
当模型可调节参数(自由度)过多时,容易学习到训练数据中的噪声,进而出现过拟合(训练集误差小、测试集误差大)。因此要对模型的参数引入某种限制,在训练过程中避免过拟合。
正则化通过在损失函数中加入参数惩罚项,约束参数规模,迫使模型优先学习数据的通用规律,而非噪声。
范数
在正式进入正则化的学习之前,先了解一下范数的概念。
范数的本质是对距离的抽象推广,一个函数 \|\cdot\| 是范数,必须满足以下条件:
- 非负性:\|\mathbf{x}\| \geq 0
- 零向量特征:\|\mathbf{x}\| = 0 \iff \mathbf{x} = \mathbf{0}(\mathbf{0} 为零向量)
- 正齐次性:\|\alpha \mathbf{x}\| = |\alpha| \cdot \|\mathbf{x}\|
- 三角不等式:\|\mathbf{x} + \mathbf{y}\| \leq \|\mathbf{x}\| + \|\mathbf{y}\|
向量范数中 L_p 范数最为常见,定义为:
最常见的几种 L_p 范数有:
- L1 范数,对应曼哈顿距离,是向量各个分量绝对值的和
- L2 范数,对应欧几里得距离,是向量各分量平方和的平方根。L2 范数应用最广,如果直接省略下标变成 \|x\| 的形式,一般是指 L2 范数
- L_\infty 范数,对应切比雪夫距离,是向量各分量绝对值的最大值
- L0 范数,严格意义上不符合范数定义,所以应该叫 L0 伪范数,定义为向量中非零元素的个数
其中 \mathbb{I}(\cdot) 为指示函数,当 x_i \neq 0 时,\mathbb{I}(x_i \neq 0) = 1,否则为 0。
正则化方法
常见的正则化方法:
- Ridge Regression,也被称作 L2 Regression,通常作为默认的正则化手段使用
- Lasso Regression,也被称作 L1 Regression
- Elastic Net
上述正则化方法,都有一个正则项(regularization term)被添加到 cost function 中。
L2 Ridge Regression
在原有损失函数的基础上,加入参数的平方和惩罚项,惩罚项系数 \alpha 为正则强度。
cost function 就变成了:
其中 p 为特征权重数量,偏置项 \theta_0 通常不参与惩罚。
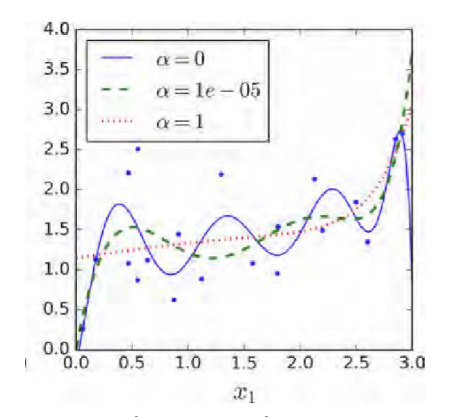
Figure 1 多项式拟合加 L2 正则化
最小化损失函数时,正则项的存在要求参数 \theta 的 L2 范数越低越好,从而会限制其复杂度。因为 L2 范数的计算方式是向量所有元素的平方和相加,可以用于形容参数向量整体大小或复杂度,L2 范数越大,某些参数的绝对值越大,会导致模型过于依赖这些参数。核心逻辑就是压缩无用参数,降低模型复杂度。
可以看出 \alpha 越大,拟合的曲线越平滑,因为 \alpha 对高维惩罚更严重;反之 \alpha 越小,曲线会更弯曲。
L1 LASSO Regression (Least Absolute Shrinkage and Selection Operator Regression)
正则项为参数的绝对值之和,cost function 为:
其中 p 为特征权重数量,偏置项 \theta_0 通常不参与惩罚。
通过更激进的收缩方式:在最小化损失函数时,L1 正则项会让不重要的参数被直接压缩为 0,最终仅得到稀疏的参数向量,少量关键特征被保留。
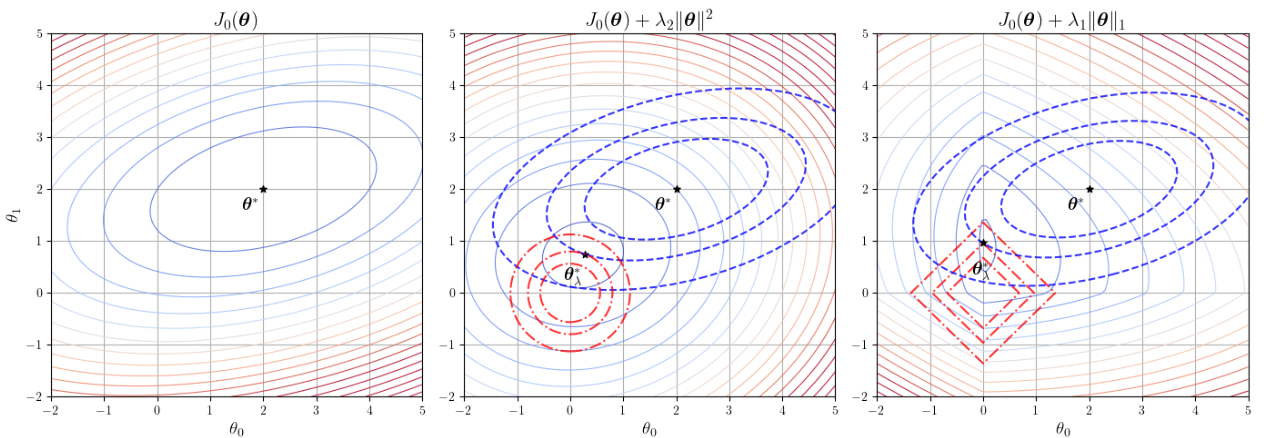
Figure 2 L2 & L1 正则化约束对比
关于两种正则化形状的解释,注意一个前提,上图是在二维空间。
L1 正则化:是权重向量各分量的绝对值之和,在二维情况下,权重向量为 w = (w_1, w_2),L1 正则项是 |w_1| + |w_2| = c。
当 w_1 \geq 0, w_2 \geq 0 时,方程为 w_1 + w_2 = c
当 w_1 \geq 0, w_2 \leq 0 时,方程为 w_1 - w_2 = c
当 w_1 \leq 0, w_2 \geq 0 时,方程为 -w_1 + w_2 = c
当 w_1 \leq 0, w_2 \leq 0 时,方程为 -w_1 - w_2 = c
这四条直线构成了一个菱形,4 个顶点分别为 (c, 0)、(0, c)、(-c, 0)、(0, -c)。损失函数的等高线(通常为椭圆形)与 L1 正则化约束区域(菱形)的交点更容易出现在顶点上,对应权重向量中有 0 出现的情况。
L2 正则化:是参数平方和的平方根,在二维情况下,表示为 \sqrt{w_1^2 + w_2^2} = c,平方后(等价的),在二维平面上就是圆的标准方程。损失函数的等高线与圆的交点更可能出现在圆周上,而不是在坐标轴上,因此不太可能出现权重向量中有 0 的情况。
至于为什么要找交点,回顾一下我们的优化目标,是最小化损失函数 + 正则项这个函数,可以理解为在满足正则化约束(正则项看成一个给定容量的可行域)条件下,找到使损失函数最小的参数向量 w。损失函数等高线表示损失函数值相同的 w,正则化区域边界表示 \|w\|_p = c 点的集合。
协助理解 L1 和 L2 正则化的模式
理解为行李装箱:
- L1 正则化:强制丢弃不重要的物品,只保留最关键的物品
- L2 正则化:压缩所有物品的尺寸,但不会丢弃物品
L1+L2 Elastic Net Regression
这种方法介于 L1 和 L2 之间。\alpha 控制正则化强度,r \in [0, 1] 控制 L1 与 L2 的混合比例。若 \alpha 极大,所有特征权重 \theta_j 将被压至 0,模型退化为仅由偏置项决定的常数预测。
模型的选择
- Ridge 一般作为默认选项
- 若特征较多,但是有用的较少,可以选择 LASSO 或者 Elastic
- 特征高度相关或特征数 > 样本数时,Elastic Net 通常优于 LASSO,因为 L2 项能稳定相关特征的系数
- 若特征数量 > 训练实例数,选择 Elastic Net
欠拟合与过拟合
训练损失和测试损失都较大,为欠拟合(underfitting)。
训练损失小而测试损失较大,为过拟合(overfitting)。
欠拟合
模型无法拟合数据中的重要模式,模式就是数据背后的规律。
欠拟合会导致预测精度低。
造成欠拟合的因素包括:
- 模型复杂度太低,不具备学习复杂模式的能力
- 迭代次数太少,没来得及学习数据的模式
- 学习率太低,参数更新太慢或不充分
解决欠拟合的方法:
- 提高模型复杂度,能够学习更复杂的模式
- 增加迭代次数,欠拟合的训练和测试损失均未收敛,说明模型尚未完全学习数据中的重要模式,增加训练次数可以让模型充分拟合
- 提高学习率,理由同上
过拟合
过度拟合了训练集数据中不具备普遍性的部分,在未观测到的数据中,预测效果会变差。
造成过拟合的因素包括:
- 模型复杂度太高,导致训练损失小,但是预测损失大
- 训练集的数据太少
- 训练集噪声太多
解决过拟合的方法:
- 筛选特征,如 PCA
- 正则化约束
- Dropout Layer
- 数据增强,以及增加数据量
- Early Stop
- Ensemble Learning
- 交叉验证
交叉验证 Cross Validation
在训练过程中,一般划分为 Training Set 和 Test Set,但是 Test Set 对于训练过程来说是未知的,因此常常采取人为构造 Test Set 的方法,划分出一部分 Validation Set。Validation 用于模型选择和调参,不用于最终评估。
Validation Set 不参与任何模型参数的更新,也就是说模型在训练过程中不应该用到任何 Validation Set 中的数据信息。如果 Test Set 和 Validation Set 的数据分布相同,那么可以认为二者是等效的。
与 Test Set 的区别见下表:
| 特性 | 验证集 | 测试集 |
|---|---|---|
| 作用 | 模型选择和调参 | 最终模型评估 |
| 使用频率 | 多次使用 | 仅使用一次 |
| 数据参与 | 不参与参数更新 | 完全不参与训练 |
| 评估目的 | 选择最佳模型 | 评估模型在真实场景的表现 |
要注意的是,虽然训练时不会用到 Validation Set 中的信息,但是如果预处理时用到了 Training Set 和 Validation Set 的共同统计信息,那么 Validation Set 的信息就可以泄露到模型,模型就学到了 Training Set 以外的信息。因此如果要对数据进行预处理,最好是先划分 Set。
在划分不同 Set 时,常采用随机划分的方式,常用的是交叉验证。
K 折交叉验证 K-Fold Cross Validation
将数据集随机划分为 K 个大小相等的子集,称为 Fold,每次使用 K-1 个子集作为 Training Set,剩余的 1 个子集作为 Validation Set。重复 K 次,每次使用不同的子集作为 Validation Set,最终取 K 次验证结果的平均值作为模型性能的估计。
数据集 → [1][2][3][4][5](K=5)
第1轮:训练集[2][3][4][5],验证集[1]
第2轮:训练集[1][3][4][5],验证集[2]
第3轮:训练集[1][2][4][5],验证集[3]
第4轮:训练集[1][2][3][5],验证集[4]
第5轮:训练集[1][2][3][4],验证集[5]
留一验证 Leave One Out Cross Validation
K-Fold 的极端情况,其中 K 等于数据集大小。每次只留一个样本作为 Validation Set,其余所有样本作为 Training Set。也就是说需要训练 n 次模型,n 为样本数。
分层 K 折交叉验证 Stratified K-Fold Cross Validation
在 K 折交叉验证的基础上,保证每个 Fold 中各类别样本的比例与原始数据集中的比例一致。特别适用于类别不平衡的数据集。
原始数据集:正类60%,负类40%
K=5的分层K折:
折1:正类60%,负类40%
折2:正类60%,负类40%
...
折5:正类60%,负类40%
优化器 Optimisers
优化器根据损失函数的梯度更新模型参数,不同算法在收敛速度、稳定性和内存开销上各有取舍。
SGD (Stochastic Gradient Descent)
每次用单个样本或小批量(mini-batch)估计梯度并更新参数,是深度学习中最基础的优化方法:
Momentum
在 SGD 基础上引入动量项,累积历史梯度方向以加速收敛并抑制震荡:
AdaGrad
为每个参数维护自适应学习率,频繁更新的参数学习率自动减小,适合稀疏特征;但学习率会持续衰减,长期训练可能过早停止。
RMSprop
用梯度平方的移动平均归一化更新步长,缓解 AdaGrad 学习率单调递减的问题,在 RNN 等场景中表现稳定。
Adam (Adaptive Moment Estimation)
结合 Momentum 的一阶矩估计与 RMSprop 的二阶矩估计,为每个参数计算自适应学习率,收敛快、超参数不敏感,是目前深度学习的默认选择之一。
评论