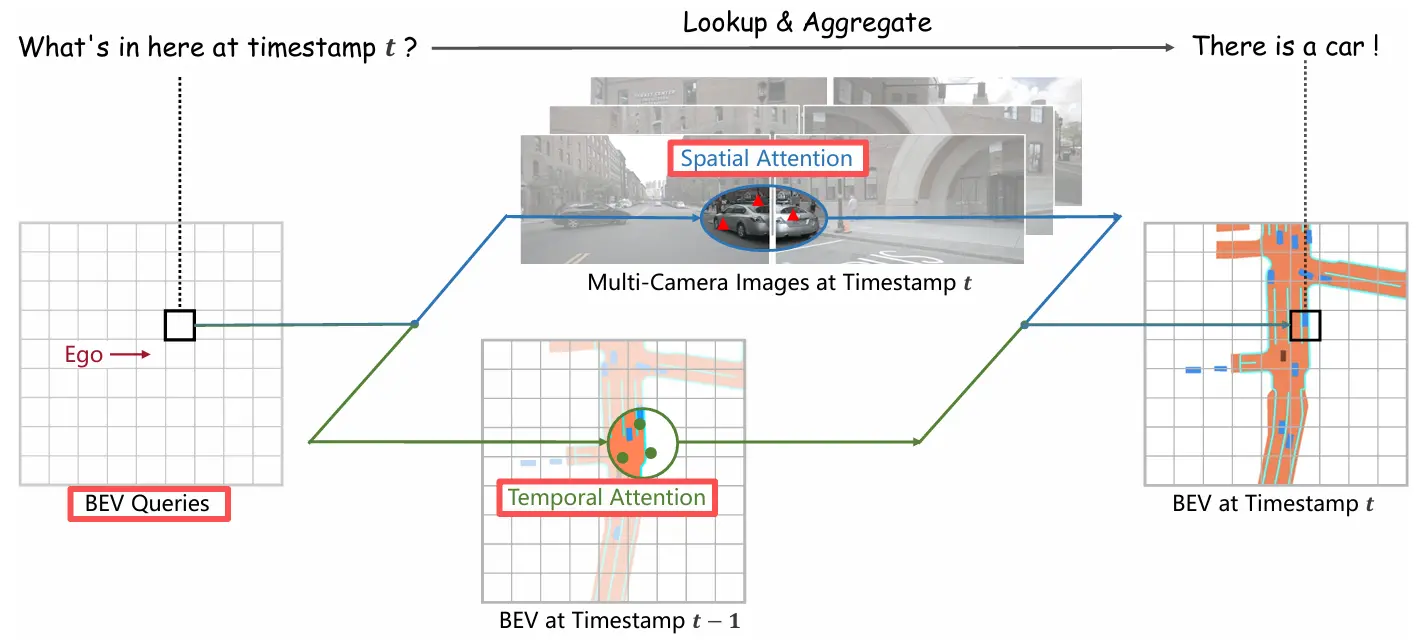
BEV Query
早期的纯视觉感知,是直接从图像中获取3D检测结果。论文发表时更新的感知范式是先提取BEV特征,利用BEV特征输入检测头来获取3D检测结果。BEV中心默认为ego自车位置。
BEVFormer定义了一组的Query Vector,这里的和 是真实尺度即BEV平面的空间型状, 是特征维度。
位于的Query定义为,是一个维度的向量。
Spatial Cross Attention (SCA)
通过BEV Query查询和融合空间信息。这一步主要出于效率的考量,对多个相机图像直接用全局多头注意力会导致计算成本过高。

SCA先确定BEV空间中Query Vector在世界坐标系中的位置。假设一个坐标 处的查询向量,模型会将其映射到以ego为原点的世界坐标系中,这里的H和W是BEV尺寸,s代表网格分辨率。
因为BEV是个2D平面,为了捕捉不同高度的特征,将每个提升为一个Pillar-Like的柱体(有高度限制 ),见上图。SCA预定义了一组Anchor Height,在8米区间内均匀采样出个(4个)点,结合自身就得到个3D参考点。每个就变成了
然后用相机内外参将个3D点投影到2D视图。对于一个,这个参考点只能落在1~2个视图中。这个视图称为,公式中是第个相机的投影矩阵。
SCA会在每个参考点周边区域(周围采样4个点)提取特征,然后对提取到的特征加权求和,作为BEV Query最终输出特征。
Temporal Self Attention (TSA)
TSA借鉴了RNN隐藏状态传递的思想,引入历史Frame () 信息与当前时刻BEV Query融合,可以有效改善遮挡的问题。
给定当前时刻 的 BEV 查询向量 和保存在时刻 的历史 BEV 特征 。由于自车运动,前一帧的网格坐标与当前帧不再重合。TSA 首先根据自车的运动数据(Ego-motion),将 逆向平移和旋转,使其与当前时刻 的坐标系完全对齐,得到对齐后的历史特征 。
自车对齐后,世界坐标系中的目标也在移动,TSA也是利用Deformable Attention在局部区域内动态搜索这些移动的特征 。
对于位于网格位置 的查询向量,TSA 会同时从当前帧的 和对齐后的历史帧 中进行采样特征的融合 ,这里采样偏移量 是通过直接拼接 和 的特征输入进前馈网络来预测的
Head
经过6xTransformer编码器堆叠和提取后,得到统一的 2D BEV 特征张量,送入不同Task Head。
Det
检测任务是E2E的,不依赖Anchor和NMS,直接输出检测结果。
回归参数:
位置:
尺寸:
偏航角:
速度:
Loss Function:
分类:Focal Loss,判断该 Query 对应的区域是否存在物体,以及属于哪种类别
回归:L1 Loss
Seg
查询向量与统一的 BEV 特征 进行常规的多头交叉注意力计算,生成的注意力图(Attention Map)经过解码后,即直接输出对应类别的分割掩码 (Segmentation Mask) 。
参考文章
[1] 【BEV感知】BEVFormer 融合多视角图形的空间特征和时序特征 ECCV 2022-CSDN博客
评论